前言
数据的价值在当今社会被大众广泛认知,特别是在互联网行业,数据价值的媒介被不断探索、发现、沉淀,最后进行价值输出。在普通大众眼里,可能对大数据的概念并不熟悉,但是其社会行动及日常生活却被大数据仅仅围绕。比如,现在渗透率极高对电商行业,出行等,一些服务方式正是通过大数据手段来实现的。
大数据概念一度被热议,且具有争议。小编比较认同的一个概念是,大数据指的是内存中无法存储下的数据,比较模糊,至少觉得比用数据量来衡量更好,原因是数据量是个相对概念,存疑点较多。
无论是大数据还是其他,数据是基础,这是毋庸置疑的。结构化数据、非结构化数据或半结构化数据,三种数据类型想必大家是经常听说的。那么,于此之前,一个重要的环节则是数据采集,采集来的数据针对不同的类型,存储到不同的数据库中。数据库类型中常用的结构化数据库有MySQL,非结构化数据库有MongoDB、HBase等。
数据采集后,接下来更为重要的是数据处理,此环节关乎数据质量以及后期的数据应用、数据可视化、机器学习、深度学习等。
数据处理涉及的内容叶较为丰富,比如缺失值、异常值、重复数据等。拥有数据处理能力的工具和语言也比较丰富,如SPSS、SAS、R语言、Python语言等。
小编接下来使用python语言,分享重复数据处理方法。大家可能会认为,重复数据耳熟能详,很简单啊。如果以往未进行细致研究的人,若有此类观点,接下来的内容会其则是有助益的。
什么是重复数据?
在日常的数据采集中,经常会发现重复数据,那么什么是重复数据呢?我们通过一个例子来直观感受一下。
我们以python 包pandas 数据结构为例,来看重复数据处理问题。小编在下文生成来一份data数据,具体如下:
In [131]:from pandas import Series,DataFrame
In [132]: data=DataFrame({'k1':['one']*3+['two']*4,'k2':[1,1,2,3,3,4,4]})
In [133]: data
Out[133]: k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
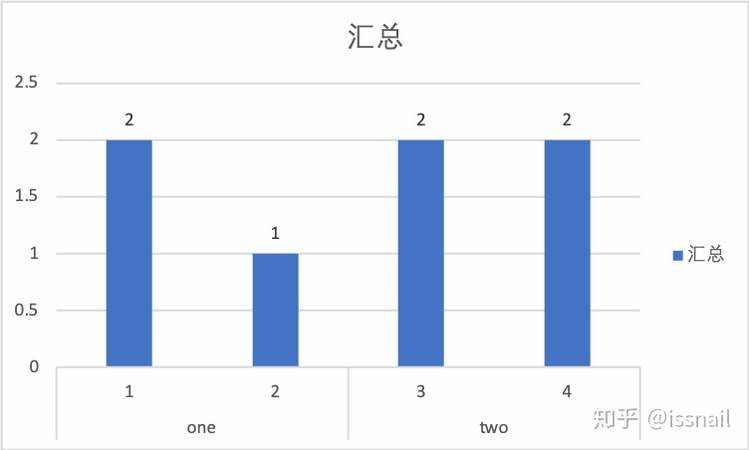
对于上述data数据集进行重复数据统计视图,以柱状图的方式直观查看数据重复情况,具体如下图所示:
从上文数据中,我们可以发现k1=‘one’且k2=1的数据有两条,k1=‘two’且k2=3的数据有两条,k1=‘two’且k2=4的数据有两条,这三类都是data数据集中的重复数据。大家可能认为,有重复数据有什么问题?在一些数据分析场景中,重复数据会影响数据分析结果,以及反应客观现实的准确性。
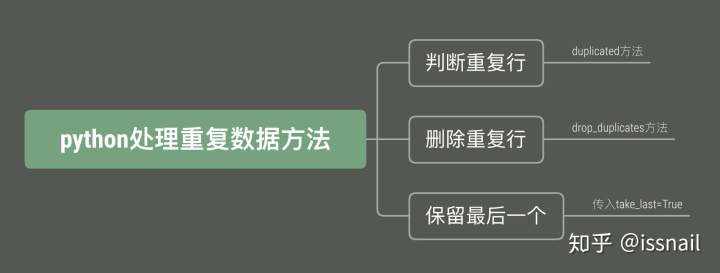
话不多说,接下来,小编带领大家一起来学习如何通过python语言,进行重复数据处理,主要通过三步法来完成,分别为判断重复行、删除重复行、保留最后一个。
重复数据处理三方法
python处理重复数据的三方法,具体如下图所示:
第一:判断重复行
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行:
In [134]: data.duplicated()
Out[134]:
0 False
1 True
2 False
3 False
4 True
5 False
6 True
dtype: bool
第二:删除重复行
还有一个与此相关的drop_duplicates方法,它用于返回一个移除了重复行的DataFrame:
In [135]: data.drop_duplicates()
Out[135]: k1 k2
0 one 1
2 one 2
3 two 3
5 two 4
这两个方法默认会判断全部列,也可以指定部分列进行重复项判断,假设还有一列值,且只希望根据k1列过滤重复项:
In [136]: data['v1']=range(7)
In [137]: data.drop_duplicates(['k1'])
Out[137]: k1 k2 v1
0 one 1 0
3 two 3 3
第三:保留最后一个
Duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入take_last=True则保留最后一个:
In [138]: data.drop_duplicates(['k1','k2'],take_last=True)
Out[138]: k1 k2 v1
1 one 1 1
2 one 2 2
4 two 3 4
6 two 4 6
总结
重复数据问题重要性从未改变,3种方法清楚认识python如何处理重复数据。python处理重复数据方法简单、方便、快捷、灵活性强,大家不妨亲自体验一下,更多分享内容,可关注小编,感谢!










 京公网安备 11010802041100号
京公网安备 11010802041100号