ConcurrentMashmap和HashTable都是线程安全的。HashTable内部通过一个table[ ] 来存储数据,然后通过给put,get等方法加上synchronized方法来实现同步,虽然实现同步了,但是导致一个线程获得了锁,其它线程就不能执行put和get操作,这在高并发情况下效率非常低。当然这里的前提是这个HashMap是一个线程共享变量,局部变量那当然是线程私有的,自然不存在并发问题。
而ConcurrentMashmap不是通过一个table[ ]来存储数据,而是把这个table[ ]分成了许多个小的table[ ](segment[ ]),同时为每个segment配一把锁。当你put和get的时候,会根据key来获取对应segment中的锁,然后插入和读取。这就把一个大的问题拆分成了若干个子问题,以前HashMap把所有数据放一块了,偏偏为了安全每次还只让一个人取,后面的人等得急死了;诶,ConcurrentMashmap就不同了,我把所有的数据按照某种规则(根据数据的key)分类,分成比如10堆,并且规定来拿数据的key换算后是在这个区间的就去这个堆里面去拿,在那个区间的就到那个堆去拿,这里每个区间的范围不同。这样一来效率就快多了,比如到第一个堆拿数据的人很多,那这个堆得效率会低一点,但是不会影响其他人到另外9个堆的去拿数据啊。
相对于Hashmap,ConcurrentMashmap是线程安全的,同时针对并发操作也设计了自己的数据结构。ConcurrentMashmap内部用来存储数据的实际是一个segment数组。segment是ConcurrentMashmap的一个final static内部类,你可以把它看成一个Hashmap,因为它内部的属性与方法与Hashmap差不多,下面是一个大致的内存结构图:
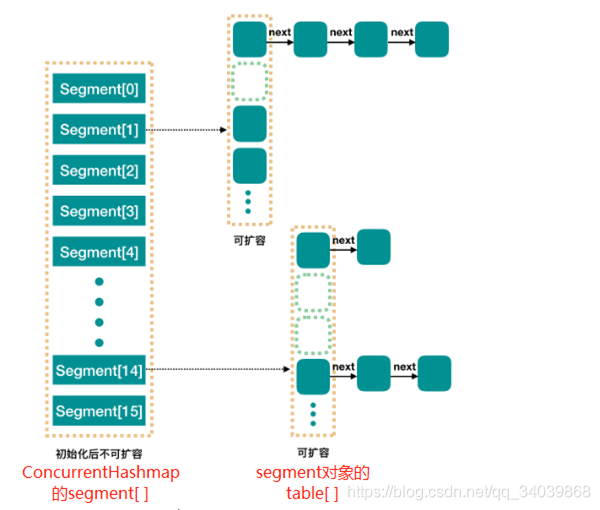
ConcurrentMashmap的一些主要字段:
static final int DEFAULT_INITIAL_CAPACITY = 16; //默认sement[]的容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认加载因子
static final int DEFAULT_CONCURRENCY_LEVEL = 16; //默认并发级别 ,即segmen[]的长度
static final int MAXIMUM_CAPACITY = 1 <<30; //table[]的最大容量,2^30
static final int MIN_SEGMENT_TABLE_CAPACITY = 2; //segment对象中table[]的最小容量
static final int MAX_SEGMENTS = 1 <<16; //segment[]的最大长度,2^16final Segment
Segment的主要字段:
static final class Segment
}
可以很清楚的看到Segment继承了ReentrantLock类,这说明Segment本身就可以作为锁使用。ConcurrentMashmap中每一个Segment锁下面锁着一个HashEntry[] table,所以并发的单位是Segment。
确定segment[ ]的长度,以及每个segment中table的容量,初始化segment[ ]和segment[0]。Segment[]的长度默认是16,可以在初始化的时候指定长度,长度最终是一个2的指数值,长度一旦确定就不能更改。
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0) || initialCapacity <0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (concurrencyLevel > MAX_SEGMENTS)cOncurrencyLevel= MAX_SEGMENTS;// Find power-of-two sizes best matching argumentsint sshift = 0;int ssize = 1;//这里的ssize基本上就是segment[]的长度,它是一个最接近于concurrencyLevel的二次幂数while (ssize
就是先判断插入的数据应该放到哪个segment中,然后在segment中插入数据。
大致上跟Hashmap的put方法差不多,只不过多了一个添加锁和释放锁的判断执行过程。若table中元素超过阈值,就库容(rehash())。 该方法主要是通过一个while(!tryLock()){}循环来不断地获取锁,如果此时锁仍然被其它线程持有,利用这个等待时间,顺便执行一下while循环体中的代码。循环体中的代码执行一次,retries(尝试获得锁的次数)变量就+1,同时判断table中有没有重复的值,没有就new一个新的HashEntry返回;有就不做操作,最终返回的是个null。 这里的rehash方法和Hashmap中的resize方法基本是一样的,都是先扩容两倍,再通过((newTableLentgh-1) & key.hash)求出节点在新table中的位置,接着用头插法把原table中的节点插入到新table中。不过Segment的rehash方法加入了一点优化判断,就是在遍历原table的时候,会用lastRun和lastIdx来记录每个单链表上的一个节点,这个节点及后面的节点在新table中的映射位置相同,这样在插入的时候直接插入lastRun即可,后面的元素也就跟着一起插入了。 一开始我不太理解为什么插入只有一句 newTable[lastIdx] = lastRun就完事了,如果之前lastIdx这个位置已经有节点存进来了,那这句代码不是会覆盖之前的节点吗?后来看到了rehash的方法说明: Because we 意思是oldTable中的节点插入到newTable中,节点的位置要么不变,要么都偏移一个2次幂数,这说明不会有其它位置上的单链表的节点会插入到newTable中的lastIdx位置。 get方法与put和remove方法不同的是没有加锁解锁动作,但是也能实现并发同步的效果。原因是因为Segment中的HashEntry[] table使用了volatile关键字,同时HashEntry中的val和next字段也被volatile修饰,由于volatile能保证共享变量被修改后立刻对其它线程可见,所以能保证查询的无锁并发。table加volatile保证table扩容后是立即可见的,HashEntry的val加volatile保证节点被修改后是立即可见的,next加volatile保证节点被新增或删除是立刻可见的。详情可见:https://www.cnblogs.com/keeya/p/9632958.html。 remove方法也有加锁动作,节点删除过程同Hashmap,也是遍历table,查找成功则删除节点并返回value,失败则返回null。注意一下match机制。 以下内容是引用该文章的观点:http://www.importnew.com/28263.html 现在我们已经说完了 put 过程和 get 过程,我们可以看到 get 过程中是没有加锁的,那自然我们就需要去考虑并发问题。 添加节点的操作 put 和删除节点的操作 remove 都是要加 segment 上的独占锁的,所以它们之间自然不会有问题,我们需要考虑的问题就是 get 的时候在同一个 segment 中发生了 put 或 remove 操作。 remove 操作我们没有分析源码,所以这里说的读者感兴趣的话还是需要到源码中去求实一下的。 get 操作需要遍历链表,但是 remove 操作会”破坏”链表。 如果 remove 破坏的节点 get 操作已经过去了,那么这里不存在任何问题。 如果 remove 先破坏了一个节点,分两种情况考虑。 1、如果此节点是头结点,那么需要将头结点的 next 设置为数组该位置的元素,table 虽然使用了 volatile 修饰,但是 volatile 并不能提供数组内部操作的可见性保证,所以源码中使用了 UNSAFE 来操作数组,请看方法 setEntryAt。2、如果要删除的节点不是头结点,它会将要删除节点的后继节点接到前驱节点中,这里的并发保证就是 next 属性是 volatile 的。public V put(K key, V value) {SegmentSegment的put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {//通过tryLock()方法来获取锁,获得锁返回true,持有锁数目+1;锁被其它线程持有返回false//scanAndLockForPut方法分析见文章下面代码HashEntrySegment的scanAndLockForPut方法
private HashEntry 扩容,Segment的rehash方法
* are using power-of-two expansion, the elements from
* each bin must either stay at same index, or move with a
* power of two offset.private void rehash(HashEntry ConcurrentHashmap的get方法
public V get(Object key) {SegmentConcurrentHashmap的remove方法
/*** Remove; match on key only if value null, else match both.*/final V remove(Object key, int hash, Object value) {if (!tryLock())scanAndLock(key, hash);V oldValue = null;try {HashEntry 并发问题分析








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 