wxwidgets下载, 官网: http://www.wxwidgets.org/downloads/

1: 需要的依赖安装
yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel gtk3-devel binutils-devel mesa* freeglut*
2: 将下载的 wxwidgets 上传至liunx, 解压命令如下:
2.1: bunzip2 wxWidgets-3.1.2.tar.bz2 //解压
2.2: tar -xvf wxWidgets-3.1.2.tar //解压
2.3: ./configure --with-opengl -enable-unicode -enable-debug
报错:OpenGL libraries not available
yum install mesa-libGLU-devel
出现如下界面则正常继续下一步
2.4: make && make install //安装, 这个命令需要执行很久 , 安装完成出现如下界面就代表成功了。

2.5: 查看是否安装成功: wx-config --version
如下表示成功

3: 下载 erlang 与 rabbitmq, rabbitmq 使用 erlang开发的, 所以 erlang是必须安装的。
3.7.15的rabbitmq 需要 最少 20.3 或者最大 22.0的erlang版本。

erlang 官网下载地址: http://erlang.org/download/?M=A
erlang 安装版本:https://packagecloud.io/rabbitmq/erlang/
erlang 自动安装命令:
wget --content-disposition https://packagecloud.io/rabbitmq/erlang/packages/el/6/erlang-21.3.8.1-1.el6.x86_64.rpm/download.rpm
下载后执行: yum install erlang-21.3.8.1-1.el6.x86_64.rpm
判断是否安装成功: erl -version
出现下图则是安装成功了。

rabbitmq 官网地址:https://www.rabbitmq.com/download.html

将下载的rabbitmq-server 上传至liunx

执行安装命令: yum install rabbitmq-server-3.7.15-1.el7.noarch.rpm
启动服务:systemctl start rabbitmq-server.service
停止服务:systemctl stop rabbitmq-server.service
设置开机启动:systemctl enable rabbitmq-server.service
停止开机启动:systemctl disable rabbitmq-server.service
重新启动服务:systemctl restart rabbitmq-server.service
查看服务当前状态:systemctl status rabbitmq-server.service
查看所有已启动服务:systemctl list-units --type=service
首先加入开机启动: systemctl enable rabbitmq-server.service
启动 rabbitmq:
service rabbitmq-server start
停止:
service rabbitmq-server stop
报错:

解决办法:
尝试下面的操作:
禁用 SELinux ,修改 /etc/selinux/config
SELINUX=disabled
修改后重启系统
重启后查看状态:systemctl status rabbitmq-server.service 正在运行

开放防火墙端口 5672 15672
firewall-cmd --zone=public --add-port=15672/tcp --permanent
firewall-cmd --zone=public --add-port=5672/tcp --permanent
firewall-cmd --reload
创建管理用户:admin 用户名, admin123 用户密码
rabbitmqctl add_user admin admin123 &&
rabbitmqctl set_user_tags admin administrator &&
rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
安装 插件:rabbitmq-plugins enable rabbitmq_management
重启rabbitmq服务
service rabbitmq-server restart
到此,就可以通过http://ip:15672 使用admin ,admin123 进行登陆web页面了

rabbitmq 官方文档 配置地址: https://www.rabbitmq.com/management.html
修改端口命令, 注意:版本为3.7以上:
在 /etc/rabbitmq/ 目录下新建 rabbitmq.conf 文件
vim /etc/rabbitmq/rabbitmq.conf
如果需要修改端口则加入如下命令:
listeners.tcp.default = 5672 #tcp监听端口
management.listener.port = 8004 #web访问端口

退出保存, 防火墙记得开放端口 8004;
重启服务:
systemctl restart rabbitmq-server.service
访问新的端口:

集群搭建参考官网: https://www.rabbitmq.com/clustering.html#cluster-formation
rabbitmq命令文档地址:http://www.blogjava.net/qbna350816/archive/2016/07/30/431394.html
两台mq搭建成功后,现在开始集群搭建,。 分为mq1 与 mq2 两台服务器。 mq1 为主节点。
| IP地址 | 主机名 | 操作系统 | 防火墙和SELinux | 用途 |
|---|---|---|---|---|
| 192.168.x.128 | mq1 | CentOS7.4(64位) | 开放端口 | 磁盘节点 |
| 192.168.x.129 | mq2 | CentOS7.4(64位) | 开放端口 | 内存节点 |
rabbitmq集群介绍:
RabbitMQ模式大概分为以下三种:
(1)单一模式。
(2)普通模式(默认的集群模式)。
(3) 镜像模式(把需要的队列做成镜像队列,存在于多个节点,属于RabbiMQ的HA方案,在对业务可靠性要求较高的场合中比较适用)。
要实现镜像模式,需要先搭建一个普通集群模式,在这个模式的基础上再配置镜像模式以实现高可用。
一个节点可以是磁盘类型或是内存类型。内存类型的节点只会在RAM中存储内部数据库,不包括消息、消息存储索引、队列索引及其他节点状态。在大多数情况下,所有节点均是磁盘类型,内存类型只是个别情况,可用于改进具有高队列,交换或绑定流失的性能群集。内存类型节点并不能提高消息速率。
由于内存类型节点只存储内部数据库,因此启动时必须从其他节点同步。这就要求集群中至少有一个磁盘类型节点。
RabbitMQ集群节点具备容错机制。只要这个节点同集群中其他节点的联系正常,这个节点可以被随意启停。
队列镜像机制允许队列内容在集群不同节点之间同步。非镜像队列的表现,依赖于queue持久化配置。
RabbitMQ集群有几种模式来处理出现网络分区的情况,以保障集群的一致性。不建议跨WAN运行。
Rabbitmq的集群是依附于erlang的集群来工作的,所以必须先构建起erlang的集群景象。Erlang的集群中各节点是经由过程一个magic COOKIE来实现的,这个COOKIE存放在/var/lib/rabbitmq/.erlang.COOKIE中,文件是400的权限。所以必须保证各节点COOKIE一致,不然节点之间就无法通信。
在RabbitMQ集群集群中,必须至少有一个磁盘节点,否则队列元数据无法写入到集群中,当磁盘节点宕掉时,集群将无法写入新的队列元数据信息。 disc 代表磁盘节点, ram代表内存节点。
当节点脱机时,可以使用空白数据目录重置或启动其对等节点。在这种情况下,恢复节点也将无法重新加入其对等体,因为内部数据存储集群标识将不再匹配。如果标识符修改了不能加入节点可以使用 rabbitmqctl reset 重置命令后就可以加入节点中了。
1: 配置host文件:vim /etc/hosts
注意: 修改后需要重启系统, 用 hostname 命令查看是否修改成功。
加入两台服务器的地址, 两台机器都需要配置

ping 命令测试一下是否能ping通
ping mq1
ping mq2
能平通就没问题

2: 复制 COOKIE信息, 将mq1的COOKIE信息复制到mq2, 多台服务器也一样, 将mq1的COOKIE复制到其他服务器。
用scp的方式将mq1节点的.erlang.COOKIE的值复制到其他两个节点中。以root用户登录, 会提示输入root密码
scp /var/lib/rabbitmq/.erlang.COOKIE root@192.168.x.129:/var/lib/rabbitmq/.erlang.COOKIE
输完密码就会出现如下 100%代表成功了。可以查看一下mq2的COOKIE已经和 mq1的COOKIE一致了。

3: 将mq2以内存节点加入 mq1节点中。 在mq2中输入如下命令
rabbitmqctl stop_app //停止服务
rabbitmqctl join_cluster --ram rabbit@mq1 //将mq2 以内存节点的形式加入 mq1磁盘节点。 --ram代表内存节点。
rabbitmqctl join_cluster --disc rabbit@mq1 //将mq2 以磁盘节点的形式加入 mq1磁盘节点。 --disc 代表磁盘节点。
rabbitmqctl start_app //启动服务

注意: 当加入失败时: 出现如下错误:
原因是: 已经加入集群, 但是从集群中退出后, 数据文件日志不一致, 主机认为该节点还在集群中, 该需要加入集群的节点认为不在集群中,导致加入集群失败。

解决方法:
1: 删除 /var/lib/rabbitmq/mnesia
2: 主节点中将该节点移除集群: rabbitmqctl forget_cluster_node rabbit@mq2
3: 将需要加入集群的节点重新加入集群。 需要重复 stop_app, start_app 步骤。

集群重置后加入集群步骤:
查找rabbit进程
1:ps -ef | grep rabbitmq2:kill -9 进程号3: 首先启动主节点, 还原备份的交换机及队列,然后从主机节点复制:rabbitmq.config 到从节点 ,在目录/etc/rabbitmq/从主机节点复制 COOKIE
4: scp /var/lib/rabbitmq/.erlang.COOKIE root@68.174.75.239:/var/lib/rabbitmq/.erlang.COOKIE输入服务器密码 出现100%就完成5:进入目录 /var/lib/rabbitmq 赋权 .erlang.COOKIEchown rabbitmq:rabbitmq .erlang.COOKIEchmod 600 .erlang.COOKIE6:进入 /var/lib/rabbitmq 删除 mnesia 目录停止
7: rabbitmqctl stop_app 加入主节点集群 rabbit@ceng54为主节点名称
8;rabbitmqctl join_cluster --disc rabbit@cent54
可以在主节点界面看到从节点已经加入, 但是没有运行的状态启动
9:rabbitmqctl start_app 10:
端口到虚拟主机映射以下是示例, 根据自己的端口, 虚拟空间配置rabbitmqctl set_global_parameter mqtt_port_to_vhost_mapping \‘{“1883”:”vhost1”,”8883”:”vhost1”}’
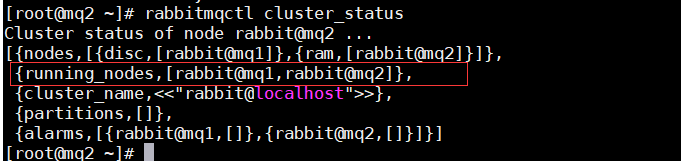
4: 查看节点设置, 在任意一台服务器输入如下命令: 可以看到设置的节点详情
rabbitmqctl cluster_status
disc 磁盘节点 mq1, ram 内存节点 mq2

已加入群集的节点可以随时停止。它们也可能失败或被操作系统终止。在所有情况下,群集的其余部分可以继续运行,并且当节点再次启动时,节点会自动“赶上”(同步)其他群集节点。请注意,某些分区处理策略 可能以不同方式工作并影响其他节点
测试:
停止一台节点: rabbitmqctl stop
running_nodes 运行的节点由两台变成一台。

再次启动停止的节点:rabbitmq-server -detached
发现运行的节点已经是两台了。
节点类型修改; 比如 磁盘节点转为 内存节点, 内存节点转为磁盘节点, 必须先停止服务。
rabbitmqctl stop_app
rabbitmqctl change_cluster_node_type disc 转为磁盘节点
rabbitmqctl change_cluster_node_type ram 转为内存节点
rabbitmqctl start_app
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。虽然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
镜像队列是基于普通的集群模式的,然后再添加一些策略,所以你还是得先配置普通集群,然后才能设置镜像队列,我们就以上面的集群接着做。
镜像模式设置:
1:网页设置,
2:命令设置 ,参考网站:https://www.rabbitmq.com/ha.html
rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}' //意思表示以ha.开头的queue都会复制到各个节点 ["^"匹配所有]
设置的镜像队列可以通过开启的网页的管理端,也可以通过命令,这里说的是其中的网页设置方式。
添加策略:

点击 add polcy 保存; 可以在两台节点mq上都看到配置的 polcy 策略。

创建一个队列:

往队列中添加消息


添加后mq1服务器 队列中就有消息了

节点mq2中同样也有了

节点停机测试:将mq1停机
rabbitmqctl stop_app

在节点mq2的node中就没有 +1的标识了。 消息还存在。 只不过节点只有一台了。

启动mq1节点:
rabbitmqctl start_app
node恢复了两台, 消息也同步了

持久性测试:
RAM节点仅将其元数据保存在内存中。由于RAM节点不必像光盘节点那样写入光盘,因此它们可以表现得更好。但请注意,由于持久性队列数据始终存储在磁盘上,因此性能改进将仅影响资源管理(例如,添加/删除队列,交换或虚拟主机),但不会影响发布或消耗速度。
RAM节点是一个高级用例; 设置第一个群集时,您应该不使用它们。您应该有足够的磁盘节点来处理冗余要求,然后在必要时添加额外的RAM节点以进行扩展。
仅包含RAM节点的集群是脆弱的; 如果群集停止,您将无法再次启动它 并将丢失所有数据。在许多情况下,RabbitMQ将阻止创建仅限RAM节点的集群,但它不能完全阻止它。
此处的示例仅显示具有一个磁盘和一个RAM节点的集群; 这样的集群是一个糟糕的设计选择
将两台节点mq1 和mq2 停止后在启动

当消息选 了持久化后 停止然后启动后 也会恢复消息。 至此, 集群搭建完成。

集群搭建参考:
https://www.rabbitmq.com/clustering.html
https://blog.51cto.com/11134648/2155934
安装 haproxy ,
nginx 适用于 web代理
haproxy 与 LVS
1)两者都是软件负载均衡产品,但是LVS是基于Linux操作系统实现的一种软负载均衡,而HAProxy是基于第三应用实现的软负载均衡。
2)LVS是基于四层的IP负载均衡技术,而HAProxy是基于四层和七层技术、可提供TCP和HTTP应用的负载均衡综合解决方案。
3)LVS工作在ISO模型的第四层,因此其状态监测功能单一,而HAProxy在状态监测 方面功能强大,可支持端口、URL、脚本等多种状态检测方式。
4)HAProxy虽然功能强大,但是整体处理性能低于四层模式的LVS负载均衡,而LVS拥有接近硬件设备的网络吞吐和连接负载能力。
综上所述,HAProxy和LVS各有优缺点,没有好坏之分,要选择哪个作为负载均衡器,要以实际的应用环境来决定。
1:wget http://download.openpkg.org/components/cache/haproxy/haproxy-1.9.5.tar.gz
2:下载地址:http://download.openpkg.org/components/cache/haproxy/

下载后
解压:
tar -zxvf haproxy-1.9.5.tar.gz
进入解压目录
cd haproxy-1.9.5
查询内核版本:
uname -r
注:此处TARGET=linux26是填写系统内核版本 ,内核版本怎么看. uname -r 。如我的版本是3.10.0-862.el7.x86_64, 直接填写310即可。

根据内核版本安装
make TARGET=linux310 PREFIX=/usr/local/haproxy
安装到指定目录 /usr/local/haproxy
make install
haproxy默认不创建配置文件目录,这里是创建haproxy配置文件目录
mkdir /usr/local/haproxy/conf
复制配置, 在解压目录执行

cp examples/option-http_proxy.cfg /usr/local/haproxy/conf/haproxy.cfg
配置文件的配置:
#
# demo config for Proxy mode
#globalmaxconn 20000 #最大连接数#ulimit-n 16384 #打开的最大文件描述符(不建议设置项)log 127.0.0.1 local0 #定义全局的syslog服务器,接收haproxy启动和停止的日志。最多可以定义两个uid 200 #以指定的UID或用户名身份运行haproxy进程gid 200 #以指定的GID或组名运行haproxy,建议使用专用于运行haproxy的GID,以免因权限问题带来风险chroot /var/empty #修改haproxy工作目录至指定目录,可提升haproxy安全级别,但要确保必须为空且任何用户均不能有写权限nbproc 1 #指定启动的haproxy进程个数,只能用于守护进程模式的haproxy;默认只启动一个进程,一般只在单进程仅能打开少数文件描述符的场景>中才使用多进程模式;(官方强烈建议不要设置该选项)daemon #让haproxy以守护进程的方式工作于后台spread-checks 2 #健康检查下 官方建议2-5之间defaultsmode http #工作模式option dontlognulllog global #记录日志option http-server-close #启用服务器端关闭#option forwardfor except 127.0.0.0/8 #传递客户端ipoption redispatch #当服务器组中的某台设备故障后,自动将请求重定向到组内其他主机。retries 3 #请求重试的次数timeout http-request 10s #http请求超时时间timeout queue 1m #一个请求在队列里的超时时间·timeout connect 10s #连接服务器超时时间timeout client 1m #设置客户端侧最大非活动时间timeout server 1m #设置服务器侧最大非活动时间timeout http-keep-alive 10s #设置http-keep-alive的超时时间timeout check 10s #当一个连接建立之后,maxconn 3000 #同时处理的最大连接数#errorfile 403 /etc/haproxy/errorfiles/403.http#errorfile 500 /etc/haproxy/errorfiles/500.http#errorfile 502 /etc/haproxy/errorfiles/502.http#errorfile 503 /etc/haproxy/errorfiles/503.http#errorfile 504 /etc/haproxy/errorfiles/504.http### haproxy 监控页面地址是:http://IP:9188/hastatus
listen admin_statsbind *:9188 #监听的地址和端口,默认端口1080mode http #模式option tcplogstats refresh 5s #页面自动刷新间隔,每隔5s刷新stats uri /hastatus #访问路径,在域名后面添加/stats可以查看haproxy监控状态,默认为/haproxy?statsstats realm welcome login\ Haproxy #提示信息,空格之前加\stats auth admin:123456 #登陆用户名和密码stats hide-version #隐藏软件版本号stats admin if TRUE #当通过认证才可管理### rabbitmq 集群配置,转发到
listen rabbitmq_clusterbind *:5672option tcplogmode tcpbalance roundrobinserver rabbitnode1 IP:5672 check inter 2000 rise 2 fall 3 weight 1 #节点一server rabbitnode2 IP:5672 check inter 2000 rise 2 fall 3 weight 1 #节点二
如果 全局变量配置 global 中配置了 log, 那么还需要执行以下命令:加入日志路径
cat <
eof
重启日志&#xff1a;
systemctl restart rsyslog
检查配置文件是否正确&#xff1a;
haproxy -c -f /usr/local/haproxy/conf/haproxy.cfg
如果出现如下则是参数没有设置&#xff1a;client, connect, server 的timeouts 么有设置。

出现如下则没有问题了。

加入卡机启动&#xff1a;
cat <
haproxy -f /usr/local/haproxy/conf/haproxy.cfg
eof
将rc.local 赋予执行权限&#xff0c;不然死活都不能开机启动
sudo chmod &#43;x rc.local
启动&#xff1a;
haproxy -f haproxy.cfg
重新启动&#xff1a;
service haproxy restart
启动后输入配置的hastatus就能看到如下的监控页面&#xff1a; http://IP:9188/hastatus
注意开启防火墙端口。

1、HAProxy支持的负载均衡算法
&#xff08;1&#xff09;、roundrobin&#xff0c;表示简单的轮询&#xff0c;负载均衡基础算法
&#xff08;2&#xff09;、static-rr&#xff0c;表示根据权重
&#xff08;3&#xff09;、leastconn&#xff0c;表示最少连接者先处理
&#xff08;4&#xff09;、source&#xff0c;表示根据请求源IP
&#xff08;5&#xff09;、uri&#xff0c;表示根据请求的URI&#xff1b;
&#xff08;6&#xff09;、url_param&#xff0c;表示根据请求的URl参数来进行调度
&#xff08;7&#xff09;、hdr(name)&#xff0c;表示根据HTTP请求头来锁定每一次HTTP请求&#xff1b;
&#xff08;8&#xff09;、rdp-COOKIE(name)&#xff0c;表示根据据COOKIE(name)来锁定并哈希每一次TCP请求。
2、常用的负载均衡算法
&#xff08;1&#xff09;轮询算法&#xff1a;roundrobin
&#xff08;2&#xff09;根据请求源IP算法&#xff1a;source
&#xff08;3&#xff09;最少连接者先处理算法&#xff1a;lestconn
测试 haproxy 是否成功代理, 使用springboot测试&#xff0c;
1&#xff1a;新建一个maven项目
2&#xff1a; pom引入依赖
3&#xff1a;增加application.yml配置
host为你部署haproxy的服务器的IP;
注意&#xff1a; 防火墙一定要开启5672端口。

spring:rabbitmq:host: IPport: 5672username: 你的用户名password: 你的密码virtual-host: /
4&#xff1a;代码测试&#xff1a;
&#64;SpringBootTest(classes&#61;Main.class)
&#64;RunWith(SpringJUnit4ClassRunner.class)
public class Tests {&#64;Autowiredprivate SendMsg sendMsg;&#64;Autowiredprivate ReceiveMsg receiveMsg;&#64;Autowiredprivate AmqpTemplate amqpTemplate;private String queue &#61; "test";&#64;Testpublic void sendmsg() {for (int i &#61; 0; i <100; i&#43;&#43;) {amqpTemplate.convertAndSend(queue, "消息测试"&#43;i);}}
如果运行成功&#xff0c; 队列中有发送的消息&#xff0c;那么就代理成功&#xff0c;
如果没有成功&#xff0c;则检查防火墙端口是否开放&#xff0c; 端口是否配置错误&#xff0c;ip是否配置错误&#xff0c; 用户名密码权限是否配置错误

剩下keepalive 高可用就没弄了。 有时间在加上
参考文档 http://cbonte.github.io/haproxy-dcon
商业化网站&#xff1a;https://www.haproxy.com
https://www.cnblogs.com/f-ck-need-u/p/8502593.html





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有