作者:手机用户2502908277 | 来源:互联网 | 2023-08-11 14:02
在上一遍博文中,已经将hadoop集群环境搭建完毕。那么,接下来,笔者再根据安装过程中的一些名词对象进行解释,以及大致的运行原理。最后,再获取hadoop-example jar中的单词计数源码,进行解释并在hadoop环境中运行。
一、hadoop基本概念
hadoop包括两个核心组成:
HDFS:分布式文件系统,存储海量的数据
MapReduce:并行处理框架,实现任务分解和调度。
整个HDFS三个重要角色:NameNode、DataNode和Client。NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据。第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Scheme,ML 等。MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。
二、hadoop运行机制
关于hadoop的运行机制,这里由于笔者还没真正弄透彻,只是知道一个大致的处理思想。下面就贴几张比较形象的图片:
HDFS:
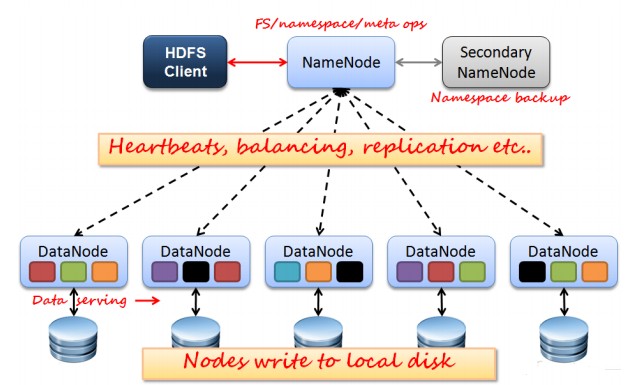
文件写入:
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取:
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的DataNode的信息。
Client读取文件信息。
文件Block复制:
NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。
通知DataNode相互复制Block。
DataNode开始直接相互复制。
MapReduce工作原理:
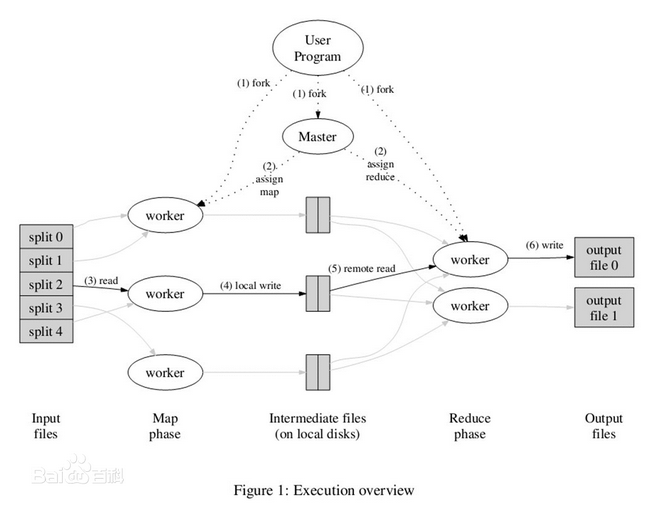
一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。
MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4(文件块);然后使用fork将用户进程拷贝到集群内其它机器上。
user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或Reduce作业),worker数量可由用户指定的。
被分配了Map作业的worker,开始读取对应文件块的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业(包含多个map函数)从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
缓存的中间键值对会被定期写入本地磁盘。主控进程知道Reduce的个数,比如R个(通常用户指定)。然后主控进程通常选择一个哈希函数作用于键并产生0~R-1个桶编号。Map任务输出的每个键都被哈希起作用,根据哈希结果将Map的结果存放到R个本地文件中的一个(后来每个文件都会指派一个Reduce任务)。
master通知分配了Reduce作业的worker它负责的分区在什么位置。当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
函数说明 pid_t fork( void)
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。
这里关于hadoop的原理参考了以下两篇博文:
HDFS的运行原理:http://www.cnblogs.com/laov/p/3434917.html,
MapReduce工作原理:http://www.cnblogs.com/kaituorensheng/p/3958862.html
三、单词统计源码分析
这里,笔者搭建一个简单的maven项目,添加hadoop依赖,将hadoop src下的单词计数代码迁移过来,稍作修改,结构如下:
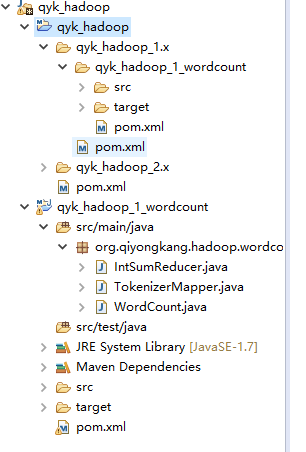
pom.xml:
<project xsi:schemaLocation&#61;"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns&#61;"http://maven.apache.org/POM/4.0.0"xmlns:xsi&#61;"http://www.w3.org/2001/XMLSchema-instance"><modelVersion>4.0.0modelVersion><parent><groupId>org.qiyongkang.hadoopgroupId><artifactId>qyk_hadoop_1.xartifactId><version>0.0.1-SNAPSHOTversion>parent><groupId>org.qiyongkang.hadoopgroupId><artifactId>qyk_hadoop_1_wordcountartifactId><version>0.0.1-SNAPSHOTversion><name>qyk_hadoop_1_wordcountname><url>http://maven.apache.orgurl><properties><project.build.sourceEncoding>UTF-8project.build.sourceEncoding>properties><dependencies><dependency><groupId>junitgroupId><artifactId>junitartifactId><version>3.8.1version><scope>testscope>dependency>dependencies><build><plugins><plugin><groupId>org.apache.maven.pluginsgroupId><artifactId>maven-jar-pluginartifactId><version>2.4version><configuration><archive><manifest><addClasspath>falseaddClasspath><classpathPrefix>lib/classpathPrefix><mainClass>org.qiyongkang.hadoop.wordcount.WordCountmainClass>manifest>archive>configuration>plugin>plugins>build>
project>
然后&#xff0c;再来看看主类WordCount.java&#xff1a;
package org.qiyongkang.hadoop.wordcountimport org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
import org.apache.hadoop.util.GenericOptionsParserpublic class WordCount {public static void main(String[] args) throws Exception {Configuration conf &#61; new Configuration()String[] otherArgs &#61; new GenericOptionsParser(conf, args).getRemainingArgs()//如果没有两个输入参数&#xff0c;则不执行if (otherArgs.length !&#61; 2) {System.err.println("Usage: wordcount ")System.exit(2)}//创建一个作业Job job &#61; new Job(conf, "word count")//设置job的main classjob.setJarByClass(WordCount.class)//设置Mapperjob.setMapperClass(TokenizerMapper.class)//在MapReduce中&#xff0c;当map生成的数据过大时&#xff0c;带宽就成了瓶颈&#xff0c;怎样精简压缩传给Reduce的数据&#xff0c;有不影响最终的结果呢。//有一种方法就是使用Combiner&#xff0c;Combiner号称本地的Reduce&#xff0c;Reduce最终的输入&#xff0c;是Combiner的输出job.setCombinerClass(IntSumReducer.class)//设置Reducerjob.setReducerClass(IntSumReducer.class)//设置输出key和value的类型job.setOutputKeyClass(Text.class)job.setOutputValueClass(IntWritable.class)//设置输入文件所在路径FileInputFormat.addInputPath(job, new Path(otherArgs[0]))//设置输出结果所在路径FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]))System.exit(job.waitForCompletion(true) ? 0 : 1)}
}
再就是Mapper类&#xff1a;
package org.qiyongkang.hadoop.wordcount;import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;/*** ClassName:TokenizerMapper
* Function: 分.
* Date: 2016年2月23日 下午3:20:19
* &#64;author qiyongkang* &#64;version * &#64;since JDK 1.6* &#64;see */
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one &#61; new IntWritable(1);private Text word &#61; new Text();&#64;Overrideprotected void map(Object key, Text value, Mapper.Context context)throws IOException, InterruptedException {StringTokenizer itr &#61; new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}
最后&#xff0c;就是Reducer类&#xff1a;
package org.qiyongkang.hadoop.wordcount;import java.io.IOException;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;/*** ClassName:IntSumReducer
* Date: 2016年2月23日 下午3:23:34
* &#64;author qiyongkang* &#64;version * &#64;since JDK 1.6* &#64;see */
public class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result &#61; new IntWritable();&#64;Overrideprotected void reduce(Text key, Iterable values,Reducer.Context context) throws IOException, InterruptedException {int sum &#61; 0;for (IntWritable val : values) {sum &#43;&#61; val.get();}result.set(sum);context.write(key, result);}}
相关的解释已在注解中标明。
然后&#xff0c;运行mvn package便可打成jar包&#xff0c;再将此包上传到服务器&#xff0c;这里笔者放在200服务器的/root目录下。
四、运行单词统计并查看作业运行状态
启动hadoop后&#xff0c;运行hadoop jar /root/qyk_hadoop_1_wordcount-0.0.1-SNAPSHOT.jar input output&#xff0c;可以看到&#xff1a;
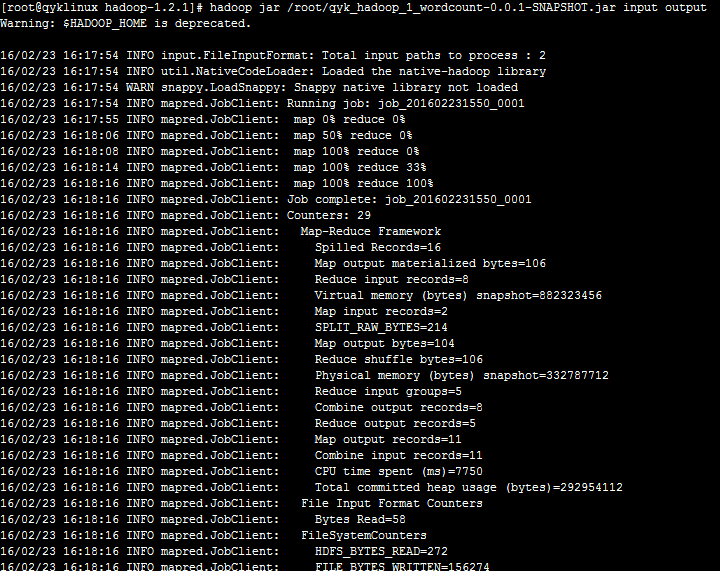 &#xff0c;
&#xff0c;
然后&#xff0c;运行hadoop fs -cat output/*&#xff0c;查看统计结果&#xff1a;
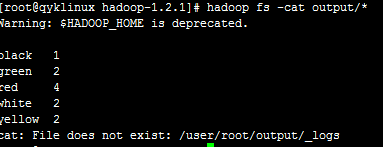 &#xff0c;
&#xff0c;
最后访问http://172.31.26.200:50030/可以查看此次job运行的情况&#xff1a;
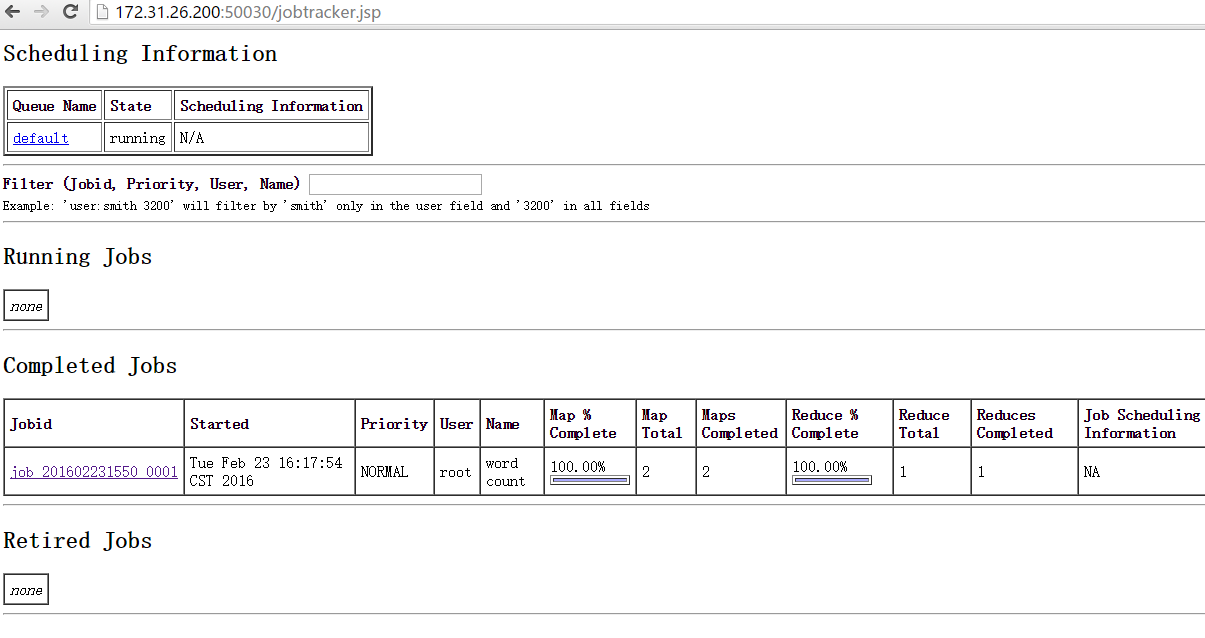
还可以点击查看任务运行详情&#xff1a;
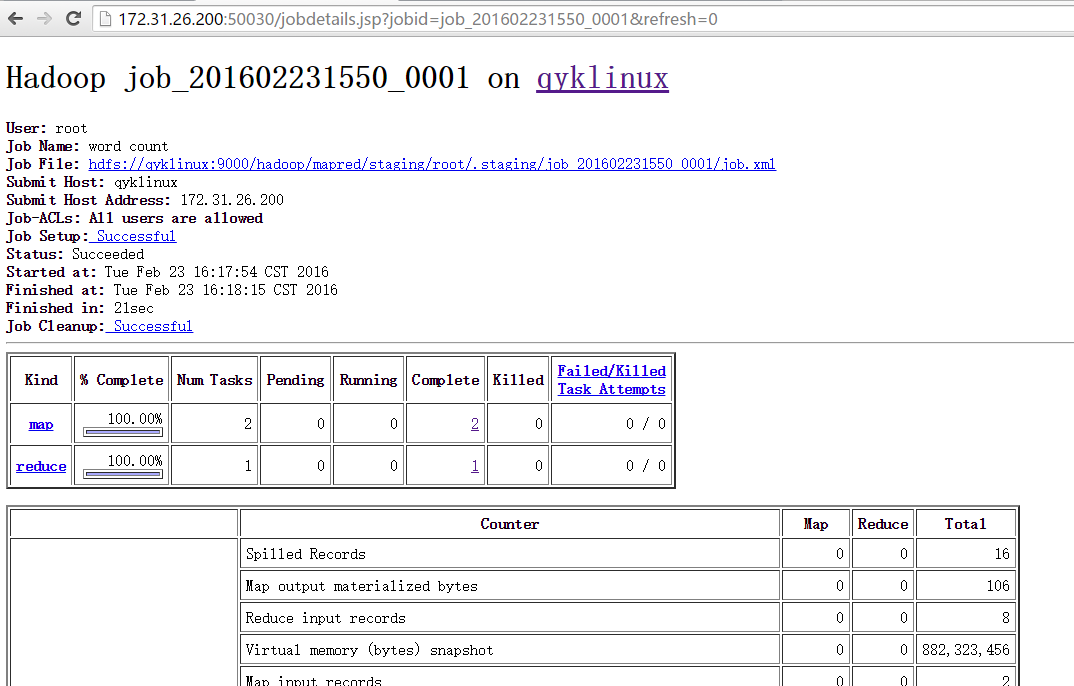
好了&#xff0c;今天就介绍到这儿了。







 京公网安备 11010802041100号
京公网安备 11010802041100号