作者:霍任芳 | 来源:互联网 | 2024-09-27 20:57
JDK1.71.数据结构: 数组+链表2.put过程中发生hash碰撞是如何处理的?答:使用“头插法”:将新数据插入当前数组,数组中原数据向链表下(纵向)移动
JDK1.7
1. 数据结构: 数组+链表
2. put过程中发生hash碰撞是如何处理的?
答: 使用 “头插法” :将 新数据 插入当前数组,数组中 原数据 向 链表下(纵向)移动
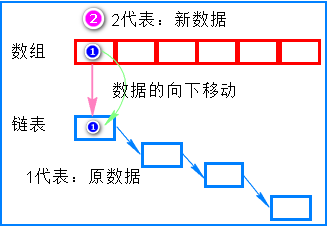
3. “头插法” 出现的问题?
答1: 如果一直发生hash碰撞,那么链表就会向下无限的增加下去,链表会变的很长。
众所周知,链表的特点是:增删快,查询慢。若果链表很长,那么查询就更慢了。
答2:在多线程的情况下,同一索引位置的节点在扩容后 链表会变成环状 ,导致出现死循环的情况。
4.什么是hash碰撞?
答: 两个不同的值(如:张三 、李四),经过hash计算后,得到相同的hash值,后来李四要放到原来张三的位置,但是数组的位置已经被张三占用了,导致的冲突。
JDK1.8
1. 数据结构: 数组+链表+红黑树
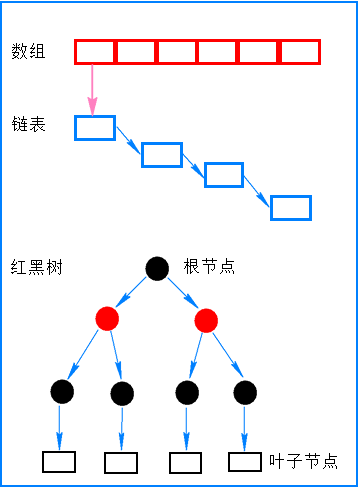
2. put 过程中发生 hash碰撞是如何处理的?
答: 使用 “尾插法” : 将 新数据 插入当前链表的尾部,使其成为当前链表尾节点。
3. “尾插法” 解决的问题
答: 解决“头插法”处出现的死循环
4. 为什么使用“红黑树”?
答: 主要是为了提升在hash冲突时(链表过长)的查找性能,使用链表查找性能是O(n) ,使用红黑树查找性能是O(logn) , 提高了查询效率
5. 什么时候 链表 转 红黑树?
答:当 链表 长度 大于等于 8 时,由 链表 转成 红黑树
6. 什么时候 红黑树 转 链表?
答:当 红黑树上节点数小于等于6时,由 红黑树 转成 链表
7. hashmap 什么时候进行扩容 (数组空间不够,需要进行扩容) ?
答: 数组的默认长度是 :16 扩容因子是 :0.75
16 * 0.75=12 数组长度使用到12的时候开始扩容
8. hashmap 是如何扩容的?
答: 底层是 数组,那么数组是如何扩容的呢?
寻找一个长度是原数组2倍的新数组进行扩容。
为什么数组扩容是2倍呢?
2倍满足,扩容一定的 2的次方 默认要求 ,
满足这个条件 有利于 计算生成的 hash值 放到hashmap数组中的值(value)更加均匀。
9. hashmap的put(添加)方法流程
答: 1. 调用put() 方法 -->底层 调用hashmap类的putval() 方法

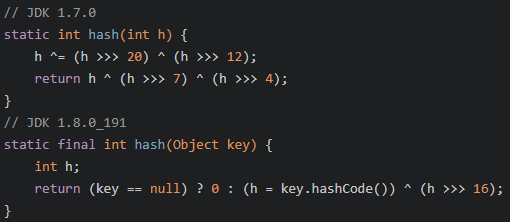
2. 首先 根据 key 进行hash运算

用 key 的 hashCode 与 key的hashcode 右移16位做 异或运算
3.然后
10. 为什么要做hash运算?
答:查看源码可以看出,通过key计算出 hash值是为了后续key和value放入数组中的位置
hash值与数组的长度进行计算,放到对应的数组中
存放到数组中的位置 = key计算出hash值 & n ( hash值 % 数组的长度(16) = 下标 )
11. hashmap的重要属性以及有哪些作用?
答: <1> size:hashmap已经存储的节点数
<2> threshold:扩容阈值,当hashmap的个数达到该值,触发扩容
<3> loadFactor:负载因子,扩容阈值=容量*负载因子
12.
总结JDK1.8有哪些优化?
1. 数据结构:
由“数组+链表” 改成 “数组+链表+红黑树”,主要是优化hash冲突严重时,链表过长的查找性能
2. 扩容:
由“头插法” 改成 “尾插法”,避免了并发下的死循环
3. hsah计算:
1.8只是简单的进行高16位参与运算
4. 其他:
目前还不太清楚
结束语:
好了,目前小编的技术能力就到这里了,其他问题正在努力学习中......












 京公网安备 11010802041100号
京公网安备 11010802041100号