2019独角兽企业重金招聘Python工程师标准>>> 
centos7安装Hadoop+hbase+hive步骤
一、IP、DNS、主机名
linux 静态IP、DNS、主机名配置
二、Hadoop
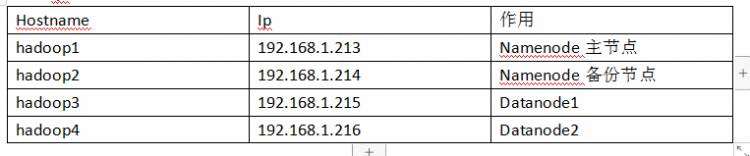
1. IP分配
2. 安装jdk8(四台)
yum list java*
yum install -y java-1.8.0-openjdk-devel.x86_64
默认jre jdk 安装路径是/usr/lib/jvm下面
3. 配置jdk环境变量(四台)
vim /etc/profileexport JAVA_HOME=/usr/lib/jvm/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin
使得配置生效
. /etc/profile
查看变量
echo $JAVA_HOME
输出 /usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64
4. 安装Hadoop
创建文件夹(四台) mkdir /lp mkdir /lp/hadoop
复制hadoop安装包到/tmp(以下开始,操作只在主节点)
解压:
tar -xzvf /tmp/hadoop-3.1.2.tar.gz
mv hadoop-3.1.2/ /lp/hadoop/
etc/hadoop/hadoop-env.sh 添加如下内容
export JAVA_HOME=/usr/lib/jvm/java/
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
修改etc/hadoop/core-site.xml,把配置改成:
修改etc/hadoop/hdfs-site.xml,把配置改成:
etc/hadoop/yarn-site.xml,把配置改成:
etc/hadoop/mapred-site.xml,内容改为如下:
修改etc/hadoop/workers
vim etc/hadoop/workershadoop3
hadoop4
压缩配置好的hadoop文件夹
tar -czvf hadoop.tar.gz /lp/hadoop/hadoop-3.1.2/
拷贝到其余节点:
scp hadoop.tar.gz root@192.168.1.214:/
解压删除:
tar -xzvf hadoop.tar.gz
rm –rf hadoop.tar.gz
5.配置Hadoop环境变量(四台)
vim /etc/profile.d/hadoop-3.1.2.shexport HADOOP_HOME="/lp/hadoop/hadoop-3.1.2"
export PATH="$HADOOP_HOME/bin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoopsource /etc/profile
配置hosts(四台)
vim /etc/hosts192.168.1.213 hadoop1
192.168.1.214 hadoop2
192.168.1.215 hadoop3
192.168.1.216 hadoop4
免密码登录自身(四台)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
master免密码登录worker【单台,只需在namenode1上执行】
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop3
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop4
格式化HDFS [只有首次部署才可使用]【谨慎操作,只在master上操作】
/lp/hadoop/hadoop-3.1.2/bin/hdfs namenode -format myClusterName
开启hadoop服务 【只在master上操作】
/lp/hadoop/hadoop-3.1.2/sbin/start-dfs.sh
/lp/hadoop/hadoop-3.1.2/sbin/start-yarn.sh
web地址
Hdfs页面:
主:192.168.1.213:8305
从:192.168.1.214:8310
Yarn页面:
192.168.1.213:8320
三、Hbase
基于以上的hadoop配置好各个节点。并且使用hbase自带的Zookeeper
分配

解压对应的hbase
tar -xzvf /tmp/hbase-2.1.2-bin.tar.gz
mv hbase-2.1.2/ /lp/hadoop/
修改/hbase-2.1.2/conf/hbase-site.xml
修改/hbase-2.1.2/conf/hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/java/
export HBASE_CLASSPATH=/lp/hadoop/hbase-2.1.2/conf
export HBASE_MANAGES_ZK=true
修改/hbase-2.1.2/conf/regionservers
hadoop1
hadoop3
把/lp/hadoop/hbase-2.1.2/lib/client-facing-thirdparty目录下的htrace-core-3.1.0-incubating.jar 复制到/lp/hadoop/hbase-2.1.2/lib
cp /hbase-2.1.2/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar /hbase-2.1.2/lib
压缩配置好的hbase-2.1.2文件夹
tar -czvf hbase-2.1.2.tar.gz hadoop-3.1.2/
拷贝到hadoop3节点:
scp hbase-2.1.2.tar.gz root@hadoop3:/lp/hadoop
解压删除
tar -xzvf hbase-2.1.2.tar.gz
rm –rf hbase-2.1.2.tar.gz
启动
./bin/start-hbase.sh
进入shell
./bin/hbase shell
web页面访问
192.168.1.213:16010
四、Hive
基于以上配置把hive配置到hadoop1,mysql5.7安装到hadoop3
分配

解压对应的hive
tar -xzvf /tmp/apache-hive-3.1.1-bin.tar.gz
mv apache-hive-3.1.1-bin/ /lp/hadoop/
配置hive 进入apache-hive-3.1.1-bin/conf/目录 复制hive-env.sh.template 为 hive-env.sh
cp hive-env.sh.template hive-env.sh
编辑hive-env.sh
export HADOOP_HOME=/lp/hadoop/hadoop-3.1.2
export HIVE_CONF_DIR=/lp/hadoop/apache-hive-3.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/lp/hadoop/apache-hive-3.1.1-bin/lib
复制hive-default.xml.template 为 hive-site.xml
cp hive-default.xml.template hive-site.xml
修改hive-site.xml
其他服务可以通过thrift接入hive,可以加上是否需要验证的配置,此处设为NONE,暂时不需要验证
复制hive-exec-log4j2.properties.template 为 hive-exec-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
复制hive-log4j2.properties.template为hive-log4j2.properties
cp hive-log4j2.properties.template hive-log4j2.properties
下载mysql驱动放入/home/hadoop/apache-hive-3.1.1-bin/lib包中
在hadoop3安装mysql5.7版本,并且把root设置为任意主机访问或者hadoop1主机访问
use mysql;
select host,user from user;
grant all privileges on *.* to root@'%' identified by "123456";
flush privileges;
select host,user from user;
初始化(第一次启动)
./schematool -initSchema -dbType mysql
启动
./hive
./hive --service hiveserver2
启动hiveserver2使其他服务可以通过thrift接入hive
Mysql数据库中会自动创建hive数据库
测试
beeline工具测试使用jdbc方式连接
./beeline -u jdbc:hive2://localhost:10000
端口号默认是10000
hiveserver2会启动一个WEB,端口号默认为10002,可以通过 http://192.168.1.213:10002/








 京公网安备 11010802041100号
京公网安备 11010802041100号