前言
文章不含源码,只是一些官方资料的整理和个人理解
架构总览
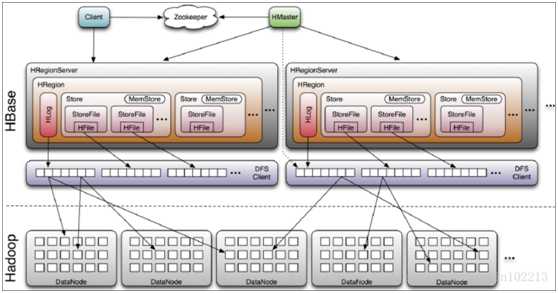
这张图在大街小巷里都能看到,感觉是hbase架构中最详细最清晰的一张,稍微再补充几点。
1) Hlog是低版本hbase术语,现在称为WALs。
2) 1个region包含了多个store,1个store包含了1个colum family,这样就比较好理解
3) 1个store包含了多个storefile,1个sotrefile就是1个hfile文件
这在HDFS路径也能体现,大概长这样
table/region/column family/hfile
region
region就是一些连续的hfile集合,也就是说连续的hfile被存储在一个region目录下。
我们知道,hbase索引一个数据其实是通过遍历的方式,当然是经过优化的遍历,而region就起到了一个很大的作用。想象一下,如果你要在一堆文件中找到你要的内容,怎么样的文件结构才是更快。
·有序
假如你要找的文件有关键字a,那么如果所有文件是按关键字(hbase的rowkey)排序的,那么a就有迹可循,Hbase采用了lexicographic order(这个单词有点不想单词..)也就是字典排序(ASCII码),对每个rowkey从高位到地位排序。
·分块
Rowkey已经是排序的,但还是要遍历啊,万一有个rowkey是z开头的,不是要哭死。Hfile就出现了,一个hfile里有一段连续的rowkey,并且记录了所有rowkey的长度和整个hfile的rowkey是起始和终止。这样就方便了很多,遍历的时候只要看一个文件夹是否包含了该rowkey,而不用一个一个对比。(先忽略column family机制,bloom filter机制)
·进一步分块
但是hfile还是很多啊,要是把hfile容量扩大也不利用读。
最容易想到的就是把多个hfile统一管理,再做封装,这里就引申出了region。一些连续的hfile被一个region管理,region记录了rowkey的起始和终止等信息。这样遍历起来又快了很多。
region split
上面说的解决了遍历的性能问题,但是region也会变大,就像hfile会变大一样。这时候region split就出现了。
当region被认为需要split的时候(max size超过阈值),一系列操作就出现了。
1) region是否需要分割是否regionserver决定的,当需要的时候,通过zookeeper和master沟通一下
2) regionserver关闭该region,并且把memstore的相关数据flush到hfile。这时候有client来请求,则会抛出NotServingRegionException异常
3) 准备子region的相关环境(路径啊,文件夹啊什么的,都是临时的),创建两个文件来指向父region(也就是待split的region)
4) 创建两个真正的子region(文件夹),并把那两个文件移过去
5) regionserver向hbase:meta表发起Put请求,把待分割的region设置为offline,并且增加子region的信息。在这过程中,客户端并不能真正看到子region(还不是独立的region),只是能知道有个父region在split。当put请求成功后,父region才会正真的split。(如果put请求失败了,那么由master分配新的regionserver来重新region split,在此之前会把上一次split失败的相关脏数据清除)
6) 打开子region,接收写操作。为之后无缝接入服务做准备
7) regionserver再向hbase:meta表添加相关信息。然后客户端再请求就能搜索到子region。当然由于region是新建的,所以之前的缓存都不可用。
8) regionserver通过zookeeper和master交互,让master知道有新region split好了。Master可以决定新region由哪个regionserver管理
9) 最后就是善后工作,由于新region实际上没有父region的数据,只有一些引用来指向父region。所以在子region compaction的时候,会重写这些数据。另外hbase的master还有一个GC task(不是jvm的GC),来定期轮询,查看是否还有引用父region,当没有的时候就删除父region
总结
整个流程虽然看上去很复杂,其实效率很高,region split的过程中是不可用的,但是这时间很短,因为不涉及大量的io,只有引用和交互。
master和regionserver之间的配合,master主要做协调,regionserver做实际的工作
Region compaction
其实用storefile compaction来表示更合适,compaction分为两种,minor和major
Minor
Minor compaction主要合并一些小的相邻的hfile,重写进一个新的hfile。重写的过程不包括数据的drop,filter,delete等移除操作,只是简单的把小文件合并成大文件。
Major
major compaction会把所有需要清除的数据都移除,最终合并成一个storefile。合并过程中服务还是可以使用,但是会慢一点。
major合并的主要目的是为了提高性能,但是major操作本身也是一个耗费资源(cpu,mem)的过程,默认是7天合并一次,但是这个时间点可能并不是最合适的。所以我们可以手动操作major。
数据需要被移除一般有三种情况
1) 客户端显示的声明delete
2) 某些column family的version超过max version
3) 某些设置了TTL的column family
参考资料
//hbase官网推荐的region split 博客
https://hortonworks.com/blog/apache-hbase-region-splitting-and-merging/
hbase(一)region






 京公网安备 11010802041100号
京公网安备 11010802041100号