作者:正研,阿里云数据库技术专家
阿里云HBase增强版(Lindorm)简介
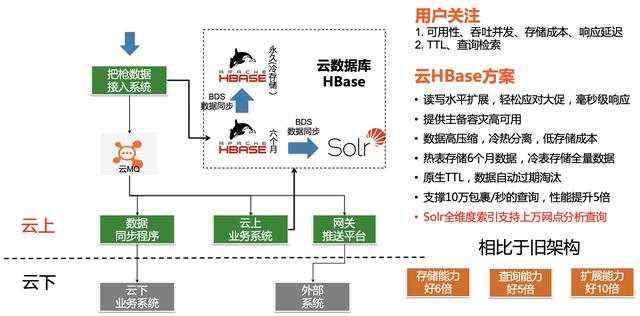
阿里云数据库HBase增强版,是基于阿里集团内部使用的Lindorm产品研发的、完全兼容HBase的云上托管数据库,从2011年开始正式承载阿里内部业务的海量数据实时存储需求,支撑服务了淘宝、支付宝、菜鸟、优酷、高德等业务中的大量核心应用,历经双十一、春晚、十一出行节等场景的大规模考验,在成本、性能、稳定性、功能、安全、易用性等方面相比社区版拥有诸多优势和企业级能力,更多介绍可以参考Lindorm帮助文档(https://help.aliyun.com/document_detail/119548.html)
当大数据存储遇上复杂查询
HBase是目前广泛使用的NoSQL数据库,其具有Schemeless特性,高吞吐,海量存储和无限水平扩展的特性,因此被很好地应用在了推荐、风控、物联网、画像、表单等所有大数据场景。但是原生的HBase只支持Rowkey索引,即按rowkey的二进制排序的索引。HBase的Scan请求可基于此rowkey索引高效的执行整行匹配、前缀匹配、范围查询等操作。但若需要使用rowkey之外的列进行查询,则只能使用filter在指定的rowkey范围内进行逐行过滤。若无法指定rowkey范围,则需进行全表扫描,不仅浪费大量资源,查询RT也无法保证。
为了解决用户基于非主键列的查询问题,阿里云HBase增强版(Lindorm)内置原生的全局二级索引功能,对于列较少且有固定查询模式的场景来说,阿里云的高性能二级索引方案能够完美解决此类问题,同时仍保持强大的吞吐与性能。这个索引方案在阿里内部使用多年,经历了多次双11考验,尤其适合解决海量数据的全局索引场景。关于高性能二级索引,用户可以参考《数据查询的玄铁剑:Lindorm二级索引功能解析》一文(https://developer.aliyun.com/article/740009 ), 同时,社区也有Phoenix,在HBase之上提供了插件式的二级索引以及SQL能力,使用SQL可以比较简单地表达一些复杂查询。
但是,当面对更加复杂的查询,比如表单、日志查询里面的模糊查找,用户画像里面的随机条件组合查询等等,二级索引方案会显得力不从心。而这些查询,正是搜索引擎的优势。
Solr是分布式全文检索的最佳实践之一。Solr支持各种复杂的条件查询和全文索引。通过智能集成Solr,Lindorm可以充分发挥海量数据的实时存储和检索能力,使得其可以高效支撑于:需要保存大数据量数据,而查询条件的字段数据仅占原数据的一小部分,并且需要各种条件组合查询的业务。例如:
- • 常见物流业务场景,需要存储大量轨迹物流信息,并需根据多个字段任意组合查询条件
- • 交通监控业务场景,保存大量过车记录,同时会根据车辆信息任意条件组合检索出感兴趣的记录
- • 各种网站会员、商品信息检索场景,一般保存大量的商品/会员信息,并需要根据少量条件进行复杂且任意的查询,以满足网站用户任意搜索需求等。
数据同步的难题
要想在Lindorm中集成Solr,必须想办法将业务写入Lindorm的主表数据实时索引到Solr中,然而存储主表数据的宽表引擎和存储索引数据的Solr检索引擎有很大的差异性,比如数据模型上,两者差别较大,写入能力上,也有巨大的差异。针对宽表与检索两种异构引擎间的数据同步,目前市面上主要有两种类似的方案:
应用双写
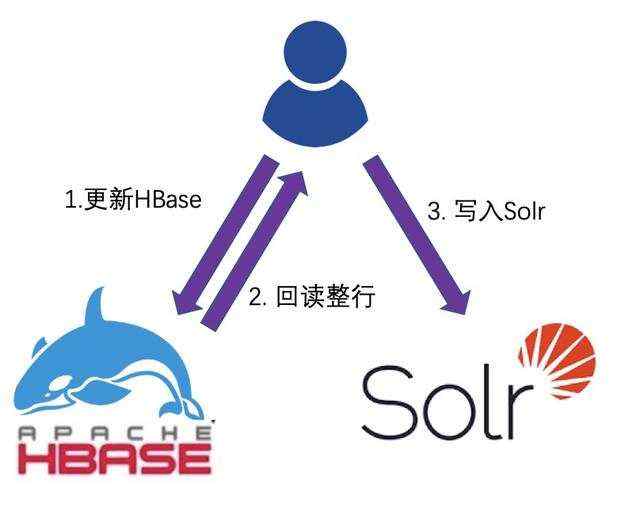
双写是最容易想到,也是最容易实现的方案。以用户自己维护的双写HBase+Solr为例:业务将数据写入HBase的同时,也将同样的数据写入Solr即可。有些用户使用了HBase的Coprocessor功能,hook了HBase的写入逻辑,在HBase完成写入时,在Coprocessor中写入solr,本质上也是双写HBase和Solr
但双写HBase和Solr存在非常多的问题,需要用户自己去解决:一致性难以保证
- 当HBase写入成功,Solr写入失败,或者HBase写入失败,Solr写入成功都会造成数据不一致,用户需要自己处理此类情况。
- HBase支持更新部分列,而Solr只能整行更新,因此当更新HBase后,还需要在HBase中读取整行数据,才能写入Solr,当有多个线程同时修改一行时,会导致HBase和Solr中的数据不一致。
- 就算用户写入HBase时是整行全量更新,无需回读,写入HBase和写入Solr并不是原子更新,很难保证HBase的写入顺序跟Solr中的修改顺序一致从而导致数据不一致问题
稳定性降低双写HBase和Solr等于把HBase和Solr的可用性捆绑在了一起。Solr的可用性会反过来影响HBase的可用性。一旦Solr出现问题,用户要么选择放弃写Solr,放弃数据一致性来确保可用性,要么只能无限重试等待Solr恢复来确保数据一致性,但降低了可用性。在HBase的Coprocessor中写Solr的用户的稳定性问题尤为突出,如果用户没有处理好Solr的抛错和重试时的内存管理,很容易直接造成HBase RegionServer的宕机。读写能力下降很多用户选择HBase的主要原因是HBase具有海量吞吐能力,而现在双写Solr等于将HBase的写入能力拉低到了Solr的水平,大部分业务都无法接受。同时双写时需要回读HBase获取整行数据,回读会造成HBase额外的压力,从而进一步降低了HBase的读写能力
开源Lily HBase Indexer
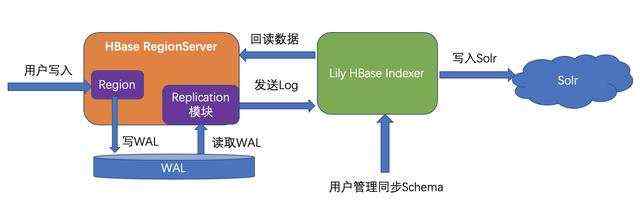
Lily HBase Indexer(下文简称Indexer)是Cloudera推出的HBase和Solr之间的数据同步组件。他利用了HBase的Replication功能,将自己"伪装"成一个HBase的Replication sink集群,当HBase有数据写入时,Replication会通过读取WAL文件获取最新更新传输到Indexer里,然后再由Indexer写入Solr。
同样,这套方案也存在大量问题:同步效率低
- Indexer使用的是Replication框架。在Replication框架下,一行数据的更新需要先要序列化写入WAL,然后通过Replication从WAL中读出反序列化,然后序列化成二进制数据发送到Indexer,Indexer再反序列化成数据才能写入Solr。整个过程非常低效,同步的速率受限于HBase的Replication能力,往往Solr的写入瓶颈还没达到,就已经达到了HBase的Replication瓶颈。
- Indexer的同步模型是每一个HBase表,都开启一条Replication通道(一个Replication Peer)。有10张HBase表需要同步到Solr,就必须有10个Replication Peer,这意味着同一个WAL,会被读取10次(每个peer都读取一次)随着同步表的增多,对HDFS的压力也就越大。
- 由于HBase是SchemaLess的,Indexer收到Replication发过来的WAL后,无法知道是否在WAL中有整行数据,因此它必须在写Solr之前回读HBase获取整行数据。因此实际上,WAL中的entry发送过来后,有用的只有rowkey,其他的数据还是要依靠回读,这些WAL entry经历了这么长的发送链路,但大部分信息却是无用的。同时,回读会占用HBase资源,影响HBase稳定性。
数据一致性无法保证使用Indexer同步HBase到Solr会经常遇到两者之间数据不一致的问题,这也是Indexer的用户吐槽最多的地方。
这些不一致往往发生的非常随机,一般用户也很难查到原因,让人摸不到头脑。我们深入研究Indexer后发现了他的问题所在。由于Indexer依赖了HBase的Replication做同步,而HBase Replication有一个重要的特点就是乱序发送,这对于HBase集群之间的Replication无影响,因为HBase可以用KV的时间戳来保证最终一致。但是Solr是不支持列时间戳的,HBase的写入乱序到达Indexer会导致写入Solr中的数据与HBase不一致。
比如用户有两次更新同一行,。但是在replication过程中, ts2的更新先到Indexer,而ts1的更新后到,这会导致Indexer将Solr中的这行的数据更新成value1,导致HBase和Solr的数据不一致。另外,由于HBase是先写WAL再内存可见,在回读HBase过程中,Indexer也可能没有获取到最新数据导致Solr数据不一致。
同时HBase支持多family,多版本,自定义时间戳,各种类型的删除,Solr模型的支持比较有限,Indexer没有处理好这些问题,我们发现有多个case都会导致HBase和Solr的数据不一致,这里就不一一列举了。Indexer官方已经不再维护Indexer社区代码已经4年没有更新,所有的这些问题都不会再修复,这也是使用Indexer的最大风险,面对这些问题和bug,用户只能自行解决。
云HBase增强版(Lindorm)全文索引
通过分析应用双写和开源的Lily HBase Indexer存在的种种问题,Lindorm在研发全文索引功能时,从中吸取相关经验,进行创新的设计,使得宽表和检索两类引擎正确而自然的结合在一起,方便用户即开即用。
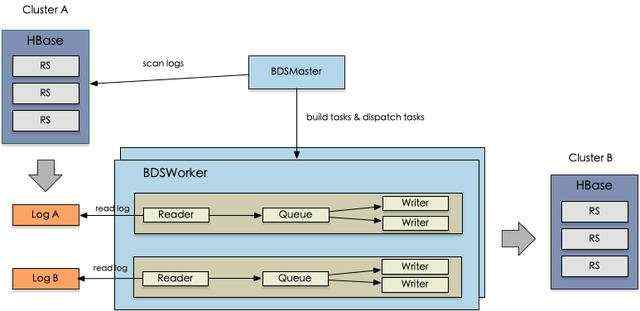
在此方案中,我们选用了自研的BDS组件做Lindorm的宽表引擎到Solr检索引擎间的数据同步。BDS是一个cloud native的HBase生态数据同步服务,可以提供高效的数据实时同步和全量迁移能力,关于BDS的介绍,用户可以参照《BDS - HBase数据迁移同步方案的设计与实践》一文(https://yq.aliyun.com/articles/704977 )。
在此方案中,我们使用BDS完美解决了Lindorm的宽表引擎和检索引擎Solr因为模型不一致,WAL乱序等等问题带来的数据不一致问题。不管用户是部分更新,多版本,自定义时间戳,多family写入,还是删除行、列,两个引擎之间的数据都不会产生不一致问题(具体的做法在申请专利中,专利申请完成后再专文对外分享)。同时整个系统采用分布式分层架构,各个组件之间可以独立自由伸缩,BDS服务、Lindorm的宽表引擎服务和检索引擎服务都具备无限的横向扩展能力,从而提供海量数据的无限存储和实时检索。在使用上, Lindorm全文索引功能非常简单易用,用户可以通过HBase Shell(Lindorm原生API暂未开放)就可以管理同步映射的Schema,BDS对于用户来说是完全透明的。不像在Lily HBase Indexer方案中,用户还需要和Indexer交互,管理schema。具体的操作大家可以参考全文索引使用快速入门的帮助(https://help.aliyun.com/document_detail/161121.html ),简单来说,用户只需要在HBase Shell中执行一条命令,就可以为数据列创建Solr索引
hbase shell> add_external_index_field 'testTable', {FAMILY => 'f', QUALIFIER => 'money', TARGETFIELD => 'money_f', TYPE => 'FLOAT' }
同时BDS还具有丰富的WebUI界面和监控和报警信息,用户可以非常方便地获取同步状态和报错信息。比如在云监控中,我们可以清晰地看到同步的延迟,同时可以通过订阅报警,随时发现异常。
最后是 阿里云HBase增强版(Lindorm)全文索引与其他方案的一个对比
方案双写Lily HBase IndexerLindorm全文索引同步效率受限于Solr受限于HBase Replication,扩展性差受限于Solr稳定性会影响HBase稳定性会影响HBase稳定性无影响数据一致性无法保证无法保证可以保证一致性Cloud NativeN/AN/A云原生,支持扩容,升级配置,同步通道可独立扩展,报警监控一应俱全
案例介绍
目前已经有非常多的公司和业务已经在线上使用Lindorm的全文索引。这里给大家介绍几个使用案例。
某快递公司包裹平台
该快递公司的包裹系统原来使用了Oracle,由于业务的增长Oracle的单表数据过大已经造成瓶颈,并且只能存储1个月的数据。在这么大规模的数据下,上万网点的分析查询已经慢到无法接受的程度。该公司采用了Lindorm全文索引的方案改造之后,不仅可以将可查数据扩展到6个月,在引入Solr做多维查询后,查询能力也比之前好了五倍。
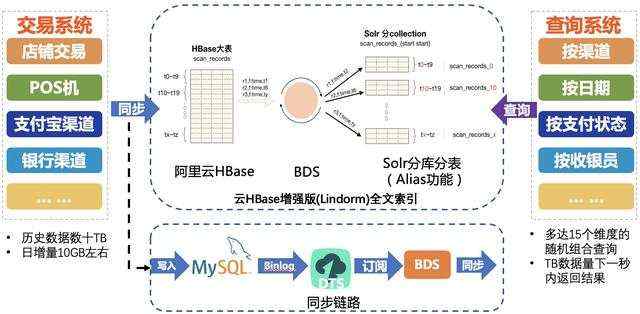
某O2O公司订单系统
该公司原来的订单查询系统使用了DRDS分库分表,由于订单量巨大,DRDS分32个库都已经只能放下6个月的订单数据。而该公司希望查询系统能够查询所有订单数据。同时由于查询时有多达15个维度条件的随机组合查询,传统的二级索引方案已经无法满足要求。在选用了Lindorm全文索引方案后,得益于Lindorm的海量存储能力,一个表就能放下所有历史数据。由于单个Solr的表索引数据不宜过大,因此该业务使用了我们推荐的Solr分库分表功能(Alias功能),Lindorm宽表存储中的数据自动增量同步到不同的Solr Collection中(按时间分割),在查询时,无需查询全量Solr数据,只需要根据时间维度查询少量Solr Collection。在新方案下,该公司不仅实现了能够在线查询所有历史数据,还能秒级返回查询结果。
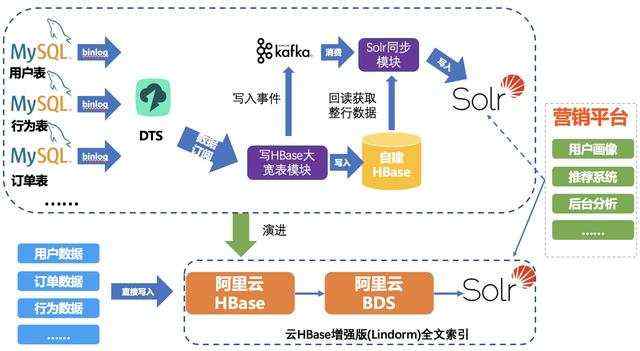
某在线教育公司营销平台
该公司原来的营销平台直接基于MySQL,由于MySQL列不能太多,只能把各个系统的数据分布在多张表内,然后再采用DTS同步的方式,订阅Binlog,再写入到自建HBase的大宽表中。然后把写入事件记在Kafka上,再消费Kafka的消息,回读HBase数据同步到Solr中,最后提供给营销系统使用。整个链路非常长,组件非常多,难以维护,容易出稳定性问题。在使用了Lindorm的全文索引方案后,仅仅使用了一个Lindorm就解决了所有的问题,简单易运维,同时获得了 Cloud native的能力,各个组件都可以无限水平扩展和扩容。
总结阿里云Lindorm全文索引方案给广大用户提供了存储与检索的一站式解决能力,相比之前的方案,不仅简单易用,容易维护,同时能够利用Cloud Native的特性解决一系列运维上的难题。在技术上,阿里云Lindorm使用了一种高性能,低延迟的异构存储同步方案,避免了之前一些方案的性能问题,并完美地解决了宽表引擎和检索引擎的模型差异所带来的数据不一致的问题,在后续的计划中,Lindorm还将提供统一的多维查询能力,系统会自动利用Solr索引对多条件查询加速,而无需应用显示地访问Solr,进一步优化使用体验。目前,有大量的公司和用户已经基于此功能打造了他们的在线查询和离线分析系统,欢迎更多的用户前来试用。
产品主页:HBase云数据库-Hadoop-HBase教程-HBase安装-HBase sql-PB级大数据 - 阿里云
产品使用帮助:服务介绍_快速入门_HBase Solr 全文引擎_云数据库 HBase-阿里云












 京公网安备 11010802041100号
京公网安备 11010802041100号