1)实验平台:alientek NANO STM32F411 V1开发板
2)摘自《正点原子STM32F4 开发指南(HAL 库版》关注官方微信号公众号,获取更多资料:正点原子
第三十一章 FPU 测试(Julia)实验
本章,我们将向大家介绍如何开启 STM32F4 的硬件 FPU,并对比使用硬件 FPU 和不使用硬件 FPU 的速度差别,以体现硬件 FPU 的优势。本章分为如下几个部:
31.1 FPU&Julia 分形简介
31.2 硬件设计
31.3 软件设计
31.4 下载验证
31.1 FPU&Julia 分形简介
本节将分别介绍 STM32F4 的 FPU 和 Julia 分形。
31.1.1 FPU 简介
FPU 即浮点运算单元(Float Point Unit)。浮点运算,对于定点 CPU(没有 FPU 的 CPU)来说必须要按照 IEEE-754 标准的算法来完成运算,是相当耗费时间的。而对于有 FPU 的 CPU来说,浮点运算则只是几条指令的事情,速度相当快。
STM32F4 属于 Cortex M4F 架构,带有 32 位单精度硬件 FPU,支持浮点指令集,相对于
Cortex M0 和 Cortex M3 等,高出数十倍甚至上百倍的运算性能。
STM32F4 硬件上要开启 FPU 是很简单的,通过一个叫:协处理器控制寄存器(CPACR)
的寄存器设置即可开启 STM32F4 的硬件 FPU,该寄存器各位描述如图 31.1.1.1 所示:
图 31.1.1.1 协处理器控制寄存器(CPACR)各位描述
这里我们就是要设置 CP11 和 CP10 这 4 个位,复位后,这 4 个位的值都为 0,此时禁止访问协处理器(禁止了硬件 FPU),我们将这 4 个位都设置为 1,即可完全访问协处理器(开启硬件 FPU),此时便可以使用 STM32F4 内置的硬件 FPU 了。CPACR 寄存器这 4 个位的设置,我们在 startup_stm32f411xe.s 文件里面开启,代码如下:
LDR
R0, =0xE000ED88
; 使能浮点运算 CP10,CP11
LDR
R1,[R0]
ORR
R1,R1,#(0xF <<20)
STR
R1,[R0]
此部分代码是 Reset_Handler 函数的部分内容,功能就是设置 CPACR 寄存器的 20~23 位为1,以开启 STM32F4 的硬件 FPU 功能。
但是,仅仅开启硬件 FPU 是不够的,我们还需要在编译器上面,做一下设置,否则编译器遇到
浮点运算,还是采用传统的方式(IEEE-754 标准)完成运算,不能体现硬件浮点运算的优势。
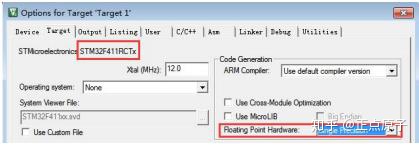
这里,我们在 MDK5 编译器里面,点击 按钮,然后在 Target 选项卡里面,设置 Floating Point
Hardware 为 Use FPU,如图 31.1.1.2 所示:
图 31.1.1.2 编译器开启硬件 FPU 选项
经过这个设置,编译器遇到浮点运算就会使用硬件 FPU 相关指令,执行浮点运算,从而大
大减少计算时间。
最后,总结下 STM32F4 硬件 FPU 使用的要点:
1, 设置 CPACR 寄存器 bit20~23 为 1,使能硬件 FPU。
2, MDK 编译器 Code Generation 里面设置:Use FPU。
经过这两步设置,我们的编写的浮点运算代码,即可使用 STM32F4 的硬件 FPU 了,可以
大大加快浮点运算速度。
31.1.2 Julia 分形简介
Julia 分形即 Julia 集,它最早由法国数学家 Gaston Julia 发现,因此命名为 Julia(朱利亚)
集。Julia 集合的生成算法非常简单:对于复平面的每个点,我们计算一个定义序列的发散速度。
该序列的 Julia 集计算公式为:
zn+1 = zn2 + c
针对复平面的每个 x + i.y 点,我们用 c = cx + i.cy 计算该序列:
xn+1 + i.yn+1 = xn2 - yn2 + 2.i.xn.yn + cx + i.cy
xn+1 = xn2 - yn2 + cx 且 yn+1 = 2.xn.yn + cy
一旦计算出的复值超出给定圆的范围(数值大小大于圆半径),序列便会发散,达到此限
值时完成的迭代次数与该点相关。随后将该值转换为颜色,以图形方式显示复平面上各个点的
分散速度。
经过给定的迭代次数后,若产生的复值保持在圆范围内,则计算过程停止,并且序列也不
发散,本例程生成 Julia 分形图片的代码如下:
#define
ITERATION
128
//迭代次数
#define
REAL_CONSTANT
0.285f
//实部常量
#define
IMG_CONSTANT
0.01f
//虚部常量
//产生 Julia 分形图形
//size_x,size_y:屏幕 x,y 方向的尺寸
//offset_x,offset_y:屏幕 x,y 方向的偏移
//zoom:缩放因子
void GenerateJulia_fpu(u16 size_x,u16 size_y,u16 offset_x,u16 offset_y,u16 zoom)
{
u8 i;
u16 x, y;
float tmp1, tmp2;
float num_real, num_img;
float radius;
for(y = 0; y {
for(x = 0; x {
num_real = y - offset_y;
num_real = num_real / zoom;
num_img = x - offset_x;
num_img = num_img / zoom;
i = 0;
radius = 0;
while((i {
tmp1 = num_real * num_real;
tmp2 = num_img * num_img;
num_img = 2 * num_real * num_img + IMG_CONSTANT;
num_real = tmp1 - tmp2 + REAL_CONSTANT;
radius = tmp1 + tmp2;
i++;
}
lcdbuf[LCD_Width - x - 1] = color_map[i]; //保存颜色值到 lcdbuf
}
LCD_Fill_Buf(0, y, LCD_Width - 1, y, lcdbuf); //DM2D 填充
}
}
这种算法非常有效地展示了 FPU 的优势:无需修改代码,只需在编译阶段激活或禁止
FPU(在 MDK Code Generation 里面设置:Use FPU/Not Used),即可测试使用硬件 FPU 和不
使用硬件 FPU 的差距。
31.2 硬件设计
本章实验功能简介:开机后,根据迭代次数生成颜色表(RGB565),然后计算 Julia 分形,
并显示到 LCD 上面。同时,程序开启了定时器 3,用于统计一帧所要的时间(ms),在一帧
Julia 分形图片显示完成后,程序会显示运行时间、当前是否使用 FPU 和缩放因子(zoom)等
信息,方便观察对比。KEY0/KEY2 用于调节缩放因子,KEY_UP 用于设置自动缩放,还是手
动缩放。DS0 用于提示程序运行状况。
本实验用到的资源如下:
1,指示灯 DS0
2,三个按键(KEY_UP/KEY0/KEY2)
3,串口
4,TFTLCD 模块
这些前面都已介绍过。
31.3 软件设计
本章代码,分成两个工程:
1,实验 26_1 FPU 测试(Julia 分形)实验_开启硬件 FPU
2,实验 26_2 FPU 测试(Julia 分形)实验_关闭硬件 FPU
这两个工程的代码一模一样,只是前者使用硬件 FPU 计算 Julia 分形集(MDK 设置 Use
FPU),后者使用 IEEE-754 标准计算 Julia 分形集(MDK 设置 Not Used)。由于两个工程代码
一模一样,我们这里仅介绍其中一个:实验 26_1 FPU 测试(Julia 分形)实验_开启硬件 FPU。
本章代码,我们在 TFTLCD 显示实验的基础上修改,打开 TFTLCD 显示实验的工程,由
于要统计帧时间和按键设置,所以在 HARDWARE 组下加入 timer.c 和 key.c 两个文件。
本章不需要添加其他.c 文件,所有代码均在 test.c 里面实现,整个代码如下:
本章代码,我们在 TFTLCD 显示实验的基础上修改,打开 TFTLCD 显示实验的工程,由
于要统计帧时间和按键设置,所以在 HARDWARE 组下加入 timer.c 和 key.c 两个文件。
本章不需要添加其他.c 文件,所有代码均在 test.c 里面实现,整个代码如下:
//26_1,本版本为开启硬件 FPU 版本.
//FPU 模式提示
#if __FPU_USED==1
#define SCORE_FPU_MODE
"FPU On"
#else
#define SCORE_FPU_MODE
"FPU Off"
#endif
#define
ITERATION
128
//迭代次数
#define
REAL_CONSTANT
0.285f
//实部常量
#define
IMG_CONSTANT
0.01f
//虚部常量
//颜色表
u16 color_map[ITERATION];
//缩放因子列表
const u16 zoom_ratio[] =
{
120, 110, 100, 150, 200, 275, 350, 450,
600, 800, 1000, 1200, 1500, 2000, 1500,
1200, 1000, 800, 600, 450, 350, 275, 200,
150, 100, 110,
};
//初始化颜色表
//clut:颜色表指针
void InitCLUT(u16 * clut)
{
u32 i=0x00;
u16 red=0,green=0,blue=0;
for(i=0;i{
//产生 RGB 颜色值
red=(i*8*256/ITERATION)%256;
green=(i*6*256/ITERATION)%256;
blue=(i*4*256 /ITERATION)%256;
//将 RGB888,转换为 RGB565
red=red>>3;
red=red<<11;
green=green>>2;
green=green<<5;
blue=blue>>3;
clut[i]=red+green+blue;
}
}
u16 lcdbuf[800]; //RGB LCD 缓存
//产生 Julia 分形图形
//size_x,size_y:屏幕 x,y 方向的尺寸
//offset_x,offset_y:屏幕 x,y 方向的偏移
//zoom:缩放因子
void GenerateJulia_fpu(u16 size_x,u16 size_y,u16 offset_x,u16 offset_y,u16 zoom)
{
u8 i;
u16 x, y;
float tmp1, tmp2;
float num_real, num_img;
float radius;
for(y = 0; y {
for(x = 0; x {
num_real = y - offset_y;
num_real = num_real / zoom;
num_img = x - offset_x;
num_img = num_img / zoom;
i = 0;
radius = 0;
while((i {
tmp1 = num_real * num_real;
tmp2 = num_img * num_img;
num_img = 2 * num_real * num_img + IMG_CONSTANT;
num_real = tmp1 - tmp2 + REAL_CONSTANT;
radius = tmp1 + tmp2;
i++;
}
lcdbuf[LCD_Width - x - 1] = color_map[i]; //保存颜色值到 lcdbuf
}
LCD_Fill_Buf(0, y, LCD_Width - 1, y, lcdbuf); //DM2D 填充
}
}
u8 timeout;
int main(void)
{
u8 key;
u8 i = 0;
u8 autorun = 0;
float time;
char buf[50];
HAL_Init();
//初始化 HAL 库
Stm32_Clock_Init(96,4,2,4);
//设置时钟,96Mhz
delay_init(96);
//初始化延时函数
uart_init(115200);
//初始化串口 115200
LED_Init();
//初始化 LED
KEY_Init();
//按键初始化
LCD_Init();
//LCD 初始化
TIM3_Init(65536-1,9600-1);
//10Khz 的计数频率,最大计时 6.5 秒超出
InitCLUT(color_map);
//初始化颜色表
while(1)
{
key = KEY_Scan(0);
switch(key)
{
case KEY0_PRES:
i++;
if(i > sizeof(zoom_ratio) / 2 - 1)i = 0; //限制范围
break;
case KEY2_PRES:
if(i)i--;
else i = sizeof(zoom_ratio) / 2 - 1;
break;
case WKUP_PRES:
autorun = !autorun; //自动/手动
break;
}
if(autorun == 1) //自动时,自动设置缩放因子
{
i++;
if(i > sizeof(zoom_ratio) / 2 - 1)i = 0; //限制范围
}
TIM3->CNT=0;//重设 TIM3 定时器的计数器值
timeout = 0;
GenerateJulia_fpu(LCD_Width, LCD_Height, LCD_Width / 2,
LCD_Height / 2, zoom_ratio[i]);
time=TIM3->CNT+(u32)timeout*65536;
sprintf((char*)buf, "%s: zoom:%d runtime:%0.1fmsrn",
SCORE_FPU_MODE, zoom_ratio[i], time / 10);
LCD_ShowString(5, LCD_Height - 5 - 12, LCD_Width - 5, 12, 12, buf);
//显示当前运行情况
printf("%s", buf); //输出到串口
LED0=~LED0;
}
}
这里面,总共 3 个函数:InitCLUT、GenerateJulia_fpu 和 main 函数。
InitCLUT 函数,该函数用于初始化颜色表,该函数根据迭代次数(ITERATION)计算出颜
色表,这些颜色值将显示在 TFTLCD 上。
GenerateJulia_fpu 函数,该函数根据给定的条件计算 Julia 分形集,当迭代次数大于等于ITERATION 或者半径大于等于 4 时,结束迭代,并在 TFTLCD 上面显示迭代次数对应的颜色值,从而得到漂亮的 Julia 分形图。我们可以通过修改 REAL_CONSTANT 和 IMG_CONSTANT这两个常量的值来得到不同的 Julia 分形图。
main 函数,完成我们在 31.2 节所介绍的实验功能,代码比较简单。这里我们用到一个缩放因子表:zoom_ratio,里面存储了一些不同的缩放因子,方便演示效果。
最后,为了提高速度,同上一章一样,我们在 MDK 里面选择使用-O2 优化,优化代码速度,本例程代码就介绍到这里。
再次提醒大家:本例程两个代码(实验 26_1 和实验 26_2)程序是完全一模一样的,他们的区别就是 MDKOptions for Target ‘Target1’Target 选项卡Floating Point Hardware 的设置不一样,当设置 Use FPU 时,使用硬件 FPU;当设置 Not Used 时,不使用硬件 FPU。分别下载这两个代码,通过屏幕显示的 runtime 时间,即可看出速度上的区别。
31.4 下载验证
代码编译成功之后,下载本例程任意一个代码(这里以 26_1 为例)到 NANO STM32F4 开
发板上,可以看到 LCD 显示 Julia 分形图,并显示相关参数,如图 31.4.1 所示:
图 31.4.1 Julia 分形显示效果
实验 26_1 是开启了硬件 FPU 的,所以显示 Julia 分形图片速度比较快。如果下载实验 26_2,
同样的缩放因子,会比实验 26_1 慢 9 倍左右,这与 ST 官方给出的 17 倍有点差距,这是因为
我们没有选择:Use MicroLIB(还是在 Target 选项卡设置),如果都勾选这个,则会发现:使
用硬件 FPU 的例程(实验 26_1)时间基本没变化,而不使用硬件 FPU 的例程(实验 26_2)则
速度变慢了很多,这样,两者相差差不多就是 17 倍了。因此可以看出,使用硬件 FPU 和不使用硬件 FPU 对比,同样的条件下,快了近 10 倍,充分体现了 STM32F4 硬件 FPU 的优势。







![[ipsec][strongswan]strongswan源码分析(五)plugin的配置文件的添加方法与管理架构解析](https://img2.php1.cn/3cdc5/3909/339/3e35aa3d77315ada.png)

 京公网安备 11010802041100号
京公网安备 11010802041100号