作者: | 来源:互联网 | 2023-08-28 12:14

1.hadoop介绍
hadoop在大数据技术体系中的地位至关重要,hadoop是大数据技术的基础,对hadoop基础知识的掌握的扎实程度,会决定在大数据技术道路上走多远。hadoop是一个能够对海量数据进行分布式处理的系统架构,框架的核心是:HDFS和MapReduce。HDFS分布式文件系统为海量的数据提供了存储,MapReduce分布式处理框架为海量的数据提供了计算。
hadoop有三大安装模式:
1>hadoop本地模式安装
hadoop本地模式只是用于本地开发调试,或者快速安装体验hadoop,这部分做简单的介绍。
2>hadoop伪分布式模式安装
学习hadoop一般是在伪分布式模式下进行,这种模式是在一台机器上各个进程上运行hadoop的各个模块,伪分布式的意思是虽然各个模块是在各个进程上分开运行的,但是只是运行在一个操作系统上的,并不是真正的分布式。
3>hadoop完全分布式安装
完全分布式模式才是生产环境采用的模式,hadoop运行在服务器集群上,生产环境一般都会做HA,以实现高可用。
2.安装环境
jdk:1.8
hadoop:3.1.2(注意版本号,不同版本,部署略有差异)
3.单机部署
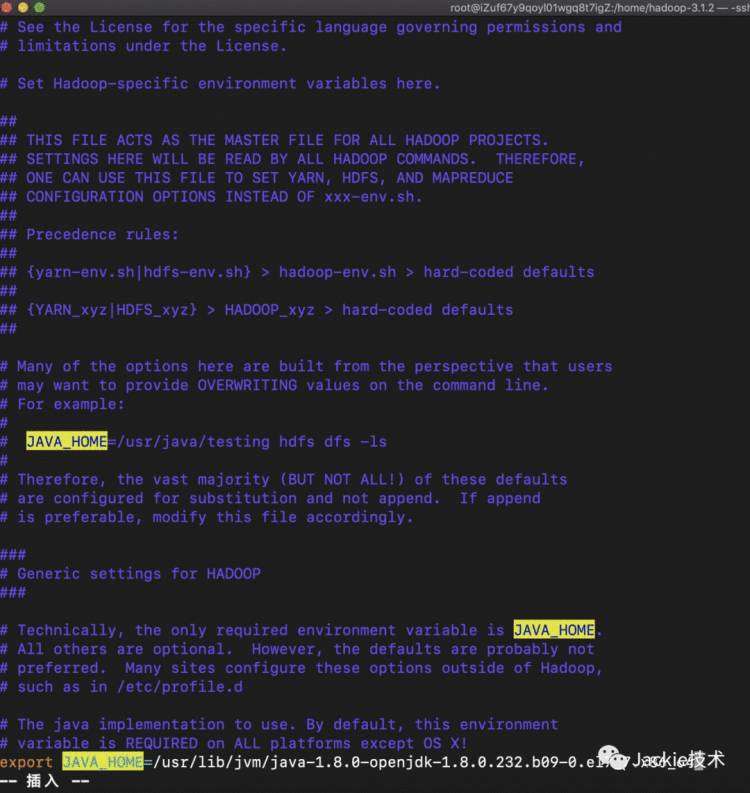
1>解压,配置JAVA_HOME
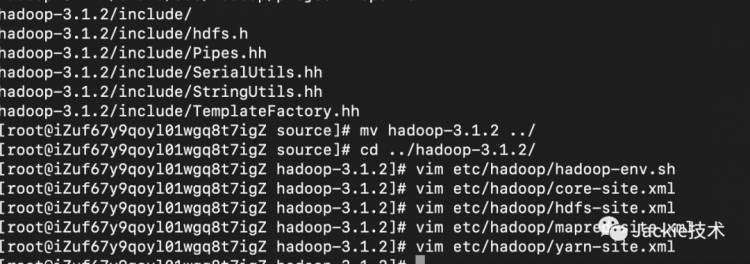
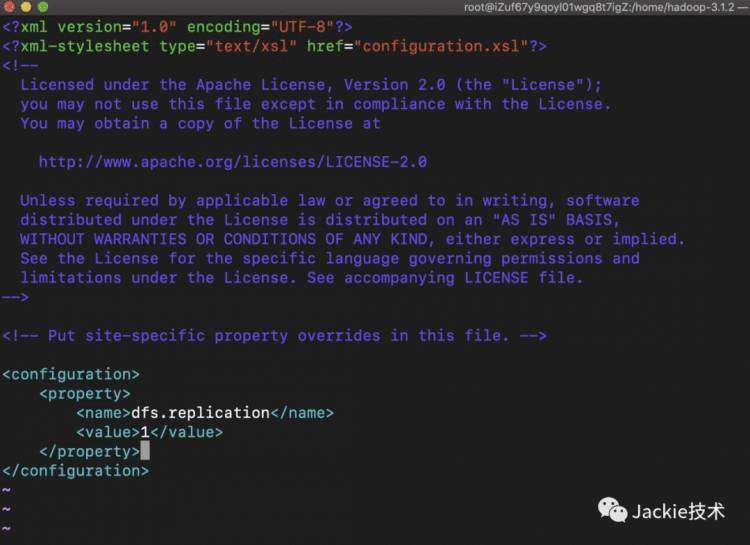
2>修改配置文件

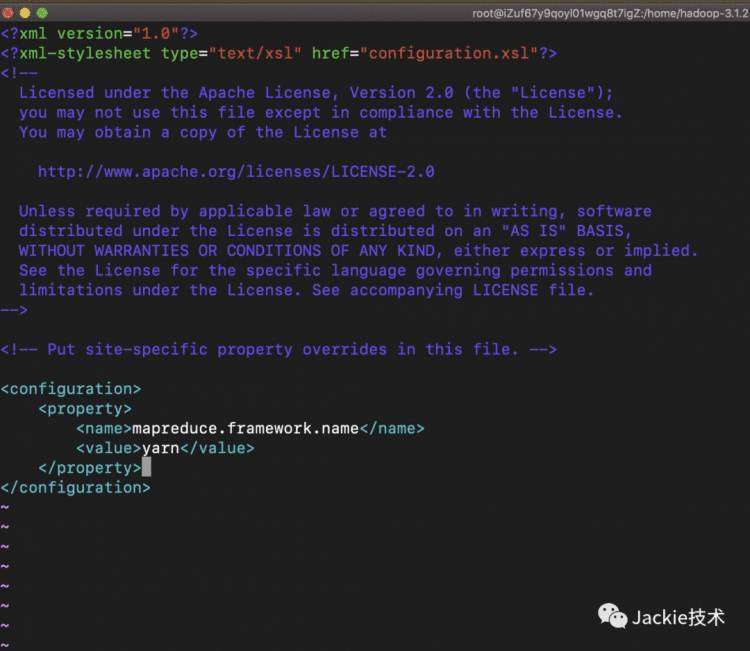
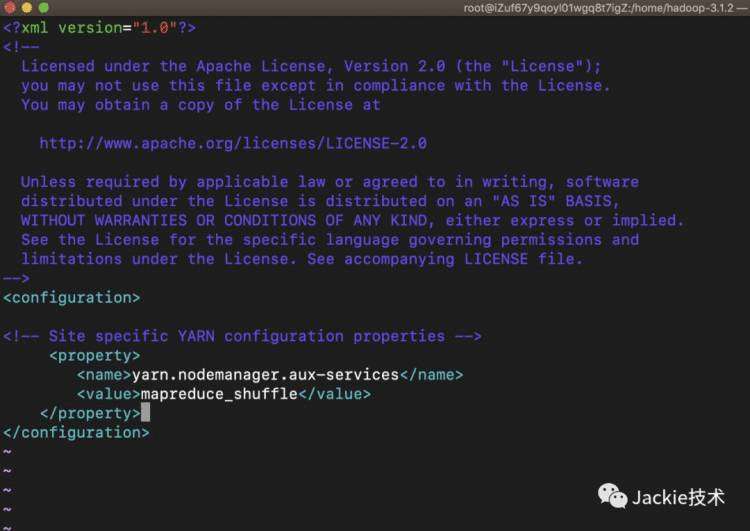
3>修改执行脚本文件

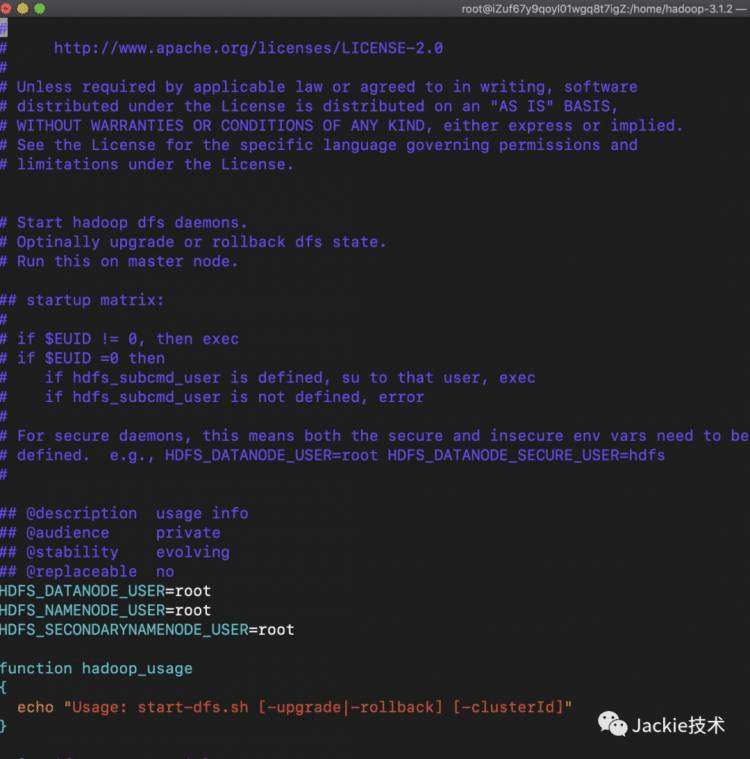
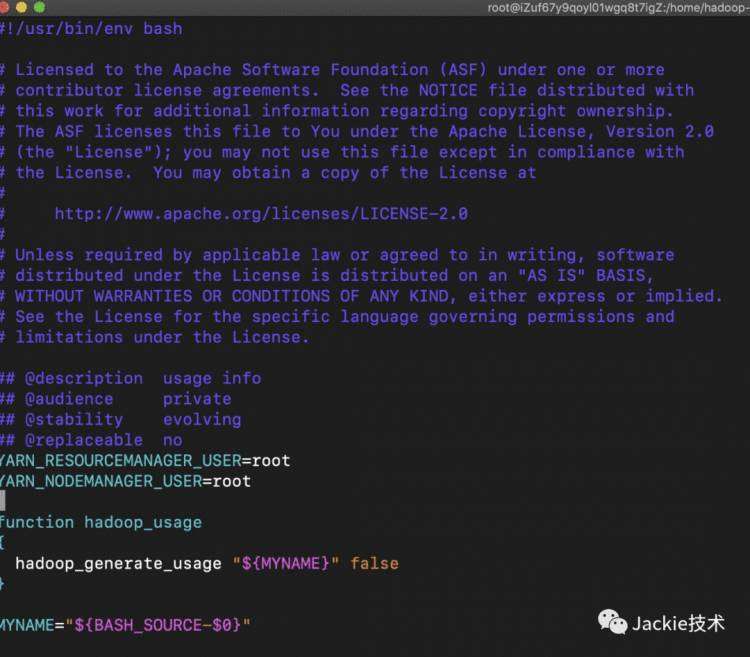
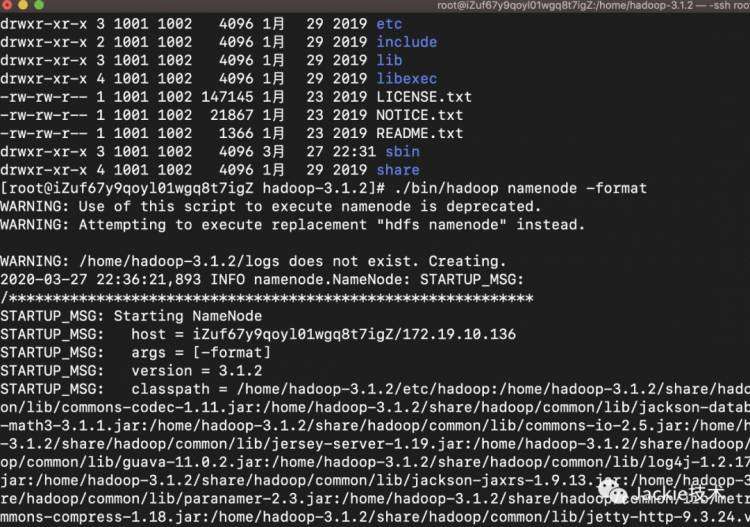
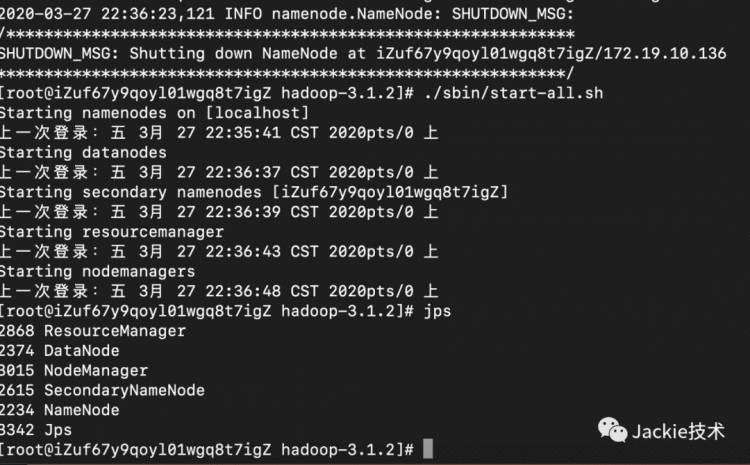
4>格式化文件系统,启动hadoop,验证是否启动成功
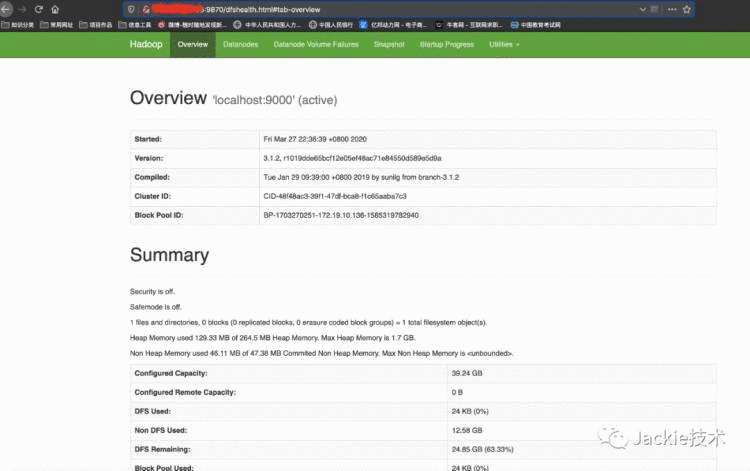
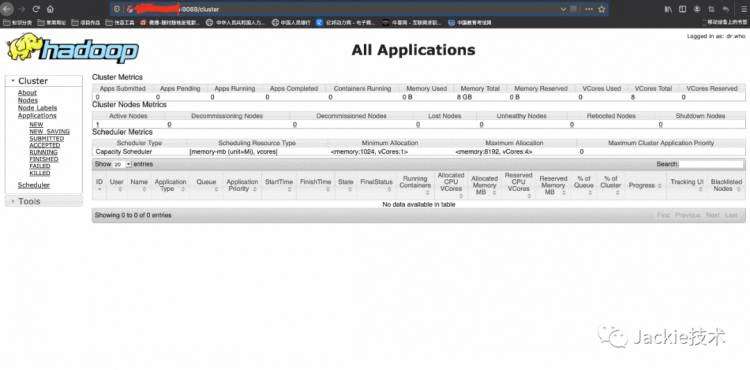
5>访问页面http://localhost:9870和页面http://localhost:8088
4.参考资料
https://hadoop.apache.org/docs/r3.1.2/hadoop-project-dist/hadoop-common/SingleCluster.html
本集部署的主题将告一段落,下集部署的主题将更加精彩,若您对主题感兴趣,请关注我们的微信公众号,将及时获取最新的资讯,每天成长一点点,快乐每一天!










 京公网安备 11010802041100号
京公网安备 11010802041100号