1,背景
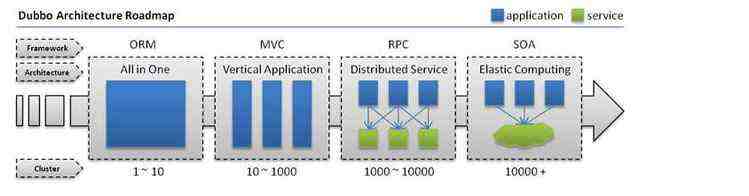
1,网站刚开时候的时候可能所有的功能业务都在一个应用里面
2,当业务不断复杂,流量不断增多的时候,就需要将原先的一个应用划分成多个独立的应用。
3,当分出来的业务越来越多的时候,应用也变的多而复杂,各个应用之间的交互也必不可少,就需要进行远程服务调用RPC,使用哪个找哪个,调用哪个。
4,当服务越来越多的时候,上面那种用一个找一个的方法,不仅管理混乱而且资源浪费,这时就需要一个服务调度中心来管理所有的服务信息,做为一个服务中心,所有使用者都只要关注服务中心即可。并且还需要不同服务 不同集群不同路由不同容错等等资源合理 运用起来才行。
而dubbo正好解决这样的一系列问题。
2,dubbo大体的架构
我的理解
dubbo大体上就是有三个部分,服务提供者,服务消费者,监控中心。服务提供者开发好服务之后,将调用这个服务的地址等信息都注册到一个服务注册中心去(常用zookeeper),通一个服务可以有多个提供者,服务消费者要消费的时候,就从注册中心拿过来自己要消费的服务的多个地址列表(有多个提供者的话),然后按照dobbo自己的软负载均衡算法,来选出一个提供者,去调用。这样,消费者不用去关心谁提供的服务,只需要找服务注册中心即可,而提供者也不需要将配置文件告诉所有消费者,只需要注册到注册中心即可。并且服务的集群负载均衡都是在消费端的,也保证了服务的干净,随时都可以增加减少服务提供者。
官方文字
节点角色说明:
Provider: 暴露服务的服务提供方。
Consumer: 调用远程服务的服务消费方。
Registry: 服务注册与发现的注册中心。
Monitor: 统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。
调用关系说明:
0. 服务容器负责启动,加载,运行服务提供者。
1. 服务提供者在启动时,向注册中心注册自己提供的服务。
2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
dubbo的多样化方式
1,支持协议多样化
不同的服务,不同的场景,不同的消费者,可能适合的服务协议不一样,这里,dubbo已经实现了多种协议的提供和调用
dubbo协议:使用mina,netty,grizzy三种之一来实现。
rmi协议:使用jdk标准的java.rmi.*来实现
hessian协议:采用Servlet暴露服务,Dubbo缺省内嵌Jetty作为服务器实现。
http协议:采用Spring的HttpInvoker实现
webservice协议:基于apache的cxf来实现
thrift协议,memcached协议,redis协议
并且dubbo也支持协议的扩展。
2,注册中心多样化
注册中心也实现了多种方式
Multicast注册中心:不需要启动任何中心节点,只要广播地址一样,就可以互相发现,但是组播受网络结构限制,只适合小规模应用或开发阶段使用。
Zookeeper注册中心:Zookeeper是Apacahe Hadoop的子项目,是一个树型的目录服务,支持变更推送,适合作为Dubbo服务的注册中心,工业强度较高,可用于生产环境,并推荐使用
Redis注册中心
Simple注册中心
3,dubbo也支持各种扩展
1,协议的扩展,可以根据自己的业务需求来扩展对应的协议,不过一般上也够用,
2,负载均衡的扩展,如果觉得dubbo的集中负载均衡不够的话,可以自己扩展。
3,注册中心扩展,一般上用zookeeper也行了。
4,序列化的扩展,dubbo默认使用的是 hessian2(阿里修改了下)序列化方法,可扩展成kryo等更高效的。
等等
由此来说,dubbo的实现已经可以满足服务集中化管理的多种场景了。可以学学。
dubbo的具体使用方法细节参考:http://dubbo.io/Home-zh.htm 写的非常详细。
dubbo学习 一 dubbo概述








 京公网安备 11010802041100号
京公网安备 11010802041100号