作者:子木
转发链接:segmentfault.com/a/1190000015052545
关于 性能优化 是个大的面,这篇文章主要涉及到 前端 的几个点,如 前端性能优化 的流程、常见技术手段、工具等。
提及 前端性能优化 ,大家应该都会想到 雅虎军规,本文会结合 雅虎军规 融入自己的了解知识,进行的总结和梳理 。
首先,我们先来看看“雅虎军规”的35条:
如对 雅虎军规 的具体细则内容不是很了解,可自行访问这篇优质文章:前端性能优化之雅虎35条军规 了解详情。
对于 前端性能优化 自然要关注 首屏 打开速度,而这个速度,很大因素是花费在网络请求上,那么怎么减少网络请求的时间呢?
所以压缩、合并就是一个解决方案,当然可以用 gulp 、 webpack 、 grunt 等构建工具压缩、合并。
例如:gulp js、css 压缩、合并代码如下 :
//压缩、合并jsgulp.task('scripts', function () { return gulp.src([ './public/lib/fastclick/lib/fastclick.min.js', './public/lib/jquery_lazyload/jquery.lazyload.js', './public/lib/velocity/velocity.min.js', './public/lib/velocity/velocity.ui.min.js', './public/lib/fancybox/source/jquery.fancybox.pack.js', './public/js/src/utils.js', './public/js/src/motion.js', './public/js/src/scrollspy.js', './public/js/src/post-details.js', './public/js/src/bootstrap.js', './public/js/src/push.js', './public/live2dw/js/perTips.js', './public/live2dw/lib/L2Dwidget.min.js', './public/js/src/love.js', './public/js/src/busuanzi.pure.mini.js', './public/js/src/activate-power-mode.js' ]).pipe(concat('all.js')).pipe(minify()).pipe(gulp.dest('./public/dist/'));});// 压缩、合并 CSSgulp.task('css', function () { return gulp.src([ './public/lib/font-awesome/css/font-awesome.min.css', './public/lib/fancybox/source/jquery.fancybox.css', './public/css/main.css', './public/css/lib.css', './public/live2dw/css/perTips.css' ]).pipe(concat('all.css')).pipe(minify()).pipe(gulp.dest('./public/dist/'));});
然后,再把 压缩、合并 的 JS、CSS 放入 CDN,看看效果如何:
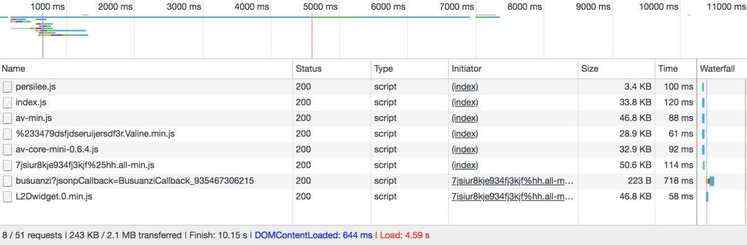
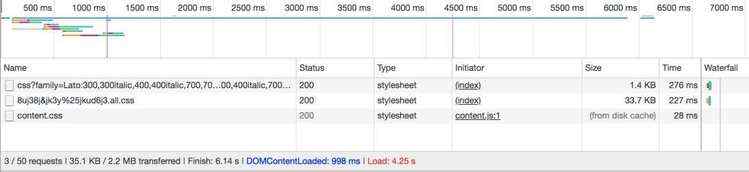
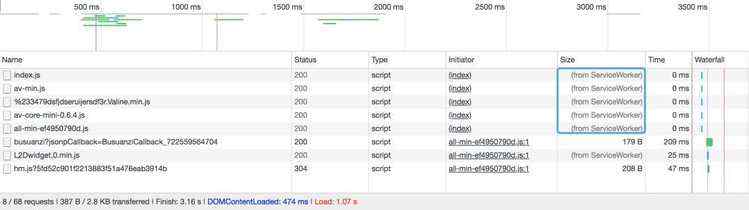
以上是 lishaoy.net 清除缓存后的首页请求速度。
可见,请求时间是 4.59 s ,总请求个数 51 , 而 js 的请求个数是 8 , css 的请求个数是 3 (其实就 all.css 一个,其它 2 个是 Google浏览器加载的), 而没使用 压缩、合并 时候,请求时间是 10 多秒,总请求个数有 70 多个, js 的请求个数是 20多个 ,对比请求时间 性能 提升 1倍 多。
如图,有缓存下的首页效果:
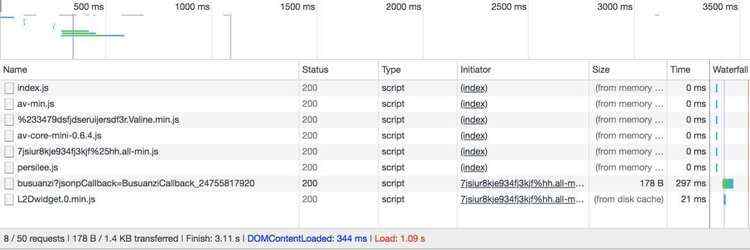
基本都是秒开 。
Tips:在 压缩、合并 后,单个文件控制在 25 ~ 30 KB左右,同一个域下,最好不要多于5个资源。
例如:gulp 图片压缩代码如下 :
//压缩imagegulp.task('imagemin', function () { gulp.src('./public/**/*.{png,jpg,gif,ico,jpeg}') .pipe(imagemin()) .pipe(gulp.dest('./public'));});
图片的合并可以采用 CSSSpirite,方法就是把一些小图用 PS 合成一张图,用 css 定位显示每张图片的位置。
.top_right .phone { background: url(../images/top_right.png) no-repeat 7px -17px; padding: 0 38px;}.top_right .help { background: url(../images/top_right.png) no-repeat 0 -47px; padding: 0 38px;}
然后,把 压缩 的图片放入 CDN ,看看效果如何:
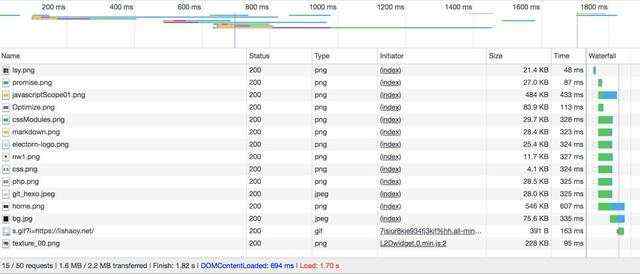
可见,请求时间是 1.70 s ,总请求个数 50 , 而 img 的请求个数是 15 (这里因为首页都是大图,就没有合并,只是压缩了) ,但是,效果很好 ,从 4.59 s 缩短到 1.70 s, 性能又提升一倍。
再看看有缓存情况如何 :
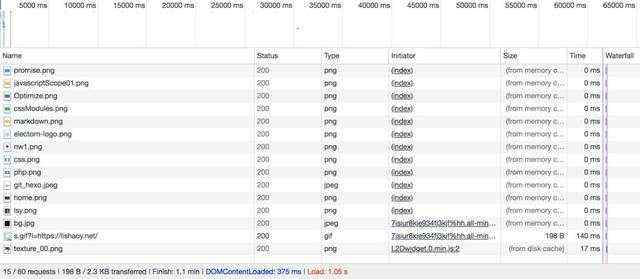
请求时间是 1.05 s ,有缓存和无缓存基本差不多。
Tips:大的图片在不同终端,应该使用不同分辨率,而不应该使用缩放(百分比)
整个 压缩、合并 (js、css、img) 再放入 CDN ,请求时间从 10 多秒 ,到最后的1.70 s,性能提升 5 倍多,可见,这个操作必要性。
缓存会根据请求保存输出内容的副本,例如 页面、图片、文件,当下一个请求来到的时候:如果是相同的 URL,缓存直接使 用本地的副本响应访问请求,而不是向源服务器再次发送请求。因此,可以从以下 2 个方面提升性能。
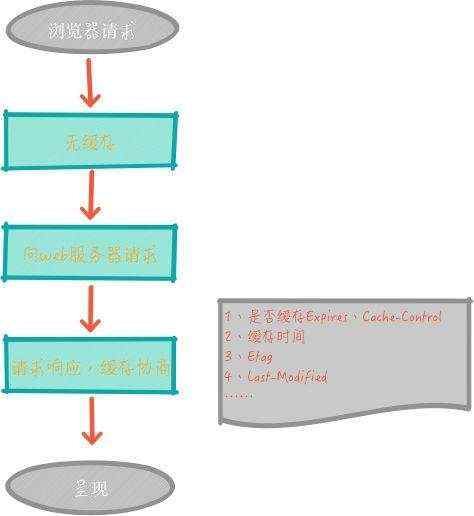
我们用两幅图来了解下浏览器的 缓存机制。
1、浏览器第一次请求
2、浏览器再次请求
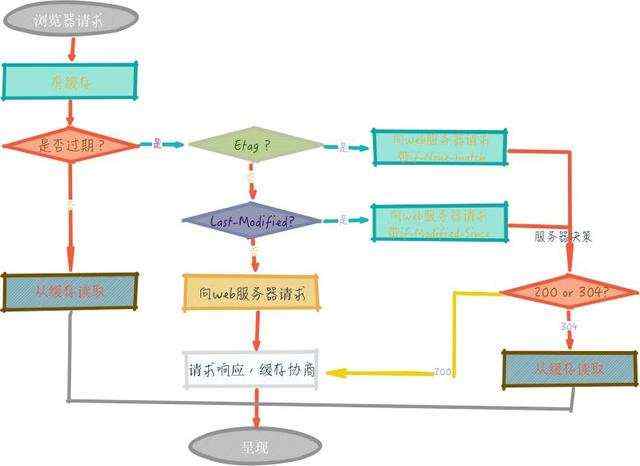
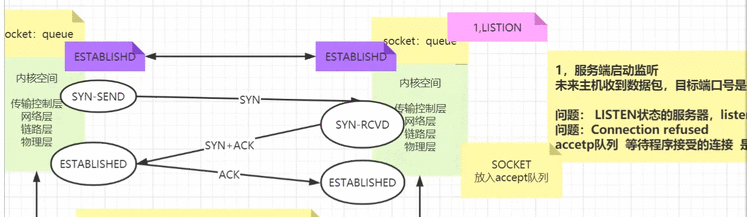
从以上两幅图中,可以清楚的了解浏览器 缓存 的过程:
我们重点来分析下第二幅图,其实是分两条线路,如下 。
第一条线路: 当浏览器再次访问某个 URL 时,会先获取资源的 header 信息,判断是否命中强缓存 (cache-control和expires) ,如命中,直接从缓存获取资源,包括相应的 header信息 (请求不会和服务器通信) ,也就是 强缓存 ,如图:
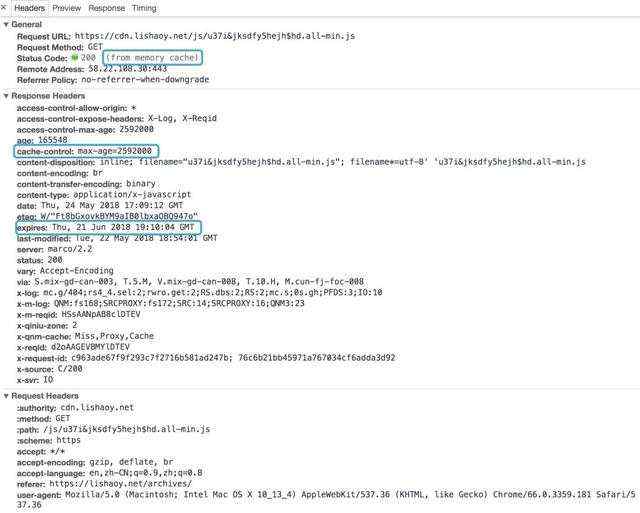
第二条线路: 如没有命中 强缓存 ,浏览器会发送请求到服务器,请求会携带第一次请求返回的有关缓存的 header 信息 (Last-Modified/If-Modified-Since和Etag/If-None-Match) ,由服务器根据请求中的相关 header 信息来比对结果是否协商缓存命中;若命中,则服务器返回新的响应 header 信息更新缓存中的对应 header 信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取;否则返回最新的资源内容,也就是 协商缓存。
现在,我们了解到浏览器缓存机制分为 强缓存、协商缓存,再来看看他们的区别 :

与强缓存相关的 header 字段有两个:
1、expires
expires: 这是 http1.0 时的规范,它的值为一个绝对时间的 GMT 格式的时间字符串,如 Mon,10Jun201521:31:12GMT ,如果发送请求的时间在 expires 之前,那么本地缓存始终有效,否则就会发送请求到服务器来获取资源。
2、cache-control
cache-control:max-age=number ,这是 http1.1 时出现的 header 信息,主要是利用该字段的 max-age 值来进行判断,它是一个相对值;资源第一次的请求时间和Cache-Control 设定的有效期,计算出一个资源过期时间,再拿这个过期时间跟当前的请求时间比较,如果请求时间在过期时间之前,就能命中缓存,否则未命中,cache-control 除了该字段外,还有下面几个比较常用的设置值:
Tips:如果 cache-control 与 expires 同时存在的话,cache-control 的优先级高于 expires。
协商缓存都是由浏览器和服务器协商,来确定是否缓存,协商主要通过下面两组 header 字段,这两组字段都是成对出现的,即第一次请求的响应头带上某个字段 (Last-Modified或者 Etag ) ,则后续请求会带上对应的请求字段 (If-Modified-Since 或者 If-None-Match ) ,若响应头没有 Last-Modified 或者 Etag字段,则请求头也不会有对应的字段。
1、Last-Modified/If-Modified-Since
二者的值都是 GMT 格式的时间字符串,具体过程:
2、Etag/If-None-Match
这两个值是由服务器生成的每个资源的唯一标识字符串,只要资源有变化就这个值就会改变;其判断过程与 Last-Modified、If-Modified-Since 类似,与 Last-Modified 不一样的是,当服务器返回 304NotModified 的响应时,由于 ETag 重新生成过, response header中还会把这个 ETag 返回,即使这个 ETag 跟之前的没有变化。
Tips:Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
1、什么是 Service Worker
Service Worker 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API。
Service worker 可以解决目前离线应用的问题,同时也可以做更多的事。Service Worker 可以使你的应用先访问本地缓存资源,所以在离线状态时,在没有通过网络接收到更多的数据前,仍可以提供基本的功能(一般称之为 Offline First)。这是原生APP 本来就支持的功能,这也是相比于 web app ,原生 app 更受青睐的主要原因。
再来看看 service worker 能做些什么:
本文主要以(lishaoy.net)资源缓存为例,阐述下 service worker如何工作。
2、生命周期
service worker 初次安装的生命周期,如图 :
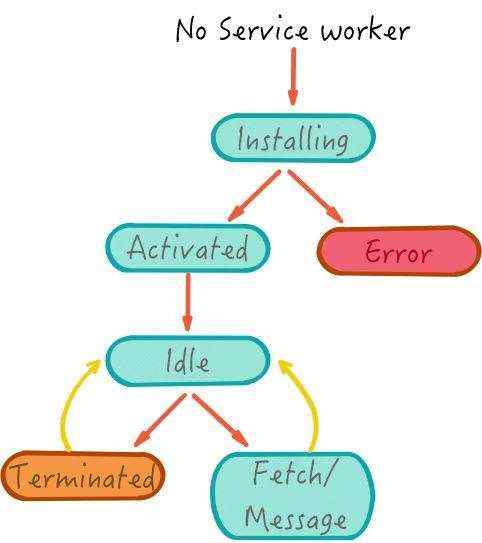
从上 图可知,service worker 工作的流程:
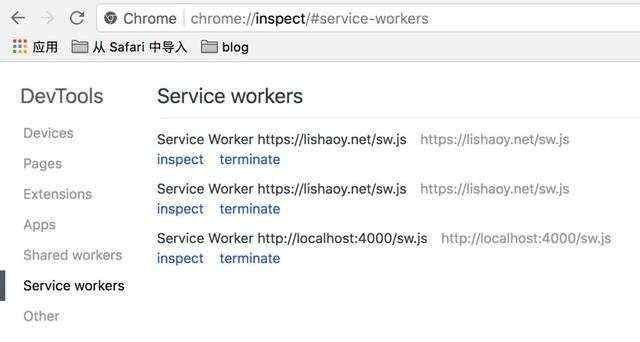
Tips:激活成功之后,在 Chrome 浏览器里,可以访问 chrome://inspect/#service-workers和 chrome://serviceworker-internals/ 可以查看到当前运行的service worker ,如图 :
现在,我们来写个简单的例子 。
3、注册 service worker
要安装 service worker ,你需要在你的页面上注册它。这个步骤告诉浏览器你的 service worker 脚本在哪里。
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/sw.js').then(function(registration) { // Registration was successful console.log('ServiceWorker registration successful with scope: ', registration.scope); }).catch(function(err) { // registration failed :( console.log('ServiceWorker registration failed: ', err); });}
上面的代码检查 service worker API 是否可用,如果可用, service worker/sw.js被注册。如果这个 service worker 已经被注册过,浏览器会自动忽略上面的代码。
4、激活 service worker
在你的 service worker 注册之后,浏览器会尝试为你的页面或站点安装并激活它。
install 事件会在安装完成之后触发。install 事件一般是被用来填充你的浏览器的离线缓存能力。你需要为 install 事件定义一个 callback ,并决定哪些文件你想要缓存.
// The files we want to cachevar CACHE_NAME = 'my-site-cache-v1';var urlsToCache = [ '/', '/css/main.css', '/js/main.js'];self.addEventListener('install', function(event) { // Perform install steps event.waitUntil( caches.open(CACHE_NAME) .then(function(cache) { console.log('Opened cache'); return cache.addAll(urlsToCache); }) );});
在我们的 install callback 中,我们需要执行以下步骤:
上面的代码中,我们通过 caches.open 打开我们指定的 cache 文件名,然后我们调用 cache.addAll并传入我们的文件数组。这是通过一连串 promise (caches.open 和 cache.addAll) 完成的。event.waitUntil 拿到一个 promise 并使用它来获得安装耗费的时间以及是否安装成功。
5、监听 service worker
现在我们已经将你的站点资源缓存了,你需要告诉 service worker 让它用这些缓存内容来做点什么。有了 fetch 事件,这是很容易做到的。
每次任何被 service worker 控制的资源被请求到时,都会触发 fetch 事件,我们可以给 service worker 添加一个 fetch 的事件监听器,接着调用 event 上的 respondWith() 方法来劫持我们的 HTTP 响应,然后你就可以用自己的方法来更新他们。
self.addEventListener('fetch', function(event) { event.respondWith( caches.match(event.request); );});
caches.match(event.request) 允许我们对网络请求的资源和 cache 里可获取的资源进行匹配,查看是否缓存中有相应的资源。这个匹配通过 url 和 vary header 进行,就像正常的 HTTP 请求一样。
那么,我们如何返回 request 呢,下面 就是一个例子 :
self.addEventListener('fetch', function(event) { event.respondWith( caches.match(event.request) .then(function(response) { // Cache hit - return response if (response) { return response; } return fetch(event.request); } ) );});
上面的代码里我们定义了 fetch 事件,在 event.respondWith 里,我们传入了一个由 caches.match产生的 promise.caches.match 查找 request 中被 service worker 缓存命中的 response 。
如果我们有一个命中的 response ,我们返回被缓存的值,否则我们返回一个实时从网络请求 fetch 的结果。
6、sw-toolbox
当然,我也可以使用第三方库,例如:lishaoy.net 使用了 sw-toolbox。
sw-toolbox 使用非常简单,下面 就是 lishaoy.net 的一个例子 :
"serviceWorker" in navigator ? navigator.serviceWorker.register('/sw.js').then(function () { navigator.serviceWorker.controller ? console.log("Assets cached by the controlling service worker.") : console.log("Please reload this page to allow the service worker to handle network operations.") }).catch(function (e) { console.log("ERROR: " + e) }) : console.log("Service workers are not supported in the current browser.")
以上是 注册 一个 service woker。
"use strict";(function () { var cacheVersion = "20180527"; var staticImageCacheName = "image" + cacheVersion; var staticAssetsCacheName = "assets" + cacheVersion; var contentCacheName = "content" + cacheVersion; var vendorCacheName = "vendor" + cacheVersion; var maxEntries = 100; self.importScripts("/lib/sw-toolbox/sw-toolbox.js"); self.toolbox.options.debug = false; self.toolbox.options.networkTimeoutSeconds = 3; self.toolbox.router.get("/images/(.*)", self.toolbox.cacheFirst, { cache: { name: staticImageCacheName, maxEntries: maxEntries } }); self.toolbox.router.get('/js/(.*)', self.toolbox.cacheFirst, { cache: { name: staticAssetsCacheName, maxEntries: maxEntries } }); self.toolbox.router.get('/css/(.*)', self.toolbox.cacheFirst, { cache: { name: staticAssetsCacheName, maxEntries: maxEntries } ...... self.addEventListener("install", function (event) { return event.waitUntil(self.skipWaiting()) }); self.addEventListener("activate", function (event) { return event.waitUntil(self.clients.claim()) })})();
就这样搞定了 (具体的用法可以去 https://googlechromelabs.github.io/sw-toolbox/api.html#main 查看)。
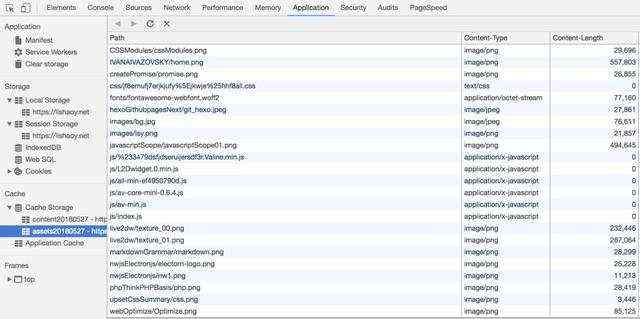
有的同学就问, service worker 这么好用,这个缓存空间到底是多大?其实,在Chrome可以看到,如图:
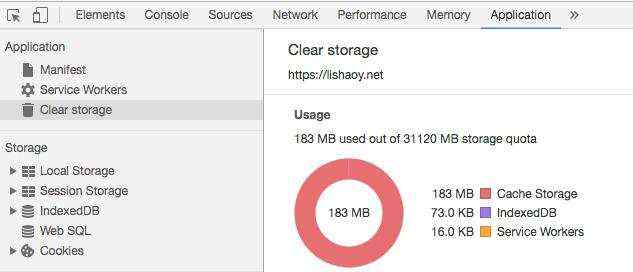
可以看到,大概有 30G ,我的站点只用了 183MB ,完全够用了 。
最后,来两张图:
由于,文章篇幅过长,后续还会继续总结 架构 方面的优化,例如:
以及,渲染 方面的优化,例如:
以及,性能测试工具,例如:
作者:子木
转发链接:segmentfault.com/a/1190000015052545







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有