作者:魅力无穷2 | 来源:互联网 | 2023-06-17 13:24
定位问题:如下图:1)flink的checkpoint生成超时,失败: checkpoint超时 2)查看jobmanager日志,定位问题: jobmanager日志 3)找大神
定位问题:
如下图:
1) flink的checkpoint生成超时, 失败:

checkpoint超时
2) 查看jobmanager日志,定位问题:

jobmanager日志
3) 找大神帮忙定位问题, 原来是出现了背压的问题, 缓冲区的数据处理不过来,barrier流动慢,导致checkpoint生成时间长, 出现超时的现象. (checkpoint超时时间设置了30分钟)
下图是背压过高, input 和 output缓冲区都占满的情况

buffer缓冲区情况
4) 背压的情况也可以在flink后台的job的JobGraph中查看

背压过高
下面说说flink感应反压的过程:
下面这张图简单展示了两个 Task 之间的数据传输以及 Flink 如何感知到反压的:

flink感知背压
记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程)
记录被序列化到 buffer 中。
该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录。
注意:记录能被 Flink 处理的前提是,必须有空闲可用的 Buffer。
结合上面两张图看:Task 1 在输出端有一个相关联的 LocalBufferPool(称缓冲池1),Task 2 在输入端也有一个相关联的 LocalBufferPool(称缓冲池2)。如果缓冲池1中有空闲可用的 buffer 来序列化记录 “A”,我们就序列化并发送该 buffer。
这里我们需要注意两个场景:
本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。
远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制来保证不往网络中写入太多数据(后面会说)。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。我们上面描述的这个方案可以从两个 Task 之间的数据传输自然地扩展到更复杂的 pipeline 中,保证反压机制可以扩散到整个 pipeline。
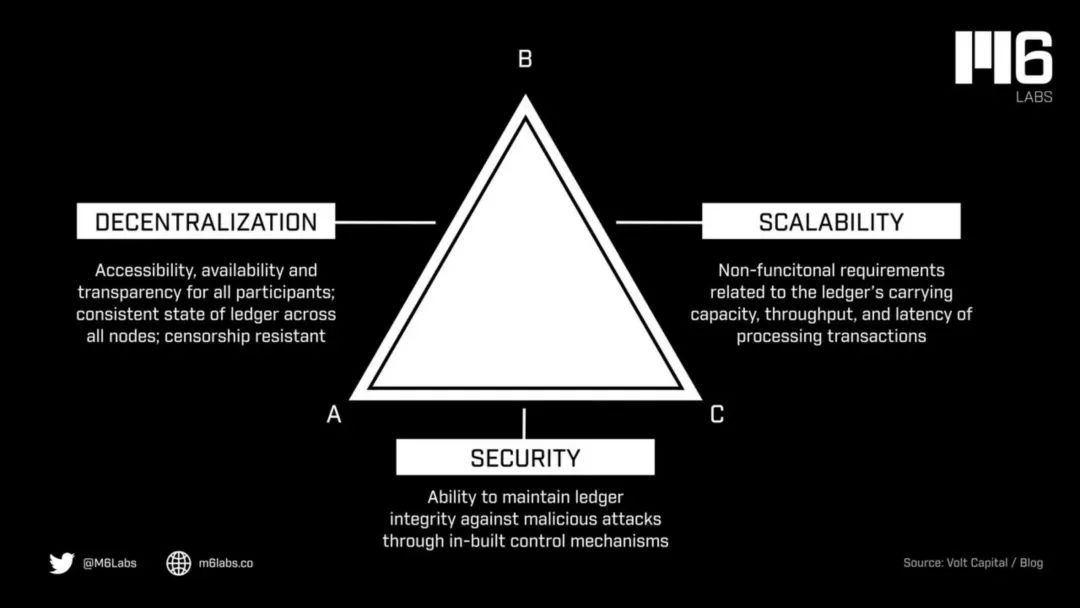
解决办法:
1) 首先说一下flink原来的JobGraph, 如下图, 产生背压的是中间的算子,

flink job graph
2) 背压是什么??
如果您看到任务的背压警告(例如High),这意味着它生成的数据比下游算子可以消耗的速度快。下游工作流程中的记录(例如从源到汇)和背压沿着相反的方向传播到流上方。
以一个简单的Source -> Sink工作为例。如果您看到警告Source,这意味着Sink消耗数据的速度比Source生成速度慢。Sink正在向上游算子施加压力Source。
可以得出: 第三个算子的处理数据速度比第二个算子生成数据的速度, 明显的解决方法: 提高第三个算子的并发度, 问题又出现了: 并发度要上调到多少呢?
3) 第一次上调, 从原来的10并发 上调到 40
观察缓存池对比的情况:
并发是10的buffer情况: (背压的情况比较严重, 曲线持续性地达到峰值, 会导致资源占光)

10并发的buffer情况
并发是40的buffer情况:(有了比较大的改善, 但是还是存在背压的问题, 因为曲线有达到顶峰的时候)

40并发的buffer情况
4) 从网上了解到flink的并发度的优化策略后, 有了一个比较好的解决方法, 把第三个算子的并行度设置成100, 与第二个算子的并发度一致:
这样做的好处是, flink会自动将条件合适的算子链化, 形成算子链,
满足上下游形成算子链的条件比较苛刻的:
1.上下游的并行度一致
2.下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
3.上下游节点都在同一个 slot group 中(下面会解释 slot group)
4.下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
5.上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
6.两个节点间数据分区方式是 forward(参考理解数据流的分区)
7.用户没有禁用 chain
算子链的好处: 链化成算子链可以减少线程与线程间的切换和数据缓冲的开销,并在降低延迟的同时提高整体吞吐量。
flink还有另外一种优化手段就是槽共享,
flink默认开启slot共享(所有operator都在default共享组)
默认情况下,Flink 允许同一个job里的不同的子任务可以共享同一个slot,即使它们是不同任务的子任务但是可以分配到同一个slot上。 这样的结果是,一个 slot 可以保存整个管道pipeline, 换句话说, flink会安排并行度一样的算子子任务在同一个槽里运行
意思是每一个taskmanager的slot里面都可以运行上述的整个完整的流式任务, 减少了数据在不同机器不同分区之间的传输损耗, (如果算子之间的并发度不同, 会造成数据分区的重新分配(rebalance, shuffle, hash....等等), 就会导致数据需要在不同机器之间传输)
优化后的JobGraph, 如下图,

合并算子链

taskmanager和slot中的task情况
再次观察缓存池对比的情况:
并发是100的buffer情况: (背压的情况已经大大缓解)

100并发的buffer情况

背压正常
checkpoint生成的时间没有出现超时的情况

checkpoint正常
作者:feng504x
链接:https://www.jianshu.com/p/74c031b1ec29
来源:简书



















 京公网安备 11010802041100号
京公网安备 11010802041100号