https://hbase.apache.org/book.html#arch.overview快速开始
HBase 需要JDK支持
下载安装包,直接解压:
$ tar xzvf hbase-3.0.0-SNAPSHOT-bin.tar.gz
$ cd hbase-3.0.0-SNAPSHOT/
在启动HBase 的时候,你必须设置JAVA_HOME环境变量。为了让这个更简单,HBase可以让你在 conf/hbase-env.sh中设置。
例如:
# Set environment variables here.
# The java implementation to use.
export JAVA_HOME=/usr/jdk64/jdk1.8.0_112
编辑 conf/hbase-site.xml,HBase主配置文件。
此时,您需要在本地文件系统上指定HBase和ZooKeeper写入数据和风险信息的目录。默认情况下,是在/tmp创建一个新目录。
下面是单服务HBase的配置 例子:
Controls whether HBase will check for stream capabilities (hflush/hsync).
Disable this if you intend to run on LocalFileSystem, denoted by a rootdir
with the 'file://' scheme, but be mindful of the NOTE below.
WARNING: Setting this to false blinds you to potential data loss and
inconsistent system state in the event of process and/or node failures. If
HBase is complaining of an inability to use hsync or hflush it's most
likely not a false positive.
不用创建HBase 数据目录。HBase将自动创建,如果你创建了目录,HBase会试图合并。
要在现有的HDFS实例上安装HBase,请将hbase.rootdir设置为指向实例上的目录:例如HDFS://http://namenode.example.org:8020/HBase。
1.bin/start-hbase.sh 脚本提供了更简单的方式来启动HBase。可以使用jps命令来查看运行的进程 HMaster。在单服务器模式下的HBase在单个JVM中运行所有的后台进程,例如HMaster,单个HRegionServer和ZooKeeper进程。访问 http://localhost:16010 来查看HBase Web UI过程:第一次使用HBase
1.连接到HBase
使用位于HBase安装目录中bin/目录中的hbase shell命令连接到正在运行的HBase实例。 在此示例中,省略了启动HBase Shell时打印的一些用法和版本信息。 HBase Shell提示符以>字符结尾。
$ ./bin/hbase shell
hbase(main):001:0>
使用help 会打印HBase Shell 帮助文本
2.创建表
使用create 命令来创建新表。你必须指定表名和 ColumnFamily 名称。
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
3.列出表的信息
使用list命令来确认现在现存的表
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
使用describe命令查看详细信息,包含默认配置。
4.将数据增加到你的表中
使用put 命令
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
在这里,我们插入三个值,一次一个。 第一个插入row1,列cf:a,值为value1。 HBase中的列由列族前缀组成,在此示例中为cf,后跟冒号,然后是列限定符后缀,在本例中为a。
5.扫描表的所有数据
从HBase获取数据的一种方法是扫描。 使用scan命令扫描表中的数据。 您可以限制扫描,但是目前,所有数据都被获取。
hbase(main):006:0> scan 'test'
6.获得单独的数据行
在某一时间获取到单独一行,使用get命令
hbase(main):007:0> get 'test', 'row1'
7.禁用一个表
如果要删除表或更改其设置,以及在某些其他情况下,您需要先使用disable命令禁用该表。 您可以使用enable命令重新启用它。
hbase(main):008:0> disable 'test'
0 row(s) in 1.1820 seconds
hbase(main):009:0> enable 'test'
0 row(s) in 0.1770 seconds
8.删除表
使用drop 命令
hbase(main):011:0> drop 'test'
0 row(s) in 0.1370 seconds
9.退出HBase Shell
使用quit 命令退出,HBase仍然在后台运行
过程:关闭HBase
1.与提供bin / start-hbase.sh脚本以方便地启动所有HBase守护程序的方式相同,bin / stop-hbase.sh脚本会停止它们。
./bin/stop-hbase.sh
2.在发布命令之后,会花费一些时间来关闭。使用jps来确定HMaster和HRegionServer 进程关闭。
上面已经向您展示了如何启动和停止HBase的独立实例。 在下一节中,我们将简要介绍其他hbase部署模式。伪分布式本地安装
在快速启动了单服务器模式之后,你可以重新配置HBase 运行在伪分布式模式下。这个模式下,虽然仍在一个主机上,但是,每个HBase守护进程(HMaster,HRegionServer,ZooKeeper) 运行在分开的进程:
在单服务器模式下,所有守护进程运行在一个jvm进程/实例中。在下面演示中,我们存储数据到HDFS中,假设你有一个可用的HDFS。您可以跳过HDFS配置以继续将数据存储在本地文件系统中。
1.停止运行的HBase
如果您刚刚完成快速启动并且HBase仍在运行,请将其停止。 此过程将创建一个全新的目录,HBase将存储其数据,因此您之前创建的任何数据库都将丢失。
2.配置HBase
编辑hbase-site.xml配置。 首先,添加以下属性,该属性指示HBase以分布式模式运行,每个守护程序有一个JVM实例。
下一步,变更 hbase.rootdir 从本地文件系统到HDFS文件系统地址,使用hdfs: URI语法。在这个例子中,HDFS运行在本地的8020端口。请务必删除hbase.unsafe.stream.capability.enforce的条目或将其设置为true
不需要在HDFS中创建目录。HBase会自动创建
3.启动HBase
使用bin/start-hbase.sh 启动HBase。如果系统被正确配置,jps 命令将显示HMaster 和HRegionServer 进程运行
4.检查HBase 目录在HDFS中
如果所有工作都正确,HBase将在HDFS中创建目录。在上面的配置中,其存储在HDFS中的/hbase/。你可以在Hadoop的bin/目录中使用hadoop fs 命令列出这个目录
./bin/hadoop fs -ls /hbase
5.创建一个表并填充数据
6.启动和停止备用的HBase Master(HMaster)服务器
在同一硬件上运行多个HMaster实例在生产环境中没有意义,就像运行伪分布式集群对生产没有意义一样。 此步骤仅用于测试和学习目的。
HMaster服务器控制HBase集群。 您可以启动最多9个备用HMaster服务器,算上主服务器是10个服务器。 要启动备份HMaster,请使用local-master-backup.sh。 对于要启动的每个主的备份,添加一个表示该主站的端口偏移量的参数。 每个HMaster使用两个端口(默认为16000和16010)。 端口偏移量将添加到这些端口,因此使用偏移量2,备份HMaster将使用端口16002和16012.以下命令使用端口16002 / 16012,16003 / 16013和16005/16015启动3个备份服务器。
./bin/local-master-backup.sh start 2 3 5
要在不杀死整个群集的情况下终止备份主服务器,您需要找到其进程ID(PID)。 PID存储在名为/tmp/hbase-USER-X-master.pid的文件中。 该文件的唯一内容是PID。 您可以使用kill -9命令来终止该PID。 以下命令将使用端口偏移量1终止主服务器,但保持集群运行:
cat /tmp/hbase-testuser-1-master.pid |xargs kill -9
7.启动和停止其他RegionServers
HRegionServer通过HMaster的指示管理其在StoreFiles中的数据。通常,HRegionServer在群集中的每个节点上运行。在同一系统上运行多个HRegionServers对于以伪分布式模式进行测试非常有用。 local-regionservers.sh命令允许您运行多个RegionServers。它的工作方式与local-master-backup.sh命令类似,因为您提供的每个参数都代表实例的端口偏移量。每个RegionServer需要两个端口,默认端口为16020和16030.自HBase版本1.1.0起,HMaster不使用区域服务器端口,这将留下10个端口(16020到16029和16030到16039)用于RegionServers。要支持其他RegionServers,请在运行脚本local-regionservers.sh之前将环境变量HBASE_RS_BASE_PORT和HBASE_RS_INFO_BASE_PORT设置为适当的值。例如对于基本端口,值为16200和16300,在服务器上可以支持99个额外的RegionServers。以下命令启动另外四个RegionServers,在16022/16032(基本端口16020/16030加2)的顺序端口上运行。
.bin/local-regionservers.sh start 2 3 4 5
要手动关闭 RegionServers,使用带stop参数合服务器便宜量的 local-regionservers.sh 命令
.bin/local-regionservers.sh stop 3
8.停止 HBase
您可以使用bin/stop-hbase.sh命令的方式停止HBase。2.4 完全分布式
实际上,您需要完全分布式配置才能完全测试HBase并在实际场景中使用它。 在分布式配置中,群集包含多个节点,每个节点运行一个或多个HBase守护程序。 这些包括主要和备份主实例,多个ZooKeeper节点和多个RegionServer节点。
此高级快速入门为您的群集添加了两个节点。 架构如下:
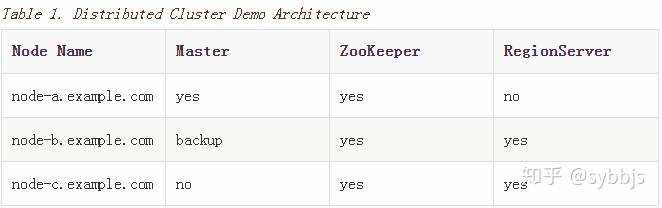
本快速入门假定每个节点都是虚拟机,并且它们都在同一网络上。 它建立在之前的伪分布式本地安装的基础上,假设您在该过程中配置的系统现在是node-a。 在继续之前停止node-a上的HBase。
确保所有节点都具有完全的通信访问权限,并且没有防火墙规则可以阻止它们相互通信。 如果您看到任何错误,例如no route to host,请检查您的防火墙。
过程:配置无密码 SSH 访问
node-a需要能够登录到node-b和node-c(以及自身)才能启动守护进程。 完成此操作的最简单方法是在所有主机上使用相同的用户名,并从node-a配置登录到其他每个主机无密码SSH。
1.在 node-a,产生一个键对
以运行HBase的用户身份登录时,使用以下命令生成SSH密钥对:
ssh-keygen -t rsa
如果命令成功,则将密钥对的位置打印到标准输出。 公钥的默认名称是id_rsa.pub。
2.在其他节点上创建将保存共享密钥的目录
在node-b和node-c上,以HBase用户身份登录,并在用户home 目录中创建一个.ssh /目录(如果该目录尚不存在)。 如果它已存在,请注意它可能已包含其他键。
3.拷贝公钥到其他节点
通过使用scp或其他一些安全方法,将公钥从node-a安全地复制到每个节点。 在每个其他节点上,创建一个名为.ssh / authorized_keys的新文件(如果该文件尚不存在),并将id_rsa.pub文件的内容追加到其末尾。 请注意,您还需要为node-a本身执行此操作。
cat id_rsa.pub >> ~/.ssh/authorized_keys
4.测试无密码登录
5.
由于node-b将运行备份Master,重复上面的过程,在node-a的任何地方替换node-b。 请确保不要覆盖现有的.ssh / authorized_keys文件。
过程:准备 node-a
node-a将运行主master和ZooKeeper进程,但不运行RegionServers。 从node-a开始停止RegionServer。
1.编辑conf/regionservers并remove包含localhost的行。 为node-b和node-c添加主机名或IP地址的行
即使您确实想要在node-a上运行RegionServer,也应该通过其他服务器用来与之通信的主机名来引用它。 在这种情况下,那将是http://node-a.example.com。 这使您可以将配置分发到群集的每个节点,任何主机名都会发生冲突。 保存文件。
2.配置HBase 使用node0b作为 主备份服务器
在conf/called backup-master中创建一个新文件,并使用node-b的主机名为其添加一个新行。 在此演示中,主机名为http://node-b.example.com。
3.配置ZooKeeper
实际上,您应该仔细考虑ZooKeeper配置。 您可以在zookeeper部分找到有关配置ZooKeeper的更多信息。 此配置将指示HBase启动和管理群集的每个节点上的ZooKeeper实例。
在node-a,编辑conf/hbase-site.xml并增加下来属性
4.在您的配置中,您已将node-a引用为localhost,将引用更改为指向其他节点用于引用node-a的主机名。 在这些示例中,主机名是http://node-a.example.com。
过程: 准备node-b和node-c
node-b将运行备份主服务器和ZooKeeper实例。
1.下载和解压HBase
将HBase下载并解压缩到node-b。
2.从node-a拷贝配置文件到node-b和node-c
群集的每个节点都需要具有相同的配置信息。 将conf/目录的内容复制到node-b和node-c上的conf/目录
过程:启动和测试你的集群
1.
确保HBase没有在任何节点上运行
如果您忘记在之前的测试中停止HBase,则会出现错误。 使用jps命令检查HBase是否在任何节点上运行。 查找进程HMaster,HRegionServer和HQuorumPeer。 如果他们存在,kill 掉他们。
2.启动集群
在node-a上,发出start-hbase.sh命令。 您的输出将类似于以下内容。
$ bin/start-hbase.sh
node-c.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-c.example.com.out
node-a.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-a.example.com.out
node-b.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-b.example.com.out
starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-node-a.example.com.out
node-c.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-c.example.com.out
node-b.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-b.example.com.out
node-b.example.com: starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-nodeb.example.com.out
ZooKeeper首先启动,然后是master,然后是RegionServers,最后是备份主服务器。
3.验证进程都在运行中
在群集的每个节点上,运行jps命令并验证每个服务器上是否正在运行正确的进程。 如果它们用于其他目的,您可能会在服务器上看到其他Java进程。
node-a jps的输出
jps
20355 Jps
20071 HQuorumPeer
20137 HMaster
node-b jps的输出
jps
15930 HRegionServer
16194 Jps
15838 HQuorumPeer
16010 HMaster
node-c jps的输出
jps
13901 Jps
13639 HQuorumPeer
13737 HRegionServer
ZooKeeper进程名称
HQuorumPeer进程是一个ZooKeeper实例,由HBase控制和启动。 如果以这种方式使用ZooKeeper,则每个群集节点仅限一个实例,并且仅适用于测试。 如果ZooKeeper在HBase之外运行,则该进程称为QuorumPeer。
4.在Web UI 上查阅
在HBase比0.98.x更新的情况下,HBase Web UI使用的HTTP端口从Master的60010和每个RegionServer的60030变为Master的16010和RegionServer的16030。
如果一切设置正确,您应该能够连接到Master http://node-a.example.com:16010/的UI或http://node-b.example.com:16010上的辅助主机。 如果您可以通过localhost连接但不能从其他主机连接,请检查防火墙规则。 您可以在端口16030查看其IP地址的每个RegionServers的Web UI。
5.测试节点或服务消失时会发生什么
使用已配置的三节点群集,事情将不会非常有弹性。 您仍然可以通过终止关联进程并查看日志来测试主Master或RegionServer的行为








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 