作者:空灵一_一_379 | 来源:互联网 | 2023-05-18 05:01
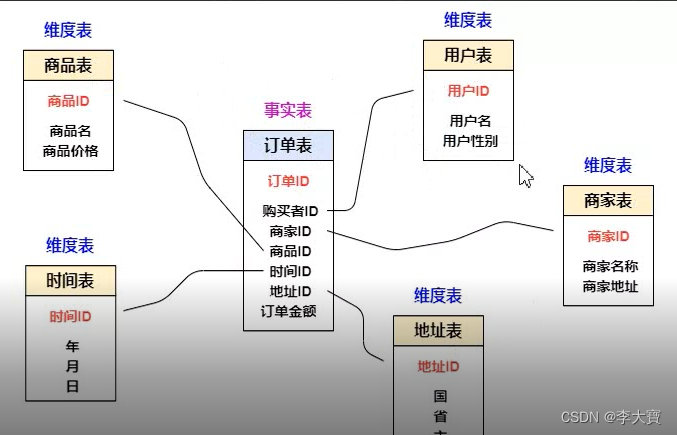
数据仓库作为企业提供决策支持而构建的集成化数据环境,本身并不产生或者消费数据,基本架构包含的是数据流入流出的过程,首先放上一张数据仓库的架构图。数据仓库作为中间集成化数据
数据仓库作为企业提供决策支持而构建的集成化数据环境,本身并不产生或者消费数据,基本架构包含的是数据流入流出的过程,首先放上一张数据仓库的架构图。数据仓库作为中间集成化数据管理的一个平台,底层有多种数据来源,流入数据仓库之后对上层应用开放。

1、分析业务需求,确定数据仓库主题
数据模型的创建依赖数据仓库主题的确定,在搭建数据仓库之前,首先就是要充分了解业务部门的问题需求,明确我们所要创建的数据仓库真正可以解决的问题,在多次沟通的前提下,可以准确的确定系统能够实现的功能。在这个过程中,基于双方理解问题的不同,还需要我们对需求做出一些原型的演示,避免理解上的分歧。
需要做到包括:从业务方需求中提取出重要的业务数据主题,并对业务数据主题进行详细的解释;对提取出的业务数据主题进行主题域的划分,并对主题域进行详细的解释;根据主题域的划分,对内部的组织结构和业务关系细节化,构建出主题域的概念模型。
2、构建逻辑模型
在概念模型的基础上,对其进行进一步的细化和分解,通过实体和实体之间的关系描述业务的需求和系统实现的技术领域。逻辑模型的构建在数据仓库的实施中最为重要,是业务需求人员和技术人员进行沟通的桥梁和平台,能够直接反映业务部门实际的需求和对业务的规划,同时对下面物理模型的构建也具有指导意义。逻辑模型通过实体与实体之间的关系勾勒出了整个业务部门的数据蓝图和规划。
逻辑模型主要关注细节性的业务规则,同时也需要解决每个主题域包含的概念范畴和跨主题域的集成和共享问题,构建的步骤一般包括:分析需求,列出需要分析的主题,明确需求目标、维度指标、分析的指标、分析的方法、数据的来源以及需要关注的对象等;选择用户感兴趣的数据,通过业务需求将需要分析的指标分离抽取出来,转换为实体;在实体中增加时间戳属性;考虑粒度层次的划分,粒度决定了数据仓库的实现方式、性能、灵活性以及数据仓库的数据量;在粒度层次划分的基础上,进行关系模式的定义,关系模式一般采取第三范式的特点进行定义;同时在逻辑模型的基础上对实体的属性、属性的值域等信息进行明确、完善和细化,保证真实的反映业务的逻辑关系和业务的规则。
3、逻辑模型转换为物理模型
基于逻辑模型,接下来就是为应用环境选择一个合适的物理结构,包括合适的存储结构以及合适的存储方法。将逻辑模型转换为物理模型主要包括:实体名转换为表名;属性名转换为列名,并且确定列的属性;在物理模型的创建过程中,必须要对列的属性进行明确,包括列名、数据类型、是否是空值以及长度等。确定物理模型之后,对于数据的存放位置和存储空间的分配等也需要进行规划。
4、数据源接入
在数据仓库的建立之前,需采集底层多种数据源数据,明确数据源中的数据种类,采用合适的工具。比如,Flume NG作为实时日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时,对数据进行简单处理,并写到各种数据接收方;NDC,Netease Data Canal,直译为网易数据运河系统,可以实现结构化数据库的数据实时迁移;Sqoop可以将关系型数据库中的数据导入到平台中;Logstash作为开源的服务端数据处理管道,也可以轻松的将日志、WEB应用等数据采集到平台中。
5、数据存储清洗和转换
对数据进行清洗和转换,保证进入到数据仓库中的数据的一致性。结合业务需求,采用合适的数据清洗转换工具。
6、对接BI,数据展示
为业务部门选择合适的工具实现对数据仓库中的数据进行分析的目的,正确清晰的展现用户的功能需求。
数据仓库搭建成功之后,还需对其安全性、备份恢复等方面进行管理。
原文









 京公网安备 11010802041100号
京公网安备 11010802041100号