标题中提到hdfs(Hadoop Distribute File System)是分布式文件系统

本文主要包括以下5个内容
1.HDFS架构
2.HDFS 读写流程
3.HDFS HA(高可用)
4.小文件是什么
5.小文件带来的瓶颈
引言:
学习新框架方法
推荐官网+源码
hadoop.apache.org
spark.apache.org
flink.apache.org
storm.apache.org
HDFS架构
可以查看官网的描述
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
介绍NameNode and DataNodes

结合上图官网 描述可以总结
HDFS has a master/slave architecture 是一个主从的架构
An HDFS cluster consists of a single NameNode 一个集群只有一个NameNode
there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. 有多个 DataNodes 主要作用是管理manages 文件系统的命名空间,和管理需要访问文件的客户端
HDFS exposes a file system namespace and allows user data to be stored in files. HDFS公开了文件系统名称空间,并允许用户数据存储在文件中。
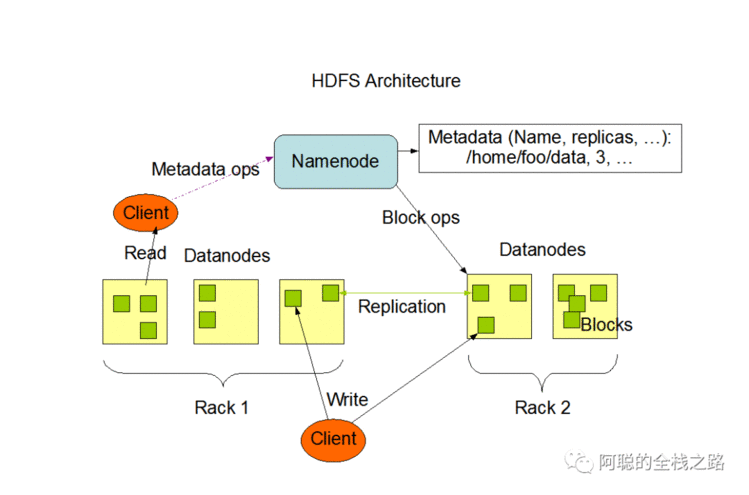
根据上图
可以看到有这么几个概念
Client
NameNode( 简写为NN)
DataNodes (简写为 DN)
Block
Client 用于发起HDFS请求,可以是用户,可以是代码
NN 存在唯一一个,所以存在SinglePoint of Failure (单点故障的问题) 引出 ==》HA(heigh available)
DN 存在多个
作用:存储数据 和NN 之间有心跳
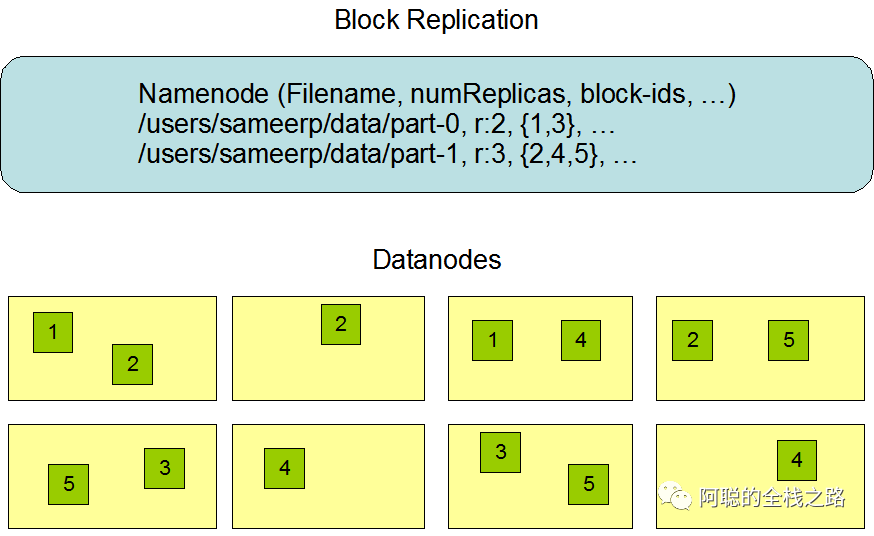
Namenode 创建的时候,配置有文件名字、 副本数 等
2.读写流程
了解架构后,我们来看读写流程
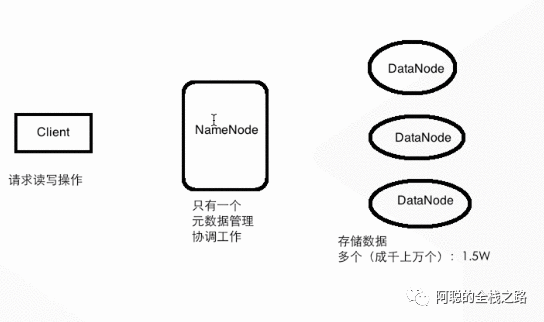
假设我们有一个client 一个NameNode 三个DataNode,等几个角色
(1)写入流程
1.一个用户、代码需要写入文件
第一步:client 从配置文件(hdfs 的配置文件中)获取到 1. 副本大小 2.副本数量
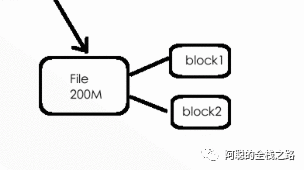
第二步:在第一步获取的的参数中,进行文件拆分
第三步:client 向 NameNode 发起请求,询问NameNode 文件应该放在哪里
第四步: NameNode 返回文件,可以存放到的位置
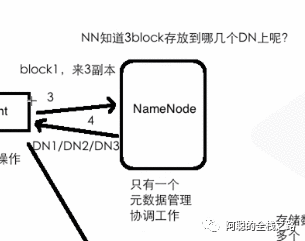
第五步:client 对指定的DataNode 位置写入文件

DataNode 写入完成进行副本拷贝和通知NameNode
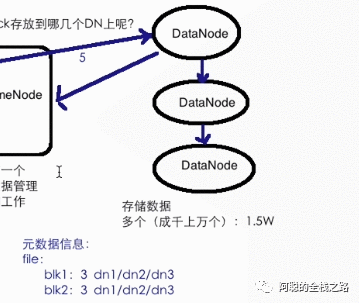
(2)读取流程(就相对比较简单了)
第一步:客户段请求NameNode 文件
第二步:NameNode 返回存放该数据的DataNode 地址
第三步:client 到DataNode 读取数据
3.HA (高可用)架构
在官网上可以看到有QJM 和NFS 架构
QJM(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html)
NFS(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html)
其中见常见的HA框架如下图所示
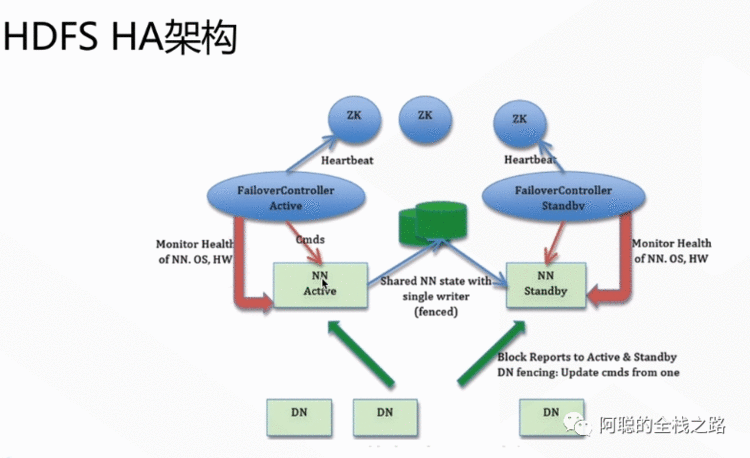
建立多个NameNode 一个Active 活动状态, 一个Standby 备用,通过Monitor Health 监控状态, 通过Zookeeper 协调主备切换
4.小文件是什么
小文件是指文件size小于HDFS上block大小的文件。这样的文件会给hadoop的扩展性和性能带来严重问题
为什么有小文件?
1、实时处理:比如我们使用 Spark Streaming 从外部数据源接收数据,然后经过 ETL 处理之后存储到 HDFS 中。这种情况下在每个 Job 中会产生大量的小文件。2、hive中对表执行insert操作,每次插入都在表目录下形成一个小文件。创建表结构相同的表,create table t_new as select * from t_old;老表根据实际情况可以删除就删除。3、hive中执行简单过滤操作,符合过滤条件的数据存在很多block块中,走map,map输出有很多小文件。开启map端的聚合。4、mapreduce正常执行产生小文件。将mapreduce输出不直接写hdfs,而是写入到hbase中。设置map端文件合并及reduce端文件合并。5、输入数据文件为小文件。小文件合并后再计算。CombineFileInputFormat:它是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
5.小文件带来的瓶颈
1.磁盘IO
2.task启动销毁的开销
3.资源有限(磁盘空间)
具体为:处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
最后小文件的解决方法:
通用处理方案:
1、Hadoop Archive
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
2、Sequence file
sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
底层处理方案:
HDFS-8998:
DataNode划分小文件区,专门存储小文件。一个block块满了开始使用下一个block。
HDFS-8286:
将元数据从namenode从内存移到第三方k-v存储系统中。
HDFS-7240:
Apache Hadoop Ozone,hadoop子项目,为扩展hdfs而生。
如有不足,请批评指正!!









 京公网安备 11010802041100号
京公网安备 11010802041100号