一、为什么要用到Flume
在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取从MySQL数据库增量抽取数据到HDFS,然后用HAWQ的外部表进行访问。这种方式只需要很少量的配置即可完成数据抽取任务,但缺点同样明显,那就是实时性。Sqoop使用MapReduce读写数据,而MapReduce是为了批处理场景设计的,目标是大吞吐量,并不太关心低延时问题。就像实验中所做的,每天定时增量抽取数据一次。
Flume是一个海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。Flume以流方式处理数据,可作为代理持续运行。当新的数据可用时,Flume能够立即获取数据并输出至目标,这样就可以在很大程度上解决实时性问题。
Flume是最初只是一个日志收集器,但随着flume-ng-sql-source插件的出现,使得Flume从关系数据库采集数据成为可能。下面简单介绍Flume,并详细说明如何配置Flume将MySQL表数据准实时抽取到HDFS。
二、Flume简介
1. Flume的概念
Flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到HDFS,简单来说flume就是收集日志的,其架构如图1所示。
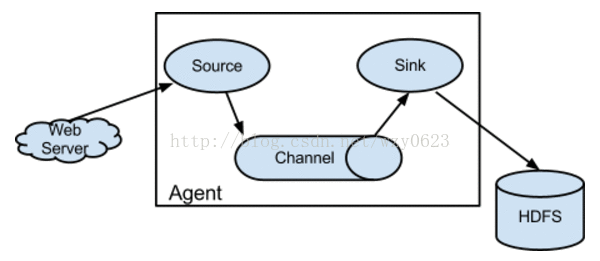
图1
2. Event的概念
在这里有必要先介绍一下Flume中event的相关概念:Flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,Flume再删除自己缓存的数据。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?Event将传输的数据进行封装,是Flume传输数据的基本单位,如果是文本文件,通常是一行记录。Event也是事务的基本单位。Event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。Event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
3. Flume架构介绍
Flume之所以这么神奇,是源于它自身的一个设计,这个设计就是agent。Agent本身是一个Java进程,运行在日志收集节点——所谓日志收集节点就是服务器节点。 Agent里面包含3个核心的组件:source、channel和sink,类似生产者、仓库、消费者的架构。
Source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
Channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
Sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、Hbase、solr、自定义。
4. Flume的运行机制
Flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接受数据输入的source,一个是数据输出的sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方,例如HDFS等。注意:只有在sink将channel中的数据成功发送出去之后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。
三、安装Hadoop和Flume
我的实验在HDP 2.5.0上进行,HDP安装中包含Flume,只要配置Flume服务即可。HDP的安装步骤参见“HAWQ技术解析(二) —— 安装部署”
四、配置与测试
1. 建立MySQL数据库表
建立测试表并添加数据。
use test;
create table wlslog
(id int not null,
time_stamp varchar(40),
category varchar(40),
type varchar(40),
servername varchar(40),
code varchar(40),
msg varchar(40),
primary key ( id )
);
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(1,'apr-8-2014-7:06:16-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to standby');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(2,'apr-8-2014-7:06:17-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to starting');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(3,'apr-8-2014-7:06:18-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to admin');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(4,'apr-8-2014-7:06:19-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to resuming');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(5,'apr-8-2014-7:06:20-pm-pdt','notice','weblogicserver','adminserver','bea-000361','started weblogic adminserver');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(6,'apr-8-2014-7:06:21-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to running');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(7,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode');
commit;
2. 建立相关目录与文件
(1)创建本地状态文件
mkdir -p /var/lib/flume
cd /var/lib/flume
touch sql-source.status
chmod -R 777 /var/lib/flume
(2)建立HDFS目标目录
hdfs dfs -mkdir -p /flume/mysql
hdfs dfs -chmod -R 777 /flume/mysql
3. 准备JAR包
从http://book2s.com/java/jar/f/flume-ng-sql-source/download-flume-ng-sql-source-1.3.7.html下载flume-ng-sql-source-1.3.7.jar文件,并复制到Flume库目录。
cp flume-ng-sql-source-1.3.7.jar /usr/hdp/current/flume-server/lib/
将MySQL JDBC驱动JAR包也复制到Flume库目录。
cp mysql-connector-java-5.1.17.jar /usr/hdp/current/flume-server/lib/mysql-connector-java.jar
4. 建立HAWQ外部表
create external table ext_wlslog
(id int,
time_stamp varchar(40),
category varchar(40),
type varchar(40),
servername varchar(40),
code varchar(40),
msg varchar(40)
) location ('pxf://mycluster/flume/mysql?profile=hdfstextmulti') format 'csv' (quote=e'"');
5. 配置Flume
在Ambari -> Flume -> Configs -> flume.conf中配置如下属性:
agent.channels.ch1.type = memory
agent.sources.sql-source.channels = ch1
agent.channels = ch1
agent.sinks = HDFS
agent.sources = sql-source
agent.sources.sql-source.type = org.keedio.flume.source.SQLSource
agent.sources.sql-source.connection.url = jdbc:mysql://172.16.1.127:3306/test
agent.sources.sql-source.user = root
agent.sources.sql-source.password = 123456
agent.sources.sql-source.table = wlslog
agent.sources.sql-source.columns.to.select = *
agent.sources.sql-source.incremental.column.name = id
agent.sources.sql-source.incremental.value = 0
agent.sources.sql-source.run.query.delay=5000
agent.sources.sql-source.status.file.path = /var/lib/flume
agent.sources.sql-source.status.file.name = sql-source.status
agent.sinks.HDFS.channel = ch1
agent.sinks.HDFS.type = hdfs
agent.sinks.HDFS.hdfs.path = hdfs://mycluster/flume/mysql
agent.sinks.HDFS.hdfs.fileType = DataStream
agent.sinks.HDFS.hdfs.writeFormat = Text
agent.sinks.HDFS.hdfs.rollSize = 268435456
agent.sinks.HDFS.hdfs.rollInterval = 0
agent.sinks.HDFS.hdfs.rollCount = 0
Flume在flume.conf文件中指定Source、Channel和Sink相关的配置,各属性描述如表1所示。
属性
描述
agent.channels.ch1.type
Agent的channel类型
agent.sources.sql-source.channels
Source对应的channel名称
agent.channels
Channel名称
agent.sinks
Sink名称
agent.sources
Source名称
agent.sources.sql-source.type
Source类型
agent.sources.sql-source.connection.url
数据库URL
agent.sources.sql-source.user
数据库用户名
agent.sources.sql-source.password
数据库密码
agent.sources.sql-source.table
数据库表名
agent.sources.sql-source.columns.to.select
查询的列
agent.sources.sql-source.incremental.column.name
增量列名
agent.sources.sql-source.incremental.value
增量初始值
agent.sources.sql-source.run.query.delay
发起查询的时间间隔,单位是毫秒
agent.sources.sql-source.status.file.path
状态文件路径
agent.sources.sql-source.status.file.name
状态文件名称
agent.sinks.HDFS.channel
Sink对应的channel名称
agent.sinks.HDFS.type
Sink类型
agent.sinks.HDFS.hdfs.path
Sink路径
agent.sinks.HDFS.hdfs.fileType
流数据的文件类型
agent.sinks.HDFS.hdfs.writeFormat
数据写入格式
agent.sinks.HDFS.hdfs.rollSize
目标文件轮转大小,单位是字节
agent.sinks.HDFS.hdfs.rollInterval
hdfs sink间隔多长将临时文件滚动成最终目标文件,单位是秒;如果设置成0,则表示不根据时间来滚动文件
agent.sinks.HDFS.hdfs.rollCount
当events数据达到该数量时候,将临时文件滚动成目标文件;如果设置成0,则表示不根据events数据来滚动文件
表1
6. 运行Flume代理
保存上一步的设置,然后重启Flume服务,如图2所示。
图2
重启后,状态文件已经记录了将最新的id值7,如图3所示。

图3
查看目标路径,生成了一个临时文件,其中有7条记录,如图4所示。

图4
查询HAWQ外部表,结果也有全部7条数据,如图5所示。
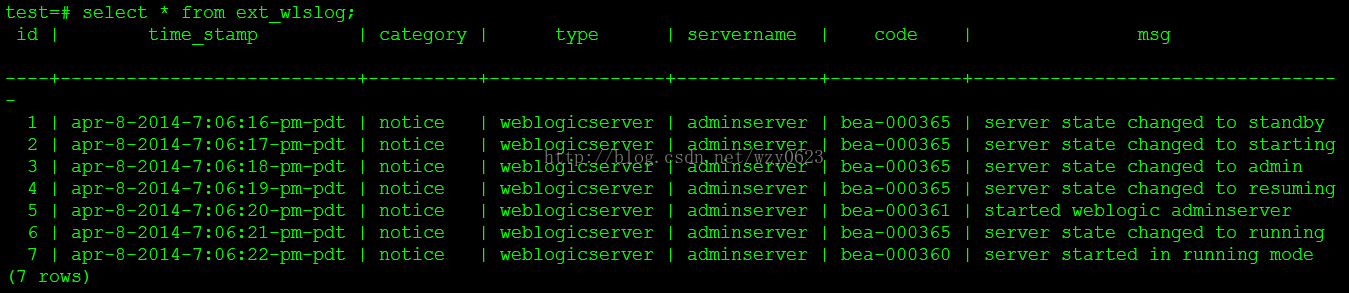
图5
至此,初始数据抽取已经完成。
7. 测试准实时增量抽取
在源表中新增id为8、9、10的三条记录。
use test;
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(8,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(9,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(10,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode');
commit;
5秒之后查询HAWQ外部表,从图6可以看到,已经查询出全部10条数据,准实时增量抽取成功。
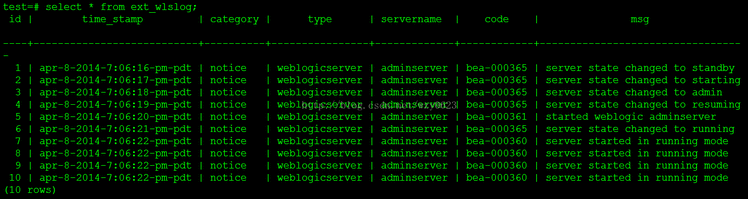
图6
五、方案优缺点
利用Flume采集关系数据库表数据最大的优点是配置简单,不用编程。相比tungsten-replicator的复杂性,Flume只要在flume.conf文件中配置source、channel及sink的相关属性,已经没什么难度了。而与现在很火的canal比较,虽然不够灵活,但毕竟一行代码也不用写。再有该方案采用普通SQL轮询的方式实现,具有通用性,适用于所有关系库数据源。
这种方案的缺点与其优点一样突出,主要体现在以下几方面。
在源库上执行了查询,具有入侵性。
通过轮询的方式实现增量,只能做到准实时,而且轮询间隔越短,对源库的影响越大。
只能识别新增数据,检测不到删除与更新。
要求源库必须有用于表示增量的字段。
即便有诸多局限,但用Flume抽取关系库数据的方案还是有一定的价值,特别是在要求快速部署、简化编程,又能满足需求的应用场景,对传统的Sqoop方式也不失为一种有效的补充。
参考:
Flume架构以及应用介绍
Streaming MySQL Database Table Data to HDFS with Flume
how to read data from oracle using FLUME to kafka broker
https://github.com/keedio/flume-ng-sql-source








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有