这几年,大数据发展迅猛,其中 Kakfa 凭借高可靠、高吞吐、高可用、可伸缩几大特性,成为数据管道技术的首选。
越来越多人开始使用 Kafka,对学习源码的需求也愈发强烈,原因主要有这么几个方面:
- 了解 Kafka 底层原理,从而搞懂 Kafka 高性能的实现机制;
- 快速分析定位线上问题,有针对性地制定调优方案,提升编码功力;
- Kafka 的很多优秀设计理念和特性,在官方文档中并未得到充分阐述;
- 很多互联网公司在招聘资深技术岗时,都要求“至少读过一种开源框架的源码”;
- 加入 Kafka 开源社区,成为一名代码贡献者——一旦你的代码被社区采纳,全世界 Kafka 使用者都会用你写的代码。
但我发现,大部分人在读源码时,还是会遇到很多问题,比如:源码这么多,不知道该重点掌握哪些内容;读源码时缺乏科学的方法,无数次从入门到放弃;知识不够体系化,遇到底层原理等常见面试题,很难有良好表现等等。
其实,阅读源码并不难,重点是掌握科学的方法——用最高效的方式,读最核心的源码。
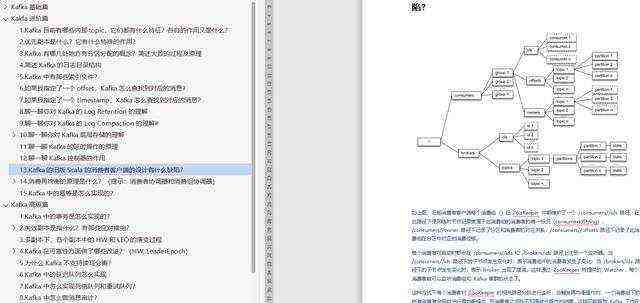
如何学习Kafka源码?
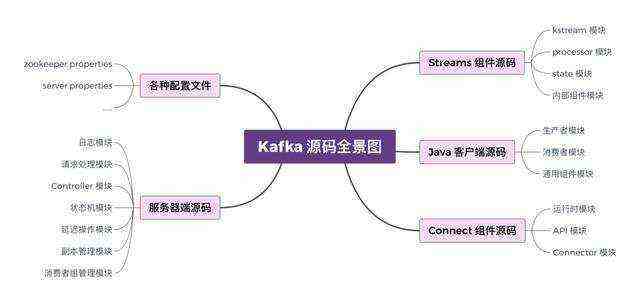
在这之前,分享一张 Kafka 源码全景图,梳理学习重点,找到最核心的源码。
同时分享一份Kafka源码解析与实战笔记,分为10个模块。其中将从Kafka的内部实现原理、运维工具、客户端编程以及实际应用这四个方面出发,系统阐述有关Kafka的各方面知识,每个模块的大致内容如下。
第一模块:讲了Kafka诞生的背景、Kafka在LinkedIn内部的应用、Kafka 的主要设计目标以及为什么使用消息系统。
第二模块:讲了Kafka的基本组成、拓扑结构及其内部的通信协议。
第三模块:描述Kafka集群组成的基本元素Broker Server的启动以及内部的模块组成。
第四模块:描述Broker Server内部的九大基本模块: SocketServer 、KafkaRequestHandlerPool 、LogManager、ReplicaManager 、OffsetManager、KafkaScheduler. KafkaApis 、KafkaHalthcheck和TopicConfigManager
第五模块:介绍BrokerServer的控制管理模块KafkaController,这个模块负责整个Kafka集群的管理,例如:Topic的新建和删除.分区状态和副本状态的转换、集群的负载均衡管理等。
第六模块:介绍三个维护脚本: kafka-topics.sh 、kafka-reassign-partitions.sh 和kafka preferred
replica-election.sh,它们分别涉及Topic的生命周期管理、Topic分区的重分配和分区首选副本的选择。
第七模块:从设计原则、示例代码、模块组成和发送模式四个部分介绍有关消息生产者的相关知识,从设计原则至客户端编程,从客户端编程到内部实现原理,由浅人深,循序渐进地讲解。
第八模块:分别介绍两种消费者:简单消费者和高级消费者。针对每种消费者都将依次从设计原则、消费者流程、示例代码以及原理解析四个部分介绍消费者的相关知识。
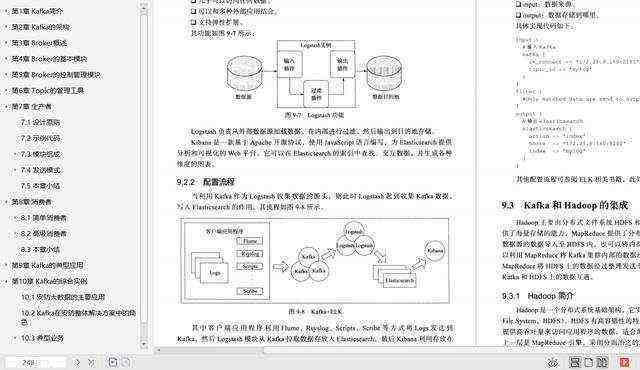
第九模块:介绍Kafka与典型大数据系统的集成,包括: Kafka和Storm的集成、Kafka 和ELK的集成、Kafka和Hadoop的集成以及Kafka和Spark的集成。
第十模块:用综合实例描述了Kafka的应用,案例描述Kafka作为数据总线在安防整体解决方案中的作用,通过车辆人脸图片数据的入库、视频数据的入库、数据延时的监控、数据质量的监控、布控统计和容灾备份6个业务,简要阐述内部的实现原理。
由于篇幅限制,小编这里只将此实战文档的所含内容全部展现出来了,需要获取完整文档用以学习的朋友麻烦转发后来我主页私信:【文档】获取免费领取方式!
阿里等大型互联网公司Kafka面试高频问题解析
- 简述Kafka的日志目录结构
- Kafka中有那些索引|文件?
- 如果我指定了一个offset, Kafka 怎么查找到对应的消息?
- 如果我指定了一个timestamp, Kafka 怎么查找到对应的消息?
- 你对Kafka的Log Retention的理解
- 你对Kafka的Log Compaction的理解#
- 你对Kafka底层存储的理解
- Kafka的延时操作的原理
- Kafka控制器的作用
- Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
- 。。。
由于篇幅限制,小编这里将这些Kafka面试解析整理成文档了,需要获取完整文档用以学习的朋友麻烦转发后来我主页私信:【文档】获取免费领取方式!











 京公网安备 11010802041100号
京公网安备 11010802041100号