目前,Elasticsearch 6.5.0是Elastic最为稳定的版本,它是基于Lucene 7.5.0开发的,可以实现通过Elastic Cloud 的Service进行部署。Elasticsearch 6.5.0能够实现跨群集复制功能,将数据从一个节点复制到另外一个节点 。Elasticsearch 的集群内的自动复制性能不断的提高,以此同时,故障转移和数据恢复方面的性能不断改进。
Elasticsearch 6.5.0为目前最稳定版本
跨越数据集群时常见会发生高延迟的情况,低带宽和更频繁的网络分区意味着如果Elasticsearch中的传统方法扩展到类似WAN的连接,则会导致更为糟糕的体验。必须通过使用外部队列将数据分发到这些数据中心或执行定期快照来切换到多数据中心。有多种方法可以将数据分配到数据中心的多个集群中,但每种方法都需要权衡,从操作复杂性到更高的成本,再到显着的恢复延迟。Elasticsearch实现跨集群复制功能?
1)Elasticsearch的索引设计
- 一份索引(index)可分成多个分片(shard)并分配在不同节点上(node) 。
- 一份shard可由一个主分片(primary)和多个备副本(replica)组成。
- 数据先写到主分片,写入成功则同步到各个备副本上。
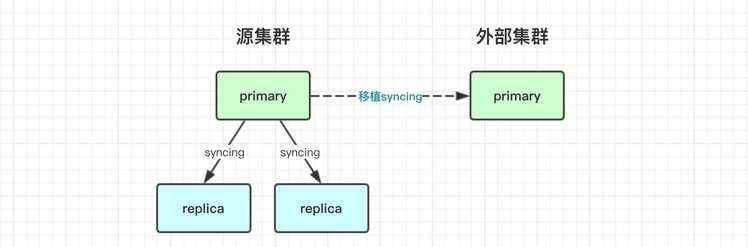
elasticsearch分析primary到replica的内部复制处理流程,将复制目标扩展到外部集群达成跨集群数据同步效果。
2)Elasticsearch跨集群同步设计
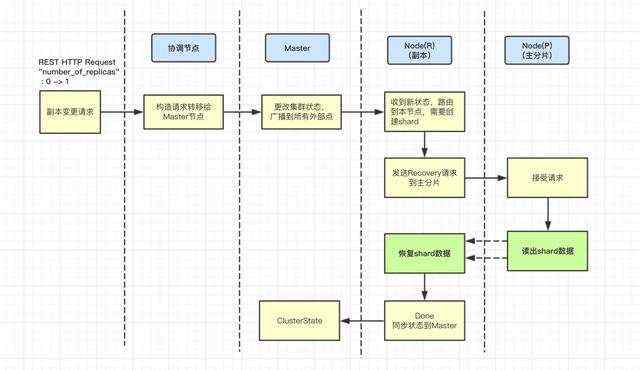
- 类似于k8s|hippo,ES的分布式调度模型也采用一种目标式的资源管理方式,即master发布一个全局状态(ClusterState),工作节点共同协作,直到整体集群状态达到一致。
- RoutingTable(路由表)是状态的一个子模块,他管理了所有索引的路由状态,如新建的索引放在那些节点上,某些节点磁盘快满了应该迁移出去等等。
- ShardRouting 是RoutingTable的具体表现,他表示一个分片的路由规则,如分片是否为主分片、放在哪个节点、现在处于什么状态等等。
当我们为一个索引建立一个新的副本,Master节点便会发布一个新的集群状态,被分配的Work节点根据ShardRouting找到主分片位置并建立恢复任务,此过程在ES中被称之为peer_recovery。
3)Elasticsearch跨集群同步数据实例
curl -XPUT -H'Content-Type: application/json' localhost:9201/_cluster/settings -d '{ "persistent": { "search.remote": { "america": { "skip_unavailable": "true










 京公网安备 11010802041100号
京公网安备 11010802041100号