作者:拍友2602939213 | 来源:互联网 | 2023-08-20 15:21
本文整理自京东高级技术专家怕孤独的滑板在FlinkForwardAsia2020分享的议题《ApacheFlink在京东的实践与优化》,内容包括:1.业务演进和规模2.容器
本文将整理京东高级技术专家害怕孤独的滑板在Flink Forward Asia 2020上分享的议题《Apache Flink 在京东的实践与优化》。 内容如下。
1 .业务发展和规模
2 .容器化的实践
3 .改进3.Flink的优化
4 .未来计划
一、业务演进和规模 1.业务发展
京东在2014年基于storm搭建了第一代流媒体平台,能够很好地满足业务对数据处理实时性的要求。 但是,在数据量非常大但对延迟并不敏感的业务场景中,存在一些限制。 于是,2017年引入了Spark streaming,利用其微批处理来应对这样的商业场景。
随着业务的发展和业务规模的扩大,迫切需要兼具低延迟和高吞吐量,同时支持窗口计算、状态和最佳时间意义的计算引擎。
于是,2018年,我们引进了Flink,同时基于K8s开始了实时计算容器化的升级改造; 到了2019年,我们所有的实时计算任务都在K8s上运行。 同年,我们基于Flink 1.8构建了新的SQL平台,便利了业务开发的实时计算APP应用; 到了2020年,基于Flink和K8s构建的新的实时计算平台得到了充实。 我们统一了计算引擎,同时支持智能诊断,降低了用户研发和运维APP的成本和难度。 以前,流处理是我们关注的重点。 同年,我们也开始支持批处理,整个实时计算平台开始向批处理流一体化的方向发展。 
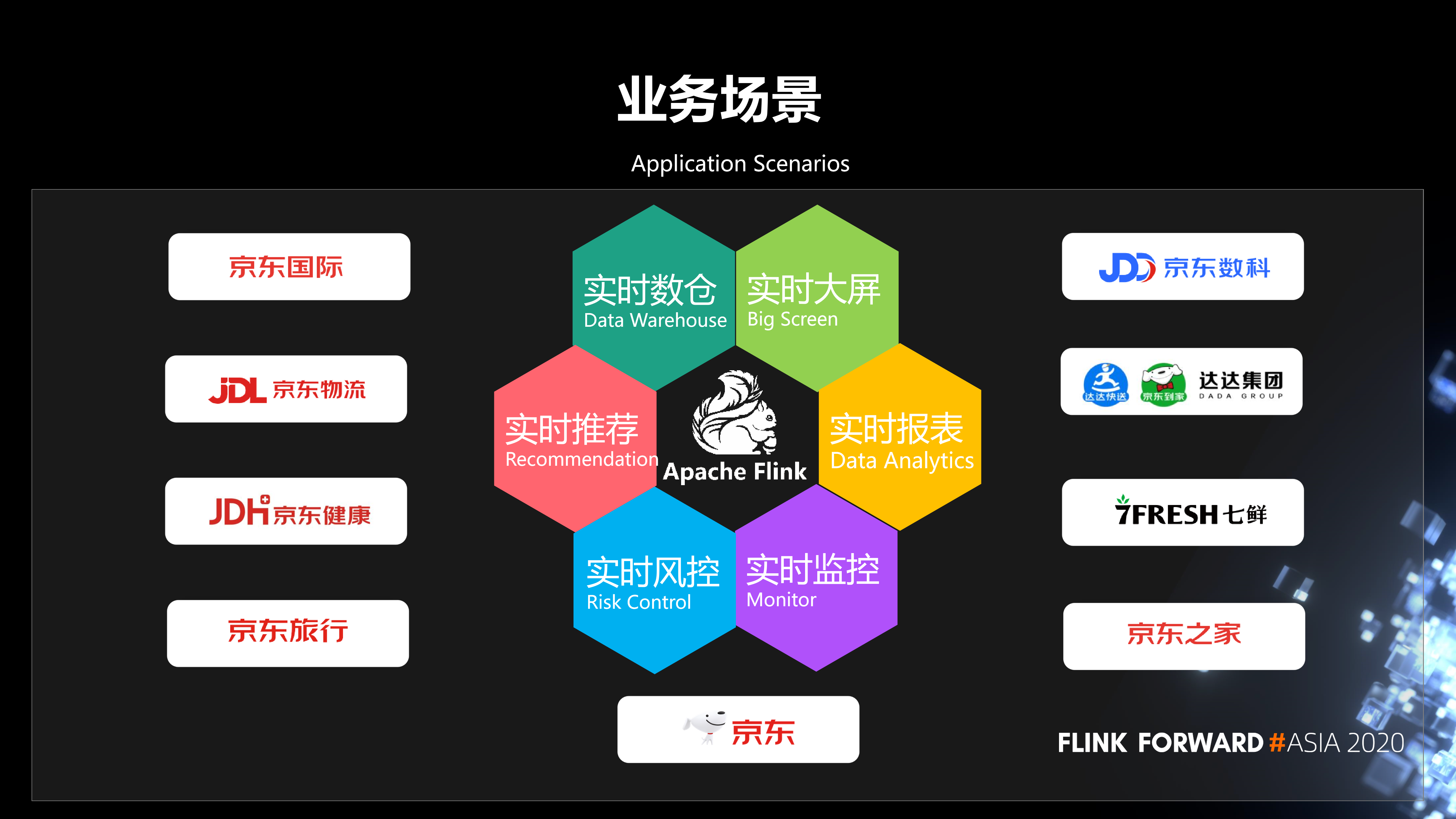
2 .业务场景
京东Flink在京东内部非常多的业务线提供服务,主要应用场景有实时数仓、实时大屏幕、实时推荐、实时报告、实时风控和实时监控,当然还有其他几个应用场景无论如何,实时计算的业务需求一般由Flink开发。
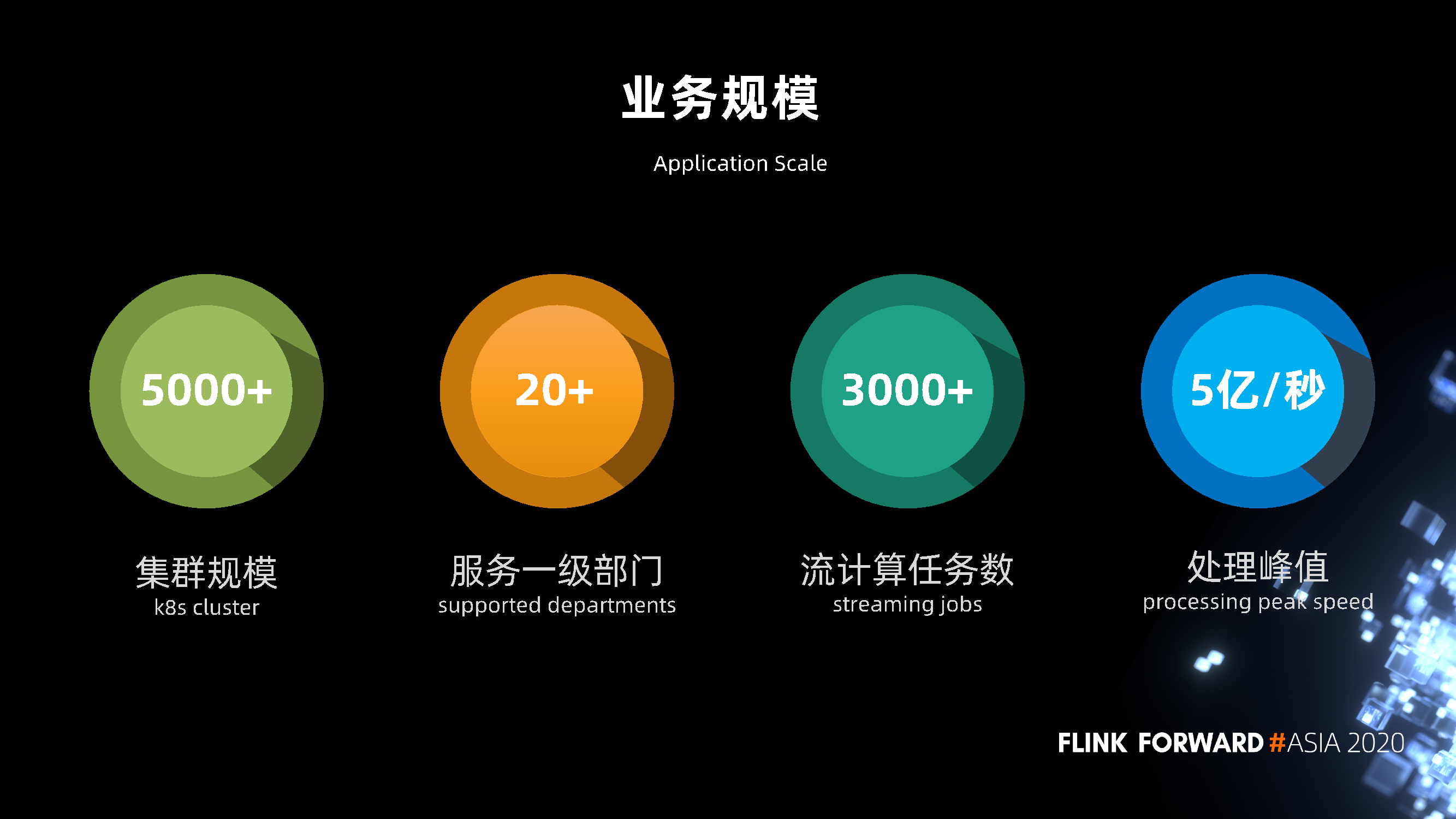
3 .业务规模
目前,我们的K8s集群由5000多台机器组成,服务于京东内部20多个一级部门。 目前,在线流量计算任务数为3000多项,流量计算处理高峰期达到每秒5亿件。
二、容器化实践接下来分享容器化的实践。
2017年,京东内部大部分任务还是storm任务,它们都在物理机上跑,同时也有部分Spark streaming在Yarn上跑。 由于不同的运营环境导致部署和运输成本特别高,在资源利用上存在一定的浪费,因此解决这一问题迫切需要集成的集群资源管理和调度系统。
经过一系列的尝试、比较、优化,我们选择了K8s。 这不仅解决了运维的引入、资源利用的几个问题,还具有云原生灵活性的自我恢复、天然容器的完全隔离、更容易扩展的迁移等优点。 于是,2018年初,开始了容器化的升级改造。
在2018年的6.18中,我们只跑了任务的20%的K8s; 2019年2月,实现实时计算的所有任务都在K8s上运行。 容器化的实时计算平台经历了6.18,双11经历了多次巨大的促进,承担着bhdpw的压力,运行非常稳定。
但是,我们过去的Flink集装箱化方案是基于资源预分配的静态方式,不能满足很多业务场景。 因此,2020年也进行了集装箱化方案的升级。 后面会详细叙述。

容器化可以带来非常多的利益,这里主要强调三点。
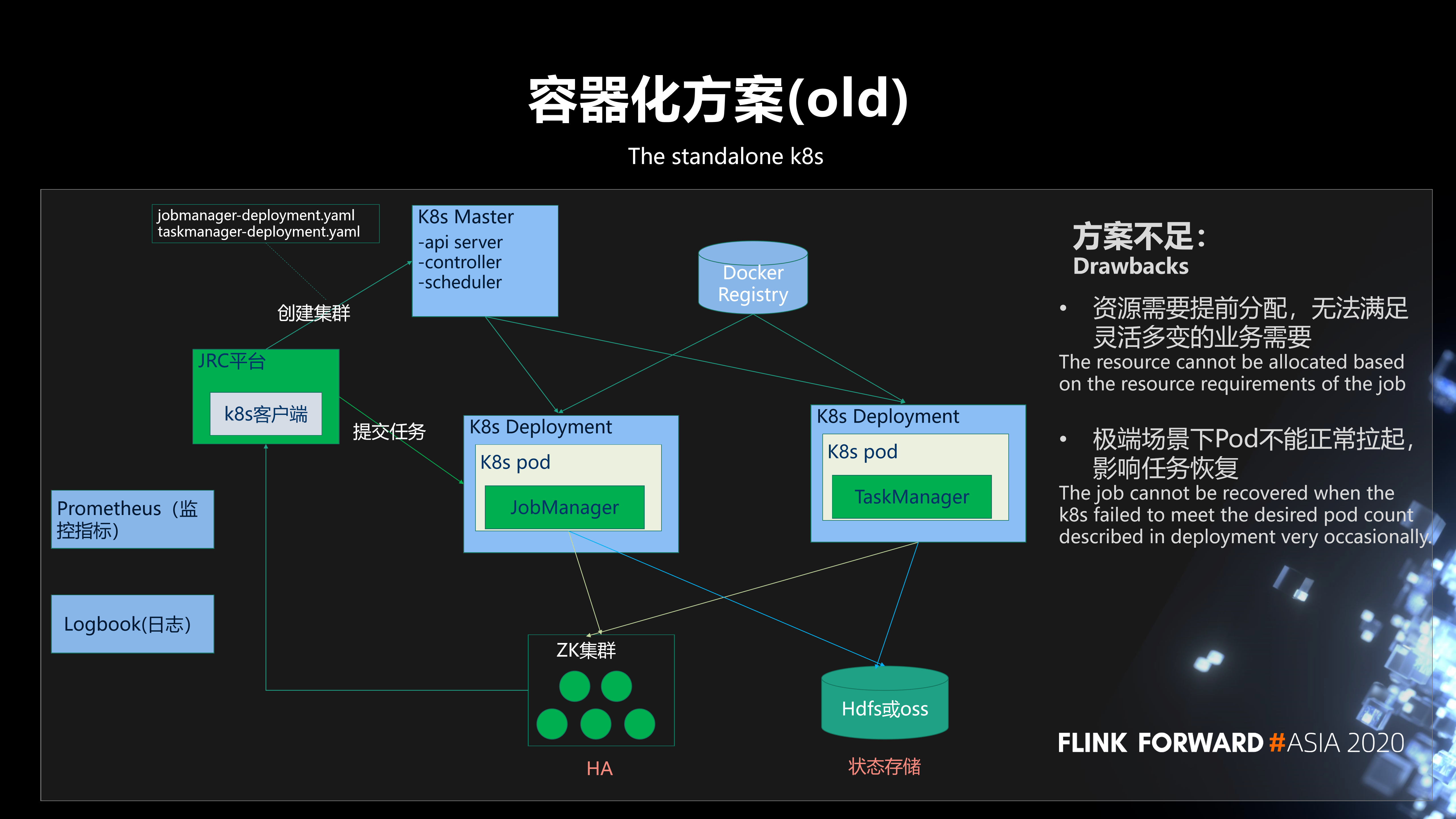
第一,可以方便地实现服务器的混合部署,大幅提高资源共享能力,节约机器资源。 第二,天然的弹性扩张,一定的自我治愈能力,以及它可以实现更完全的资源隔离,更好地保障业务的稳定性。 第三,通过集装箱化实现了开发、测试、生产的一致环境,同时提高了运维的部署和自动化能力,使管理和运维的成本降低了一半。 我们过去的集装箱化方案基于k8s部署引入的标准会话集群。 用户在平台上创建集群时,需要事先
预估出集群所需资源,比如需要的 jobmanager 和 taskmanager 的资源规格和个数,然后平台通过 K8s 客户端向 K8s master 发出请求,来创建 jobmanager 的 deployment 和 taskmanager 的 deployment。
其中,整个集群的高可用是基于 ZK 实现;状态存储主要是存在 HDFS,有小部分存在 OSS;监控指标 (容器指标、JVM 指标、任务指标) 上报到 Prometheus,结合 Grafana 实现指标的直观展示;日志是基于我们京东内部的 Logbook 系统进行采集、存储和查询。
在实践中发现,这个方案有两点不足:
第一,资源需要提前分配,无法满足灵活多变的业务需要,无法做到按需分配。第二,极端场景下 Pod 不能正常拉起, 影响任务恢复 。
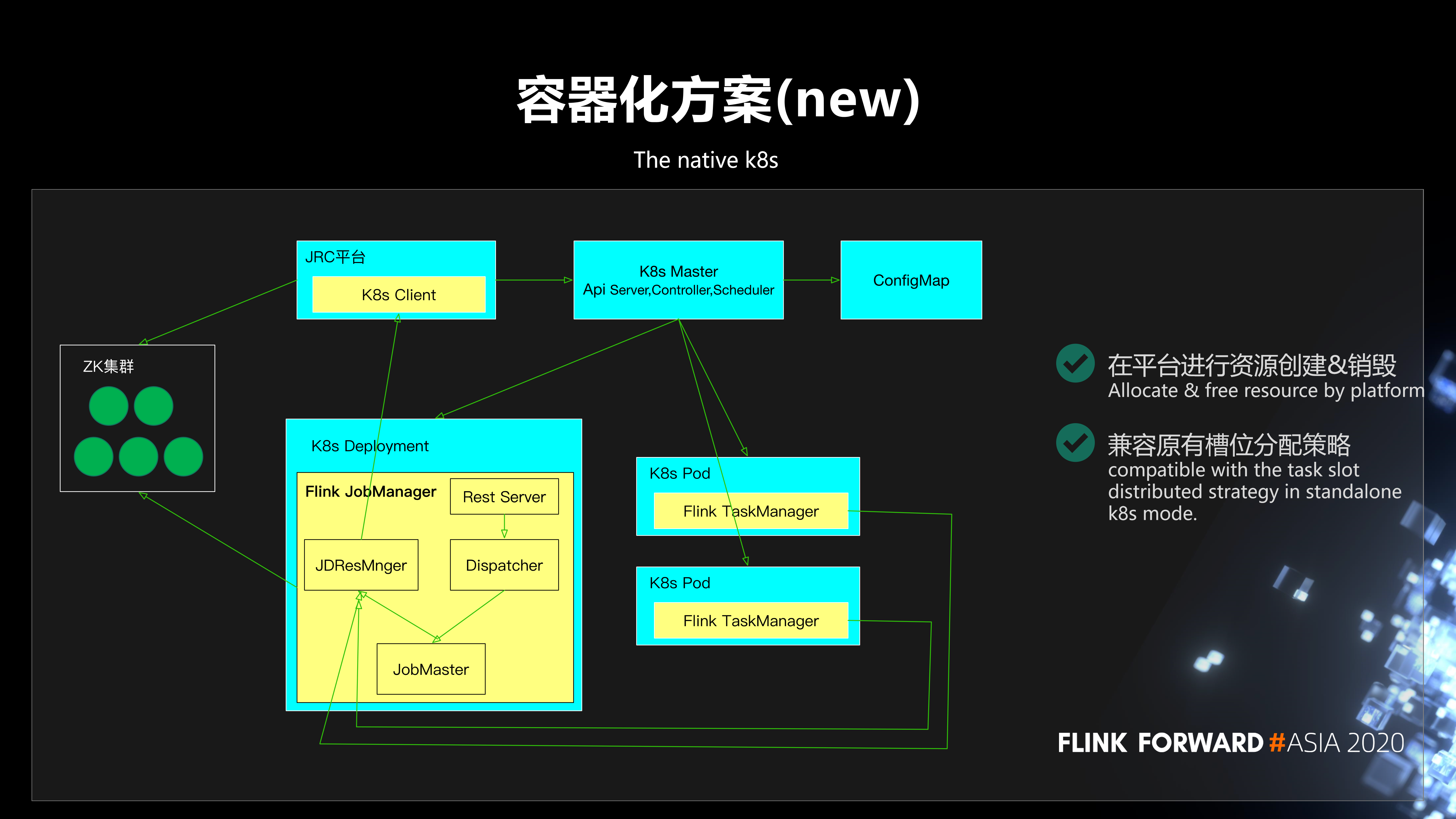
于是我们进行了一个容器化方案的升级,实现了基于 K8s 的动态的资源分配方式。在集群创建的时候,首先我们会根据用户指定的 job manager 的数量创建 jobmanager 的 deployment;用户在提交任务的时候,我们会根据任务所需要的资源数,动态的向平台申请资源,创建 taskmanager。
在运行过程中,如果发现这个任务需要扩容,job manager 会和平台交互,进行动态扩容;而在发现资源浪费时,会进行缩容。通过这样一个方式可以很好的解决静态预分配带来的问题,并提高了资源利用率。
此处,通过平台与 K8s 交互进行资源的创建&销毁,主要基于 4 点考虑:
保证了计算平台对资源的监管。避免了平台集群配置 & 逻辑变化对镜像的影响。屏蔽了不同容器平台的差异。平台原有 K8s 交互相关代码复用。
另外,为了兼容原有 Slot 分配策略 (按 slot 分散),在提交任务时会预估出任务所需资源并一次性申请,同时按照一定的策略进行等待。等到有足够的资源,能满足任务运行的需求时,再进行 slot 的分配。这样很大程度上可以兼容原有的 slot 分散分配策略。
三、Flink 优化改进
下面介绍一下 Flink 的优化改进。
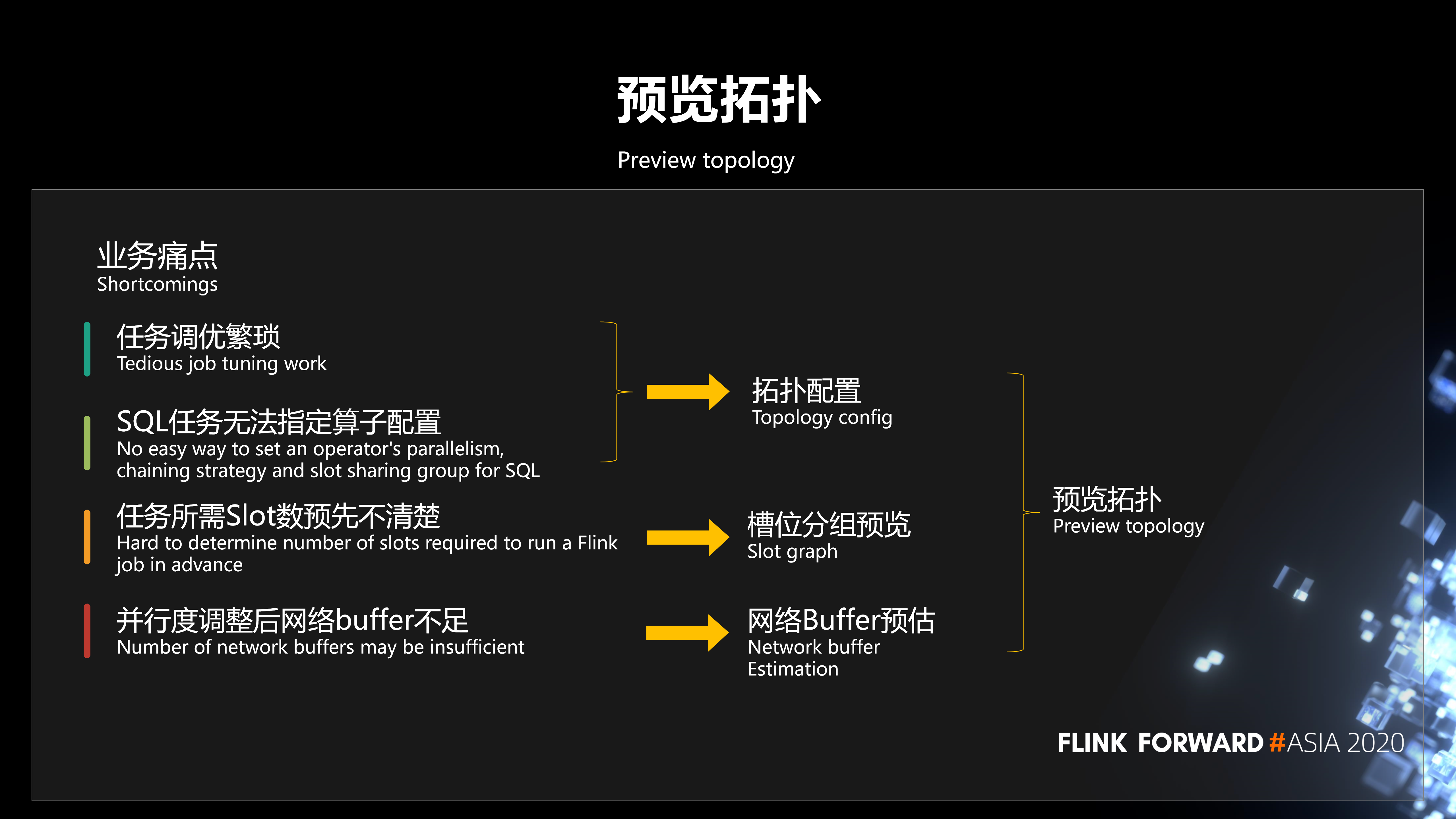
1、预览拓扑
在业务使用平台的过程中,我们发现有几个业务痛点:
第一,任务调优繁琐。在平台提交任务、运行之后如果要调整任务并行度、Slot 分组、Chaining 策略等,需要重新修改程序,或者通过命令行参数配置的方式进行调优,这是非常繁琐的。第二,SQL 任务无法灵活指定算子配置。第三,任务提交到集群之后,到底需要多少资源,任务所需 Slot 数预先不清楚。第四,并行度调整后网络 buffer 不足。
为了解决这些问题,我们开发了预览拓扑的功能:
第一,拓扑配置。用户提交任务到平台之后,我们会把拓扑给预览出来,允许它灵活的配置这些算子的并行度。第二,槽位分组预览。我们会清晰的显示出任务的槽位分组情况和需要多少个槽。第三,网络 Buffer 预估。这样可以最大限度的方便用户在平台进行业务的调整和调优。
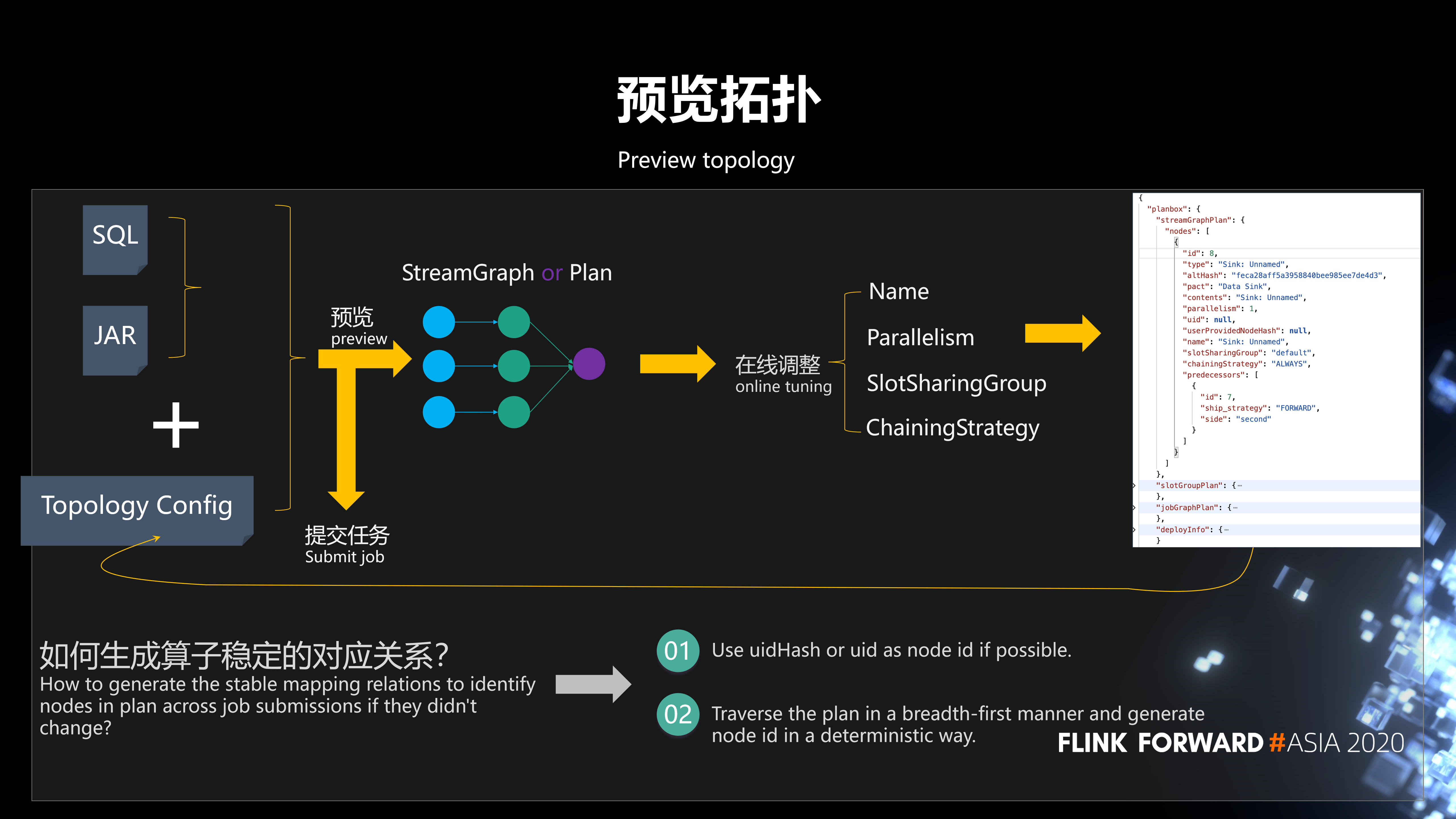
下面简单介绍预览拓扑的工作流程。用户在平台提交 SQL 作业或 Jar 作业,这个作业提交之后,会生成一个算子的配置信息,再反馈到我们平台。我们平台会把整个拓扑图预览出来,然后用户就可以在线进行算子配置信息的调整。调整完之后,把调整完的配置信息重新提交到我们平台。并且,这个过程可以是连续调整的,用户调整完觉得 ok 了就可以提交任务。提交任务之后,整个在线调整的参数就生效了。
这里任务可以多次提交,如何保证前后两次提交生成算子稳定的对应关系呢?我们采用这样一个策略:如果你指定了 uidHash 或者 uid,我们就可以拿 uidHash 和 uid 作为这样一个对应关系的 Key。如果没有,我们会遍历整个拓扑图,按照广度优先的顺序,根据算子在拓扑图中的位置生成确定的唯一的 ID。拿到唯一的 ID 之后,就可以得到一个确定的关系了。
2、背压量化
下面介绍一下我们的第二个改进,背压量化。目前观测背压有两种方式:
第一种方式是通过 Flink UI 的背压面板,可以非常直观的查看当前的背压情况。但是它也有些问题:第一,有的场景下采集不到背压。第二,无法跟踪历史背压情况。第三,背压影响不直观。第四,在大并行度的时候背压采集会有一定的压力。另外一种观测背压的方式是基于 Flink Task Metrics 指标。比如说,它会上报 inPoolUsage、outPoolUsage 这些指标,然后把它采集到 Prometheus 进行一个查询,这种方式可以解决背压历史跟踪的问题。不过它有其他一些问题:第一,不同 Flink 版本的背压指标含义有一定差异。第二,分析背压有一定门槛,你需要对整个背压相关的指标有比较深的认识,联合进行分析。第三,背压的影响不是那么直观,很难衡量它对业务的影响。

针对这个问题,我们的解决方案是采集背压发生的位置、时间和次数指标,然后上报上去。将量化的背压监控指标与运行时拓扑结合起来,就可以很直观的看到背压产生的影响 (影响任务的位置、时长和次数)。

3、文件系统支持多配置
下面介绍下文件系统支持多配置的功能。
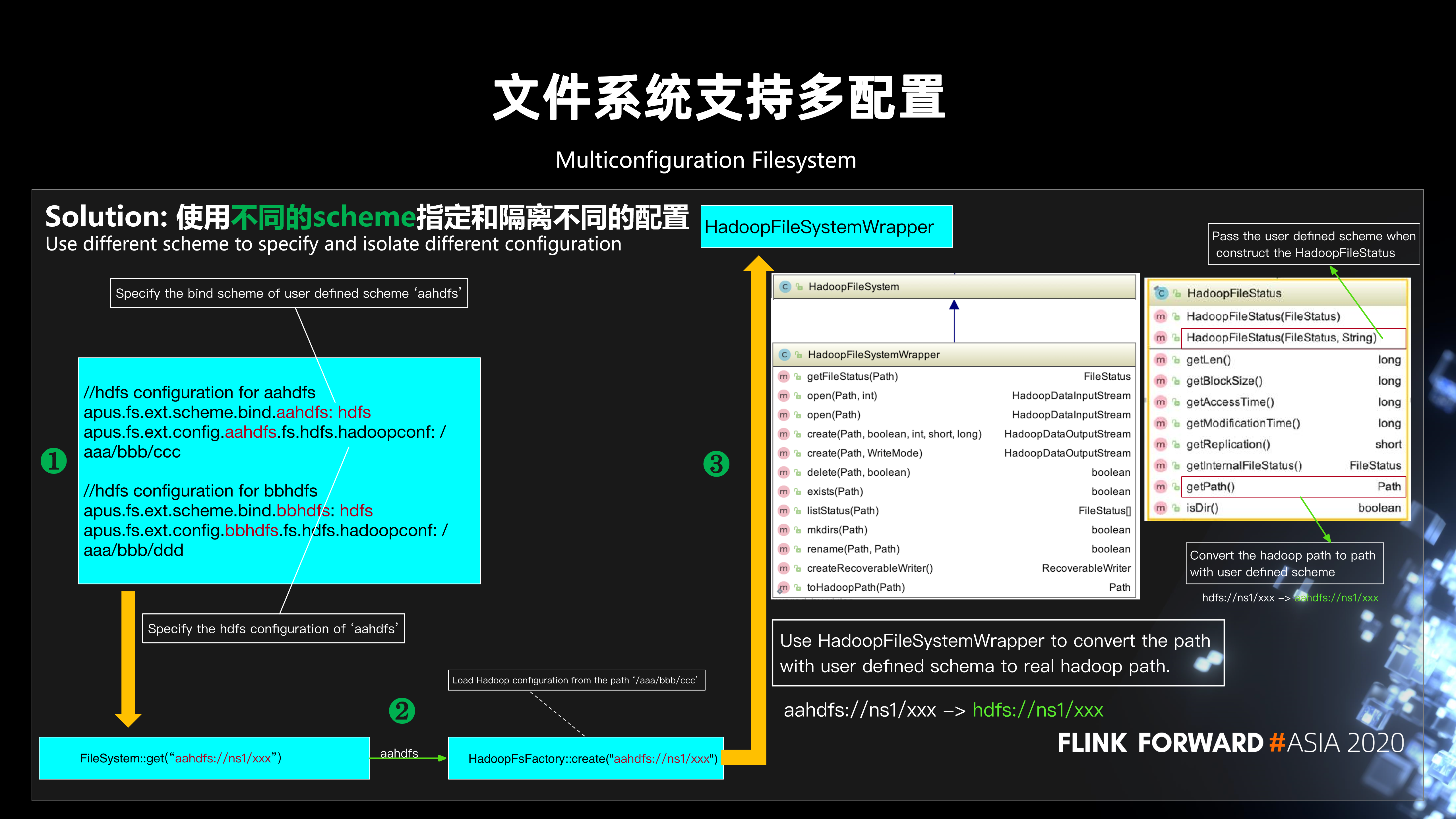
目前在 Flink 中使用文件系统时,会使用 FileSystem.get 传入 URI,FileSystem 会将 shceme+authority 作为 key 去查找缓存的文件系统,如果不存在,根据 scheme 查找到 FileSystemFactory 调用 create 创建文件系统,返回之后就可以对文件进行操作了。不过,在平台实践过程中,经常会遇到这样的问题:
第一, 如何把 checkpoint 写入公共 HDFS,把业务数据写入另外的 HDFS?比如在平台统一管理状态,用户不关注状态的存储,只关注自己业务数据读写 HDFS 这样的场景,会有这样的需求。怎么满足这样的一个业务场景呢?一个方案是可以把多个 HDFS 集群的配置进行融合,但是它会有个问题。就是如果多个 HDFS 集群配置有冲突的话,合并会带来一定的问题。另外,可以考虑一些联邦的机制,比如 ViewFs,但这种机制可能又有点重。是否有其它更好的方案呢?第二, 如何将数据从一个 OSS 存储读出、处理后写到另外一个 OSS 存储?

这两个问题都涉及到如何让 Flink 的同一个文件系统支持多套配置。我们的解决方案是通过使用不同的scheme指定和隔离不同的配置。以 HDFS 支持多配置为例,如下图所示:
第一步,在配置中设置自定义 scheme (aaHDFS) 的绑定的 scheme (HDFS) 及对应 HDFS 配置路径。第二步,在调用 FileSystem.get 时,从 aaHDFS 对应的路径加载 Hadoop 配置。第三步,在读写 HDFS 时,使用 HadoopFileSystemWrapper 将用户自定义 scheme 的路径 (aaHDFS://) 转换为真实的 hadoop 路径 (HDFS://)。
我们也做了许多其它的优化和扩展,主要分为三大块。
第一块是性能的优化,包括 HDFS 优化 (合并小文件、降低 RPC 调用)、基于负载的动态 rebalance、Slot 分配策略扩展 (顺序、随机、按槽分散) 等等。第二块是稳定性的优化,包括 ZK 防抖、JM Failover 优化、最后一次 checkpoint 作为 savepoint 等等。第三块是易用性的优化,包括日志增强 (日志分离、日志级别动态配置)、SQL 扩展 (窗口支持增量计算,支持offset)、智能诊断等等。

四、未来规划
最后是未来规划。归纳为 4 点:
第一,持续完善 SQL 平台。持续增强完善 SQL 平台,推动用户更多地使用 SQL 开发作业。第二,智能诊断和自动调整。全自动智能诊断,自适应调整运行参数,作业自治。第三,批流一体。SQL 层面批流一体,兼具低延迟的流处理和高稳定的批处理能力。第四,AI 探索实践。批流统一和 AI 实时化,人工智能场景探索与实践。
原文链接:http://click.aliyun.com/m/1000293113/
本文为阿里云原创内容,未经允许不得转载。






 京公网安备 11010802041100号
京公网安备 11010802041100号