上周六在深圳分享了《Flink SQL 1.9.0 技术内幕和最佳实践》,会后许多小伙伴对最后演示环节的 Demo 代码非常感兴趣,迫不及待地想尝试下,所以写了这篇文章分享下这份代码。希望对于 Flink SQL 的初学者能有所帮助。完整分享可以观看 Meetup 视频回顾 :https://developer.aliyun.com/live/1416
这份代码主要由两部分组成:1) 能用来提交 SQL 文件的 SqlSubmit 实现。2) 用于演示的 SQL 示例、Kafka 启动停止脚本、 一份测试数据集、Kafka 数据源生成器。
通过本实战,你将学到:
如何使用 Blink Planner
一个简单的 SqlSubmit 是如何实现的
如何用 DDL 创建一个 Kafka 源表和 MySQL 结果表
运行一个从 Kafka 读取数据,计算 PVUV,并写入 MySQL 的作业
设置调优参数,观察对作业的影响
SqlSubmit 的实现
笔者一开始是想用 SQL Client 来贯穿整个演示环节,但可惜 1.9 版本 SQL CLI 还不支持处理 CREATE TABLE 语句。所以笔者就只好自己写了个简单的提交脚本。后来想想,也挺好的,可以让听众同时了解如何通过 SQL 的方式,和编程的方式使用 Flink SQL。
SqlSubmit 的主要任务是执行和提交一个 SQL 文件,实现非常简单,就是通过正则表达式匹配每个语句块。如果是 CREATE TABLE 或 INSERT INTO 开头,则会调用 tEnv.sqlUpdate(...)。如果是 SET 开头,则会将配置设置到 TableConfig 上。其核心代码主要如下所示:
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
// 创建一个使用 Blink Planner 的 TableEnvironment, 并工作在流模式
TableEnvironment tEnv = TableEnvironment.create(settings);
// 读取 SQL 文件
List sql = Files.readAllLines(path);
// 通过正则表达式匹配前缀,来区分不同的 SQL 语句
List calls = SqlCommandParser.parse(sql);
// 根据不同的 SQL 语句,调用 TableEnvironment 执行
for (SqlCommandCall call : calls) {
switch (call.command) {
case SET:
String key = call.operands[0];
String value = call.operands[1];
// 设置参数
tEnv.getConfig().getConfiguration().setString(key, value);
break;
case CREATE_TABLE:
String ddl = call.operands[0];
tEnv.sqlUpdate(ddl);
break;
case INSERT_INTO:
String dml = call.operands[0];
tEnv.sqlUpdate(dml);
break;
default:
throw new RuntimeException("Unsupported command: " + call.command);
}
}
// 提交作业
tEnv.execute("SQL Job");
使用 DDL 连接 Kafka 源表
在 flink-sql-submit 项目中,我们准备了一份测试数据集(来自阿里云天池公开数据集,特别鸣谢),位于 src/main/resources/user_behavior.log。数据以 JSON 格式编码,大概长这个样子:
{"user_id": "543462", "item_id":"1715", "category_id": "1464116", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}
{"user_id": "662867", "item_id":"2244074", "category_id": "1575622", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}
为了模拟真实的 Kafka 数据源,笔者还特地写了一个 source-generator.sh 脚本(感兴趣的可以看下源码),会自动读取 user_behavior.log 的数据并以默认每毫秒1条的速率灌到 Kafka 的 user_behavior topic 中。
有了数据源后,我们就可以用 DDL 去创建并连接这个 Kafka 中的 topic(详见 src/main/resources/q1.sql)。
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
ts TIMESTAMP
) WITH (
'connector.type' = 'kafka', -- 使用 kafka connector
'connector.version' = 'universal', -- kafka 版本,universal 支持 0.11 以上的版本
'connector.topic' = 'user_behavior', -- kafka topic
'connector.startup-mode' = 'earliest-offset', -- 从起始 offset 开始读取
'connector.properties.0.key' = 'zookeeper.connect', -- 连接信息
'connector.properties.0.value' = 'localhost:2181',
'connector.properties.1.key' = 'bootstrap.servers',
'connector.properties.1.value' = 'localhost:9092',
'update-mode' = 'append',
'format.type' = 'json', -- 数据源格式为 json
'format.derive-schema' = 'true' -- 从 DDL schema 确定 json 解析规则
)
注:可能有用户会觉得其中的 connector.properties.0.key 等参数比较奇怪,社区计划将在下一个版本中改进并简化 connector 的参数配置。
使用 DDL 连接 MySQL 结果表
连接 MySQL 可以使用 Flink 提供的 JDBC connector。例如
CREATE TABLE pvuv_sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT
) WITH (
'connector.type' = 'jdbc', -- 使用 jdbc connector
'connector.url' = 'jdbc:mysql://localhost:3306/flink-test', -- jdbc url
'connector.table' = 'pvuv_sink', -- 表名
'connector.username' = 'root', -- 用户名
'connector.password' = '123456', -- 密码
'connector.write.flush.max-rows' = '1' -- 默认5000条,为了演示改为1条
)
PV UV 计算
假设我们的需求是计算每小时全网的用户访问量,和独立用户数。很多用户可能会想到使用滚动窗口来计算。但这里我们介绍另一种方式。即 Group Aggregation 的方式。
INSERT INTO pvuv_sink
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv
FROM user_log
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00')
它使用 DATE_FORMAT 这个内置函数,将日志时间归一化成“年月日小时”的字符串格式,并根据这个字符串进行分组,即根据每小时分组,然后通过 COUNT(*) 计算用户访问量(PV),通过 COUNT(DISTINCT user_id) 计算独立用户数(UV)。这种方式的执行模式是每收到一条数据,便会进行基于之前计算的值做增量计算(如+1),然后将最新结果输出。所以实时性很高,但输出量也大。
我们将这个查询的结果,通过 INSERT INTO 语句,写到了之前定义的 pvuv_sink MySQL 表中。
注:在深圳 Meetup 中,我们有对这种查询的性能调优做了深度的介绍。
实战演示
环境准备
本实战演示环节需要安装一些必须的服务,包括:
Flink 本地集群:用来运行 Flink SQL 任务。
Kafka 本地集群:用来作为数据源。
MySQL 数据库:用来作为结果表。
Flink 本地集群安装
1.下载 Flink 1.9.0 安装包并解压:https://www.apache.org/dist/flink/flink-1.9.0/flink-1.9.0-bin-scala_2.11.tgz
2.下载以下依赖 jar 包,并拷贝到 flink-1.9.0/lib/ 目录下。因为我们运行时需要依赖各个 connector 实现。
3.将 flink-1.9.0/conf/flink-conf.yaml 中的 taskmanager.numberOfTaskSlots 修改成 10,因为我们的演示任务可能会消耗多于1个的 slot。
4.在 flink-1.9.0 目录下执行 ./bin/start-cluster.sh,启动集群。
运行成功的话,可以在 http://localhost:8081 访问到 Flink Web UI。
另外,还需要将 Flink 的安装路径填到 flink-sql-submit 项目的 env.sh 中,用于后面提交 SQL 任务,如我的路径是
FLINK_DIR=/Users/wuchong/dev/install/flink-1.9.0
Kafka 本地集群安装
将安装路径填到 flink-sql-submit 项目的 env.sh 中,如我的路径是
KAFKA_DIR=/Users/wuchong/dev/install/kafka_2.11-2.2.0
在 flink-sql-submit 目录下运行 ./start-kafka.sh 启动 Kafka 集群。
在命令行执行 jps,如果看到 Kafka 进程和 QuorumPeerMain 进程即表明启动成功。
MySQL 安装
$ docker pull mysql
$ docker run --name mysqldb -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -d mysql
然后在 MySQL 中创建一个 flink-test 的数据库,并按照上文的 schema 创建 pvuv_sink 表。
提交 SQL 任务
1.在 flink-sql-submit 目录下运行 ./source-generator.sh,会自动创建 user_behavior topic,并实时往里灌入数据。
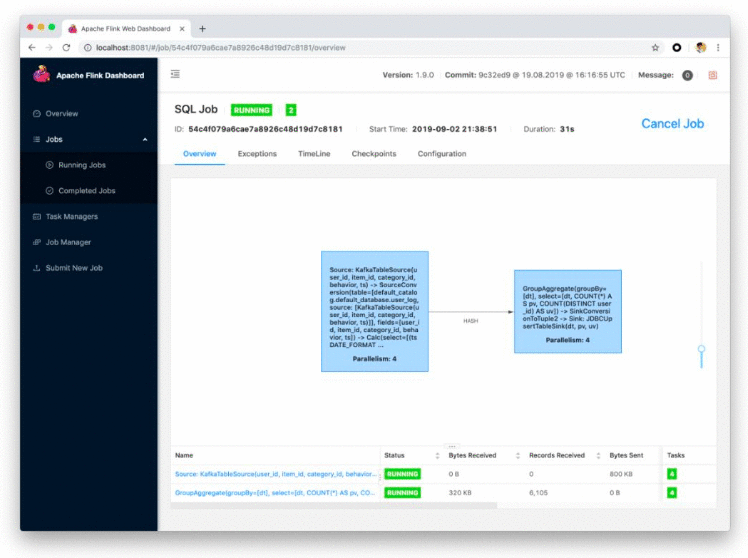
2.在 flink-sql-submit 目录下运行 ./run.sh q1, 提交成功后,可以在 Web UI 中看到拓扑。
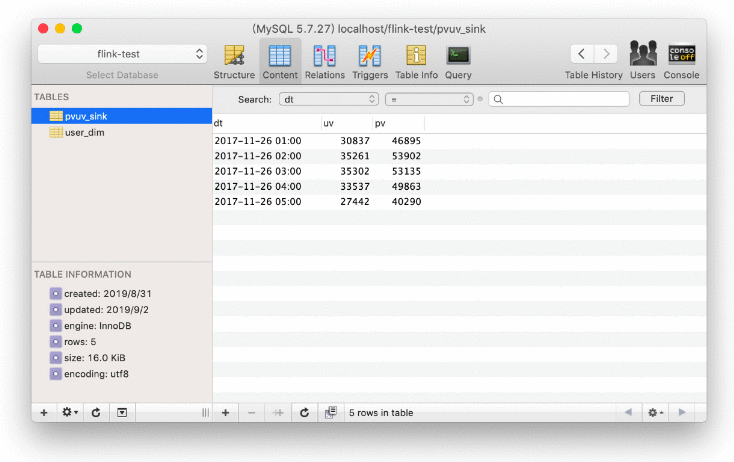
在 MySQL 客户端,我们也可以实时地看到每个小时的 pv uv 值在不断地变化
结尾
本文带大家搭建基础集群环境,并使用 SqlSubmit 提交纯 SQL 任务来学习了解如何连接外部系统。flink-sql-submit/src/main/resources/q1.sql 中还有一些注释掉的调优参数,感兴趣的同学可以将参数打开,观察对作业的影响。关于这些调优参数的原理,可以看下我在 深圳 Meetup 上的分享《Flink SQL 1.9.0 技术内幕和最佳实践》。
原文链接
本文为云栖社区原创内容,未经允许不得转载。







 京公网安备 11010802041100号
京公网安备 11010802041100号