作者:mobiledu2502852923 | 来源:互联网 | 2023-08-07 11:37
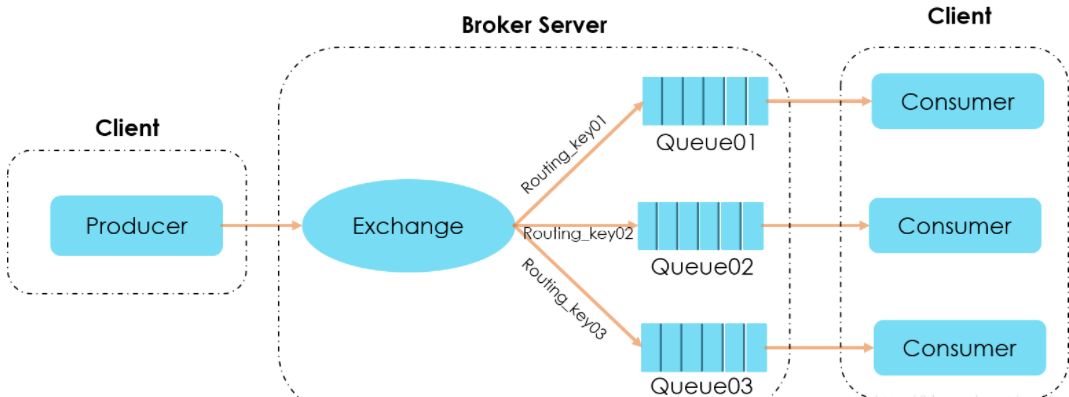
对于消费者模式,在一般应用中可以使用阻塞队列+线程池来实现。比如说在一个应用中,A方法调用B方法去执行一些任务处理。我们可以同步调用。但是 如果这个时候请求比较多的情况下,同步调用比较耗时会导致请求阻塞。我们会使用阻塞队列加线程池 来实现异步任务的处理。
那么,问题来了,如果是在分布式系统中,两个服务之间需要通过这种异步队列的方式来处理任务,那 单进程级别的队列就无法解决这个问题了。 因此,引入了消息中间件,也就是把消息处理交给第三方的服务,这个服务能够实现数据的存储以及传 输,使得在分布式架构下实现跨进程的远程消息通信。
所以,简单来说: 消息中间件是指利用高效可靠的消息传输机制进行平台无关的数据交流,并且基于数 据通信来进行分布式系统的集成。
我们每学习一个东西,更应该去学会如何设计实现?同样道理,如果要设计一种消息中间件需要怎么去设计实现?
可以先从基本的需求开始思考 :
1、最基本的是要能支持消息的发送和接收,需要涉及到网络通信就一定会涉及到NIO
2、消息中心的消息存储(持久化/非持久化)
3、 消息的序列化和反序列化
4、是否跨语言
5、消息的确认机制,如何避免消息重发
高级功能
1、 消息的有序性
2、是否支持事务消息
3、消息收发的性能,对高并发大数据量的支持
4、是否支持集群
5、消息的可靠性存储
6、是否支持多协议
这个思考的过程其实就是做需求的整理,然后在使用已有的技术体系进行技术的实现。而我们目前阶 段所去了解的,无非就是别人根据实际需求进行实现之后,我们如何使用他们提供的api进行应用而 已。但是有了这样一个全局的思考,那么对于后续学习这个技术本身而言,也显得很容易了。
发展过程:
实际上消息中间件的发展也是挺有意思的,我们知道任何一个技术的出现都是为了解决实际问题,这个 问题是 通过一种通用的软件“总线”也就是一种通信系统,解决应用程序之间繁重的信息通信工作。最早 的小白鼠就是金融交易领域,因为在当时这个领域中,交易员需要通过不同的终端完成交易,每台终端 显示不同的信息。如果接入消息总线,那么交易员只需要在一台终端上操作,然后订阅其他终端感兴趣 的消息。于是就诞生了发布订阅模型(pubsub),同时诞生了世界上第一个现代消息队列软件(TIB) The information Bus, TIB允许开发者建立一系列规则去描述消息内容,只要消息按照这些规则发布出 去,任何消费者应用都能订阅感兴趣的消息。随着TIB带来的甜头被广泛应用在各大领域,IBM也开始研 究开发自己的消息中间件,3年后IBM的消息队列IBM MQ产品系列发布,之后的一段时间MQ系列进化 成了WebSphere MQ统治商业消息队列平台市场。
包括后期微软也研发了自己的消息队列(MSMQ)
各大厂商纷纷研究自己的MQ,但是他们是以商业化模式运营自己的MQ软件,商业MQ想要解决的是应 用互通的问题,而不是创建标准接口来允许不同MQ产品互通。所以有些大型的金融公司可能会使用来 自多个供应商的MQ产品,来服务企业内部不同的应用。那么问题来了,如果应用已经订阅了TIB MQ的 消息然后突然需要消费IBM MQ的消息,那么整个实现过程会很麻烦。为了解决这个问题,在2001年诞 生了 Java Message Service(JMS),JMS通过提供公共的Java API方式,隐藏单独MQ产品供应商的实现 接口,从而跨越了不同MQ消费和解决互通问题。从技术层面来说,Java应用程序只需要针对JMS API编 程,选择合适的MQ驱动即可。JMS会处理其他部分。这种方案实际上是通过单独标准化接口来整合很 多不同的接口,效果还是不错的,但是碰到了互用性的问题。两套使用两种不同编程语言的程序如何通 过它们的异步消息传递机制相互通信呢。这个时候就需要定义一个异步消息传递的通用标准
所以AMQP(Advanced Message Queuing Protocol)高级消息队列协议产生了,它使用了一套标准 的底层协议,加入了许多其他特征来支持互用性,为现代应用丰富了消息传递需求,针对标准编码的任 何人都可以和任意AMQP供应商提供的MQ服务器进行交互。
除了JMS和AMQP规范以外,还有一种MQTT(Message Queueing Telemetry[特莱米缺] Transport),它是专门为小设备设计的。因为计算性能不高的设备不能适应AMQP上的复杂操作,它 们需要一种简单而且可互用的方式进行通信。这是MQTT的基本要求,而如今,MQTT是物联网(IOT) 生态系统中主要成分之一
今天要讲解的Kafka,它并没有遵循上面所说的协议规范,注重吞吐量,类似udp 和 tcp
kafka的介绍(基于2.0版本)
什么是Kafka
Kafka是一款分布式消息发布和订阅系统,它的特点是高性能、高吞吐量。
最早设计的目的是作为LinkedIn的活动流和运营数据的处理管道。这些数据主要是用来对用户做用户画 像分析以及服务器性能数据的一些监控 所以kafka一开始设计的目标就是作为一个分布式、高吞吐量的消息系统,所以适合运用在大数据传输 场景。
所以kafka在我们大数据的课程里面也有讲解,但是在Java的课程中,我们仍然主要是讲解kafka 作为分布式消息中间件来讲解。不会去讲解到数据流的处理这块
Kafka的应用场景
由于kafka具有更好的吞吐量、内置分区、冗余及容错性的优点(kafka每秒可以处理几十万消息),让 kafka成为了一个很好的大规模消息处理应用的解决方案。所以在企业级应用长,主要会应用于如下几 个方面:
1、行为跟踪:kafka可以用于跟踪用户浏览页面、搜索及其他行为。通过发布-订阅模式实时记录到对应的 topic中,通过后端大数据平台接入处理分析,并做更进一步的实时处理和监控
2、日志收集:日志收集方面,有很多比较优秀的产品,比如Apache Flume,很多公司使用kafka代理日志 聚合。日志聚合表示从服务器上收集日志文件,然后放到一个集中的平台(文件服务器)进行处理。在 实际应用开发中,我们应用程序的log都会输出到本地的磁盘上,排查问题的话通过linux命令来搞定, 如果应用程序组成了负载均衡集群,并且集群的机器有几十台以上,那么想通过日志快速定位到问题, 就是很麻烦的事情了。所以一般都会做一个日志统一收集平台管理log日志用来快速查询重要应用的问 题。所以很多公司的套路都是把应用日志集中到kafka上,然后分别导入到es和hdfs上,用来做实时检 索分析和离线统计数据备份等。而另一方面,kafka本身又提供了很好的api来集成日志并且做日志收集

Kafka本身的架构
一个典型的kafka集群包含若干Producer(可以是应用节点产生的消息,也可以是通过Flume收集日志 产生的事件),若干个Broker(kafka支持水平扩展)、若干个Consumer Group,以及一个 zookeeper集群。kafka通过zookeeper管理集群配置及服务协同。Producer使用push模式将消息发布 到broker,consumer通过监听使用pull模式从broker订阅并消费消息。
多个broker协同工作,producer和consumer部署在各个业务逻辑中。三者通过zookeeper管理协调请 求和转发。这样就组成了一个高性能的分布式消息发布和订阅系统。
图上有一个细节是和其他mq中间件不同的点,producer 发送消息到broker的过程是push,而 consumer从broker消费消息的过程是pull,主动去拉数据。而不是broker把数据主动发送给consumer。

名词解释
1)Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。broker端不维护数据的消费状态,提升 了性能。直接使用磁盘进行存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制, 减少耗性能的创建对象和垃圾回收。
2)Producer
负责发布消息到Kafka broker
3)Consumer
消息消费者,向Kafka broker读取消息的客户端,consumer从broker拉取(pull)数据并进行处理。
4)Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存 储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消 费数据而不必关心数据存于何处)
5)Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.
6)Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定 group name则属于默认的group)
7)Topic & Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把 这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个 Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文 件。若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个 文件夹(本文所用集群共8个节点,此处topic1和topic2 replication-factor均为1)。
Kafka的安装部署
单机部署docker:https://blog.csdn.net/qq_16563637/article/details/81701445?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param
一、单机:
下载kafka https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
安装过程
安装过程非常简单,只需要解压就行,因为这个是编译好之后的可执行程序 tar -zxvf kafka_2.11-2.0.0.tgz 解压
配置zookeeper
因为kafka依赖于zookeeper来做master选举一起其他数据的维护,所以需要先启动zookeeper节点 ,kafka内置了zookeeper的服务,所以在bin目录下提供了这些脚本。
zookeeper-server-start.sh zookeeper-server-stop.sh
在config目录下,存在一些配置文件:
zookeeper.properties server.properties
所以我们可以通过下面的脚本来启动zk服务,当然,也可以自己搭建zk的集群来实现
sh zookeeper-server-start.sh -daemon ../config/zookeeper.properties
启动和停止kafka
修改server.properties, 增加zookeeper的配置
zookeeper.connect=localhost:2181
启动kafka
sh kafka-server-start.sh -damoen config/server.properties
停止kafka
sh kafka-server-stop.sh -daemon config/server.properties
kafka的基本操作
创建topic:
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --
partitions 1 --topic test
Replication-factor 表示该topic需要在不同的broker中保存几份,这里设置成1,表示在两个broker中 保存两份 Partitions 分区数
查看topic:
sh kafka-topics.sh --list --zookeeper localhost:2181
查看topic属性
sh kafka-topics.sh --describe --zookeeper localhost:2181 --topic first_topic
消费消息
sh kafka-console-consumer.sh --bootstrap-server 192.168.13.106:9092 --topic test
--from-beginning
发送消息
sh kafka-console-producer.sh --broker-list 192.168.244.128:9092 --topic
first_topic
集群环境安装
一、普通部署:
https://blog.csdn.net/xuesp/article/details/88094326(用的是kafka自带的zk脚本)
二、docker部署:
1、https://blog.csdn.net/weixin_42831855/article/details/91980398(standlone模式)(使用docker-compose)(自己部署的zk)
2、https://www.jianshu.com/p/630381fcb078(没用docker-compose,使用自带的zk)
3、https://blog.csdn.net/yjp19871013/article/details/105165972/
https://www.jianshu.com/p/1ebaa1b12688(没用docker-compose,自己部署zk)











 京公网安备 11010802041100号
京公网安备 11010802041100号