文章较长,建议收藏,抽完整时间阅读。觉得不错帮转发下!
北京时间 2020 年 6 月 15 日 22 点左右,Go 官方发博文(https://blg.golang.org/pkgsite)宣布,pkg.go.dev 开源了。开源代码托管在 Google 自有仓库 https://go.googlesource.com/pkgsite,不过在 GitHub 上提供了镜像:https://github.com/golang/pkgsite。同时,对于该项目的任何 issue,通过 Go 主仓库进行管理,即 https://github.com/golang/go/labels/go.dev。
Go 作者们可能也没有想到,经过这么多年的发展,Go 被使用最广的竟然是 Web 开发,这可能得益于一开始 Go 就对 http 有很好的支持,也因此涌现出大量的 Web 框架,其中知名的有 Gin、Echo、Beego 等。
运营 Go 语言中文网和 Go 社区 8 年有余,发现广大 Gopher 们都苦于没有实战项目可以练手,很多新手学习完 Go 语法后,因为工作中没有用到,不知道该怎么进行项目实战或用 Go 做点什么。这期间也有很多人问我有无适合新手学习的开源项目。也是在去年初,我因此还创建了《Go项目实战》知识星球。现在,Go 官方开源了 pkg.go.dev 这个 Web 项目,爱学习的你,不应该只是看到了这个消息就完事了,应该做点什么,学点什么。
原计划,我是希望通过这个项目,让大家能够很好的学习 Go 是如何进行实际项目开发的。当我深入研究 pkg.go.dev 源码后,我失望了,无论是设计还是实现,水平都很一般。本想着放弃这一系列,但想想还是继续,一方面尝试指出问题,给出认为正确的做法;另一方面,毕竟是官方的项目,开源了相信它会变得更好。
本文包括的内容(并非大纲):

先上一张官方的架构图:
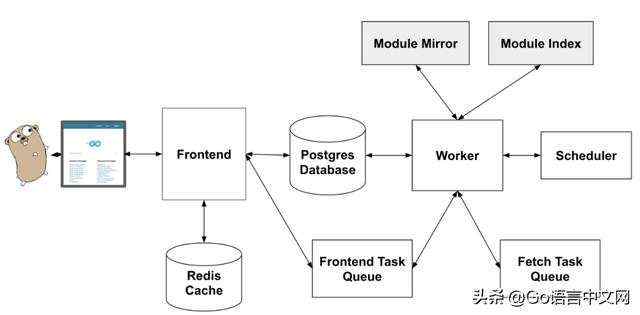
architecture
包含了三个核心组件:
图中其他的部分包括:Frontend 组件使用的 Redis 缓存、任务队列和 Scheduler。
这是一个简单的 HTTP 服务,它从数据库中获取数据,渲染模板,最后生成 HTML 页面。而搜索功能,是通过 Postgres 的全文搜索实现的,因此没有引入另外的搜索组件,比如:Solr、ElasticSearch。
目前前端做的事情比较简单:从 Postgres 数据库中获取 modules 和 packages 等数据,而 Redis 用于缓存这些数据。
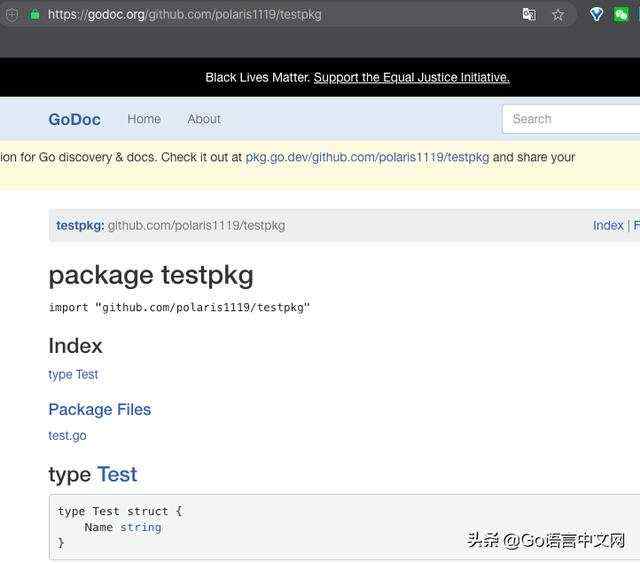
细心的读者会发现这样的设计存在一个问题:更新不及时。前端数据依赖 Worker 组件写入 DB。我临时创建一个 Go 包,用于验证该问题:github.com/polaris1119/testpkg,在 godoc.org 上看到的信息如下:
但 pkg.go.dev 上看到的却是:
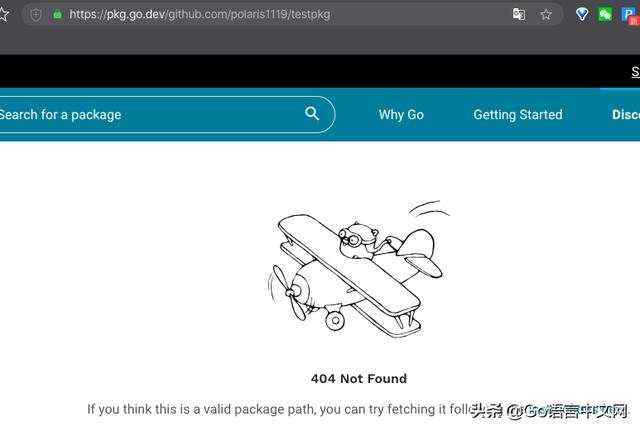
虽然这个 404 页面告诉你:如果你认为这是一个有效的包路径,可以通过这里的说明[3]尝试获取该包。那这个说明是什么?
因为 pkg.go.dev 的数据是从 proxy.golang.org 下载的。我们会定期监控 Go Module Index[4],以查找要添加到 pkg.go.dev 的新包。如果在 pkg.go.dev 上没有看到你要的包,则可以通过以下任一操作将其添加:
向 proxy.golang.org 请求模块版本,可以请求模块代理协议(Module Proxy Protocol)[5]指定的任何端点,例如:https://proxy.golang.org/github.com/polaris1119/testpkg/@v/list;
通过 go 命令下载相应的包。例如:GOPROXY=https://proxy.golang.org GO111MODULE=on go get github.com/polaris1119/testpkg
可见,这个说明是告诉你怎么将包提交给 proxy.golang.org。即使这样做了,很可能 pkg.go.dev 上还是没有,因为 Frontend 只负责从 DB 获取数据。(几分钟后不出意外应该有了)
然而这样的设计大家肯定接受不了,因此出现了几个这样的 issue:#36811[6], #37002[7],#37106[8] 等。为了应对这种情况,所以出现了架构图中的 Frontend Task Queue,用于获取数据库中还不存在的包并将包 master 分支的信息显示给用户,不过截止目前还未实现。不知道到时候以及会如何实现。
这里不得不吐槽了:
Worker 的主要工作是下载发现的新模块,进行处理,然后将信息写入数据库以供 Frontend 使用。它提取 README 文件,许可证文件(license)和文档,并将它们写入数据库。它还将与搜索相关的数据写入表(search_documents)。除了直接在模块 zip 中可用的搜索信息外,它还计算每个包的导入者数量。(imports_unique 表保存了每个包导入的其他包)
为了简化处理新模块的工作并利用上限速和重试功能,Worker 使用 Google Cloud Tasks[9]队列来管理要处理的模块列表。当 Worker 程序在索引(index)中找到新模块时,它会将任务添加到队列中。队列以固定的最大速率将任务推送给 Worker。
文档提到:由于 Worker 必须是无状态 HTTP 服务器,因此无法运行后台任务。因此使用Google Cloud Scheduler[10] 来定期执行任务。这些任务通常每分钟运行一次,它们是:
从架构图可以看到,Worker 从 index 获取新模块(默认是 index.golang.org),从 proxy 获取 module 的 zip 文件(默认是 proxy.golang.org),最后将信息、数据写入 postgres 数据库。
吐槽:
为什么 Worker 必须是无状态的 HTTP 服务,还无法运行后台任务?这里完全可以通过类似 https://github.com/robfig/cron 这样的库来处理定时任务。竟然设计成启动一个 HTTP 服务,由一个外部定时任务调度器(Google Cloud Scheduler)来调用它提供的接口。
数据库方面,主要看看表的设计,同时学习下是如何做迁移管理的。
该项目没有使用配置文件,而是通过环境变量来控制。比如 postgres 数据库相关配置信息通过如下环境变量控制:
这些配置信息在 internal/config/config.go 文件中。
表的设计是项目很重要的一个环节。为了看到该项目的表设计,安装好 postgres 后,执行如下脚本(类 Unix 系统)创建 discovery-db 数据库:
$ devtools/create_local_db.sh
之后执行迁移操作。
很多人可能对迁移不了解,这里简单介绍下。
这里说的数据库迁移,主要是指数据库 schema 的变更(当然也包括不同数据源往某个数据库迁移)。我们知道,代码的变更可以通过 Git 进行管理,通过 Git 可以很容易的实现代码的回滚。于是有人就想,代码变更时,很可能数据表的结构也变了,那有没有可能很方便的对数据库的变化进行回滚呢(升降版本)?于是有了 database migrate。就开源项目而言,对数据库自动升降级很有帮助。
然而数据库迁移并没有标准,依赖于具体的工具实现。迁移工具一般分为两种:1)独立的迁移软件,如 Liquibase[11];2)依附于具体语言的库,比如 Go 语言的 migrate[12],不过这个库也可以作为独立的软件使用。
每一次 schema 的变更,有时包括初始化数据,通常会记录在一个单独的脚本文件中。通常每一次数据库变更,应该生成一个对应的文件。我们通过 migrate 这个库具体学习下迁移的操作。
该项目是 Go 语言实现的数据库迁移工具,支持 CLI 方式使用,也支持作为库导入使用。Migrate 从源读取迁移,并将迁移以正确的顺序应用于数据库。
目前该工具支持如下数据库:
迁移来源支持如下几种:
先安装,以 MacOS 为例:
$ brew install golang-migrate
为了方便演示,以上文创建的 https://github.com/polaris1119/testpkg 为例,clone 下来后,在 testpkg 目录下执行如下命令,创建一个迁移:
$ migrate create -ext sql -dir migrations -seq initial_schema_from_pg_dump
成功后会在 migrations 目录下生成两个文件:
migrations├── 000001_initial_schema_from_pg_dump.down.sql└── 000001_initial_schema_from_pg_dump.up.sql
这里有两个基本概念需要清楚:up 和 down,上面两个文件中有包含。
所以,我们在上面两个文件中填上如下内容:
// up 文件的内容CREATE TABLE gopher ( id serial PRIMARY KEY, username varchar(31) NOT NULL DEFAULT '', email varchar(63) NOT NULL DEFAULT '', created_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP);comment on table gopher is 'gopher用户表';comment on column gopher.username is '用户名';// down 文件的内容DROP TABLE gopher;
之后就可以进行迁移操作了(这里假定你本地已经装上 postgres,密码是 123456,同时创建了 testpkg 数据库):
$ migrate -database "postgres://postgres:123456@localhost:5432/testpkg?sslmode=disable" -source file:migrations up
这时会发现数据库中多了两个表:gopher 和 schema_migrations。其中 schema_migrations 的内容如下:
versiondirty1FALSE
如果这时再执行如下命令进行“回滚”:
$ migrate -database "postgres://postgres:123456@localhost:5432/testpkg?sslmode=disable" -source file:migrations down
为了安全,会如下提示:
Are you sure you want to apply all down migrations? [y/N]
选择 y,成功后再看看数据库的变化,发现 gopher 表不见了,schema_migrations 表的内容也清空了,因为上次是版本 1 ,这次回退了。
为了进一步了解细节,我们再创建一个迁移,增加一个表:
$ migrate create -ext sql -dir migrations -seq add_article_table
会生成两个文件,现在有 4 个文件了:
migrations├── 000001_initial_schema_from_pg_dump.down.sql├── 000001_initial_schema_from_pg_dump.up.sql├── 000002_add_article_table.down.sql└── 000002_add_article_table.up.sql
注意到没?文件名前缀自动变为了 00002。同样,我们在新生成的两个文件中填上如下内容:
// up 文件内容CREATE TABLE article ( id serial PRIMARY KEY, title varchar(127) NOT NULL DEFAULT '', content text NOT NULL, created_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP);// down 文件内容DROP TABLE article;
之后执行迁移命令:
$ migrate -database "postgres://postgres:123456@localhost:5432/testpkg?sslmode=disable" -source file:migrations up
输出:
1/u initial_schema_from_pg_dump (126.243958ms)2/u add_article_table (160.978164ms)
查看数据库,发现 gopher 和 article 表都有了,schema_migrations 表中 version 字段值是 2,符合预期。
明白迁移是怎么回事了吗?现在回过头来看看 pkgsite 的迁移和数据表。
##pkgsite 的数据表
pkgsite 提供了几个脚本,方便使用。比如上文提到的创建数据库的脚本。创建迁移和执行迁移的脚本分别是:devtools/create_migration.sh 和 devtools/migrate_db.sh。我们是研究 pkgsite,自然是执行迁移:(默认 migrate_db.sh 认为 postgres 数据库账号的密码是空,因为我本地设置了密码是 123456,因此需要在 migrate_db.sh 中加上密码)
$ devtools/migrate_db.sh up
输出:
1/u initial_schema_from_pg_dump (220.913916ms)2/u add_modules_identity (259.674211ms)3/u add_paths_table (294.30702ms)4/u redo_golang_search_config (334.652007ms)5/u change_b_weight (357.625559ms)6/u add_identity_keys (381.89522ms)7/u add_readme_package_imports_documentation_tables (420.179973ms)8/u remove_golang_text_config (441.527849ms)9/u add_path_tokens_config (462.907176ms)10/u rename_readme_filename_to_file_path (485.666895ms)11/u add_packages_index (509.399738ms)12/u add_modules_series_path_index (318.179716ms)13/u add_version_map_indexes (304.326151ms)14/u add_paths_module_id_index (293.308189ms)15/u add_package_version_states_module_path_version_index (278.168938ms)16/u add_module_version_states_num_packages (277.566312ms)17/u add_module_version_states_num_packages_index (276.640912ms)18/u add_module_version_states_status_index (260.810518ms)19/u add_imports_unique_index (268.141396ms)20/u add_search_documents_module_path_index (272.004077ms)21/u add_version_map_go_mod_path_column (270.42236ms)
一共 21 个版本。这时在 discovery-db 数据库中生成了一系列表。我们拿其中一个的表:packages ,看看它的设计:
CREATE TABLE packages ( path text, module_path text, version text, commit_time timestamp with time zone NOT NULL, name text NOT NULL, synopsis text, license_types text[], license_paths text[], v1_path text NOT NULL, goos text NOT NULL, goarch text NOT NULL, redistributable boolean NOT NULL DEFAULT false, documentation text, tsv_parent_directories tsvector, created_at timestamp with time zone NOT NULL DEFAULT CURRENT_TIMESTAMP, updated_at timestamp with time zone NOT NULL DEFAULT CURRENT_TIMESTAMP, CONSTRAINT packages_pkey PRIMARY KEY (path, module_path, version), CONSTRAINT packages_module_path_version_fkey FOREIGN KEY (module_path, version) REFERENCES modules(module_path, version) ON DELETE CASCADE);COMMENT ON TABLE packages IS 'TABLE packages contains packages in a specific module version.';COMMENT ON COLUMN packages.commit_time IS 'commit_time is the same as verions.commit_time. It is added here so that we can reduce the number of joins in our queries.';COMMENT ON COLUMN packages.tsv_parent_directories IS 'tsv_parent_directories should always be NOT NULL, but it is populated by a trigger, so it will be initially NULL on insert.';
我又要吐槽了:
总体看,设计者应该没有经历过大项目,或没有参与过因为量大而遇到性能问题的项目。
这里给出当初在 360 时,公司 DBA 对创建数据表的一些建议或要求:
以上虽然是针对 MySQL 的,但基本上 Postgres 也是适用的。
看看 pkgsite 项目的目录结构:
$ tree -L 2.├── CONTRIBUTING.md├── LICENSE├── PATENTS├── README.md├── all.bash├── cloudbuild.yaml├── cmd│ ├── frontend│ ├── prober│ ├── teeproxy│ └── worker├── content // 存放静态资源(css/img/js 等)│ └── static├── devtools│ ├── compile_js.sh│ ├── create_local_db.sh│ ├── create_migration.sh│ ├── drop_test_dbs.sh│ ├── lib.sh│ └── migrate_db.sh├── doc // 存放设计文档│ ├── architecture.png│ ├── design.md│ ├── frontend.md│ ├── postgres.md│ ├── precommit.md│ └── worker.md├── go.mod├── go.sum├── internal│ ├── auth│ ├── complete│ ├── config│ ├── database│ ├── datasource.go│ ├。。。。。 // 省略了很多├── migrations // 迁移的 sql,前文讲过└── third_party // 用到的第三方前端库 ├── autoComplete.js └── dialog-polyfill39 directories, 66 files
其他目录说明见上面对应的注释。
上面说,main.main 放在 cmd 目录下几乎是约定俗成的,但针对这个问题还是需要进一步说明一下,毕竟这不是标准或规范。
那关于 main.main,即包含 main 包 和 main 函数的文件(一般是 main.go)放在哪里,目前一般有两种做法:
1)放在项目根目录下。这样放有一个好处,那就是可以方便的通过 go get 进行安装。比如 github.com/polaris1119/golangclub ,按这样的方式安装:
$ go get github.com/polaris1119/golangclub
成功后在 $GOBIN(未设置时取 $GOPATH[0]/bin )目录下会找到 golangclub 可执行文件。但如果你的项目不止一个可执行文件,也就是会存在多个 main.go,这种方式显然没法满足需求。
目前有一些开源项目是这么做的,比如 cobra 生成的框架也是采用的这种方式。
2)创建一个 cmd 目录,专门放置 main.main,有些项目可能会直接将 main.go 放在 cmd 下,但这又回到了上面的方式,而且还没上面的方式方便。一般建议项目存在多个可执行文件时,在 cmd 下创建对应的目录。因为 pkgsite 存在多个可执行文件,因此采用了这种方式。像知名的 Kubernetes 也是采用的这种方式。对于这种方式,通过 go get 可以这样安装:
$ go get -v golang.org/x/pkgsite/cmd/...
这样会将项目所有的可执行文件都生成,你也可以指定生成某一个:
$ go get -v golang.org/x/pkgsite/cmd/frontend
(未完待续)










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有