概览
事件流的分析
druid 提供了快速的分析查询一个高并发,在实时节点和历史节点上;强大的用户交互界面;
重构思想
新型数据库,主要思想来自 OLAP/analytic databases,timerseries database,search systems在这个实时架构中;
构建下一代数据栈
原生集成了kafka AWS KinesiS 数据湖 HDFS AWS S3;工作时,有良好的层次的数据流查询架构。
解锁新的工作流程
构建了一个快速的特别分析在实时数据和历史数据两个方面;解释趋势,探索数据,快速查询回答问题。
任何地方部署
在任何×NIX环境中部署,商业硬件和云上部署都支持;原生云支持:扩容和减少非常简单。
定义
druid是一个为高性能、在大量数据集上分片和分块分析 而设计的数据存储
公共应用场景领域
- 点击流分析
- 网络流量分析
- 服务器指标存储
- 应用性能指标
- 数字营销分析
- 商业智能/OLAP
应用场景
- 大比例的插入操作,少量的更新操作
- 大部分查询应用聚合和报告查询使用group by、查询或者扫描操作
- 数据有一个时间列
- load data from kafka HDFS Amazon S3
关键特征
列存储格式
druid使用面向列的存储,对一个特定的查询只需要加载需要的列,面对少量列的查询有了一个速度的大幅提升,每一个列的存储针对特定的数据类型做了存储优化,支持快速扫描和聚合。
可扩展的分布式系统
druid是一个典型的十到数百台的集群服务部署,每秒百万级的数据摄取,保留数万条记录,亚秒级到几秒钟的查询延迟。
大规模并行处理
druid一个查询并行处理在整个集中。
自健康检查 自平衡 简单操作
扩大集群,增加、减少服务,这样的操作集群会自动平衡,无需停机,如果一个服务失败,路由会自动绕个这个服务,直到找到可以替换的服务。druid设计成一个无需任何原因7×24小时不停机的运行的架构,包括配置修改,软件升级.
原生云的 默认容错不会丢失数据的架构
一旦druid摄取了数据,一个copy会被安全的存储到deep storage,例如HDFS、云存储、一个共享的文件系统中;及时每一个服务挂了,数据可以从deep storage恢复;对于一些失败,影响了一些服务,备份确保一些查询是可用的,直到系统被恢复。
用于快速过滤的索引服务
Druid使用CONCISE或 Roaring压缩位图索引来创建索引,这些索引可以跨多个列进行快速过滤和搜索。
近似算法
druid包含一些算法;近似count-distinct、近似排序、位图直方图的近似计算,算法在有限内存中基本上是快于准确计算;这些场景是为了快速计算;druid也提供了准确的count-distinct和排序
摄取时自汇总
druid可选的支持摄取时数据汇总,汇总可以预先聚合你的数据,可以大量开销的节和性能提升。
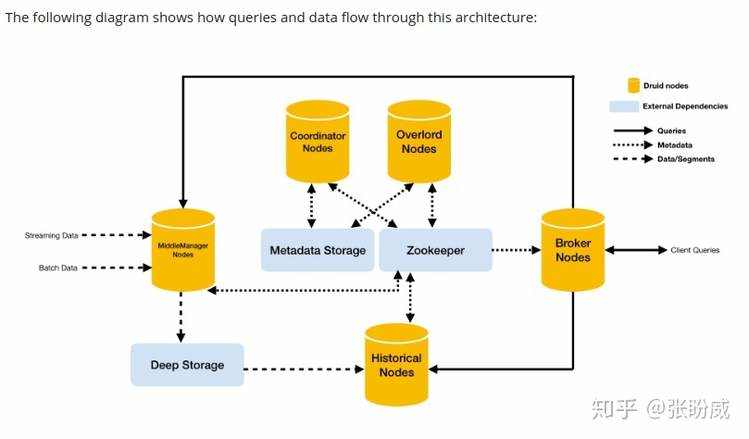
架构
Historical
Historical是一个处理存储和历史数据查询查询到工作站,Historical处理从deep storage加载过来的segments,对这些segments从broker发出的历史数据的查询做出回应;他不接受写;
MiddleManager
MiddleManager摄取新数据到集群中;它负责度额外的数据源(新的实时的数据)和发布新的druid segments
MiddleManager是一个执行提交任务的工作节点;提交任务到peon上在一个独立的JVMs,因为任务的资源和日志的隔离,每一个Peon使用了隔离的JVMS,每一个Peon同时每次只能运行一个task,一个MiddleManager有多个peon;
Broker
处理来自客户端的查询,解析将查询重定向到Historical和MiddleManager,Broker接收到数据从这个子查询中,合并这些结果然后返回给查询者;
Coordinator
Corrdinator监控Historical处理,负责分配segments到指定的服务,确保存在HIstorical中是自平衡的;
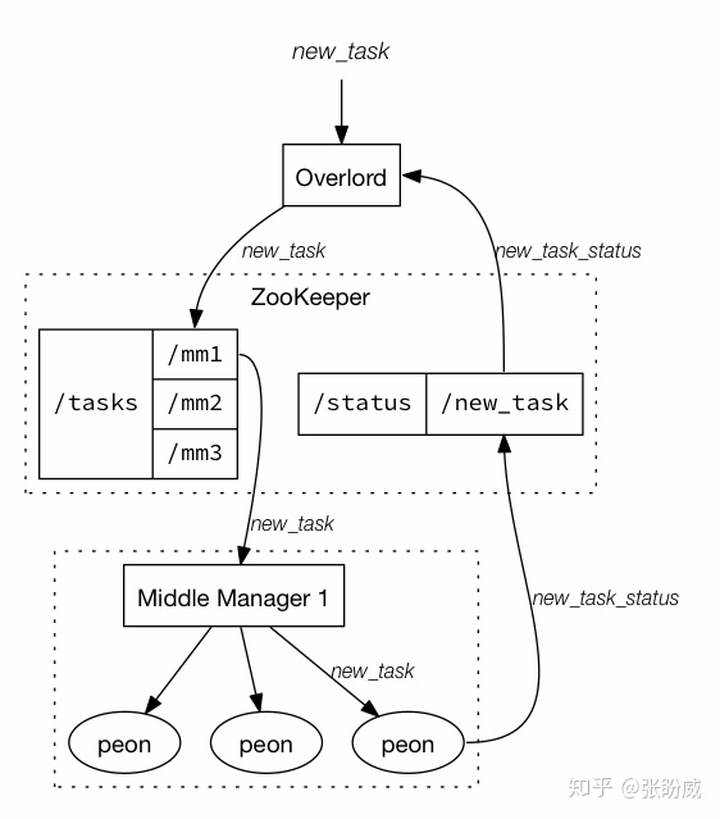
Overlord
监控MiddleManager处理和控制数据加载进druid集群;对分配给MiddleManager的摄取任务和协调segments的发布负责;
local or remote模式 默认local
创建任务锁
Router
可选服务;提供了Brokers,Overlords,Coordinator的统一路由网关;
Peon(苦力)
Peons运行一个单独的任务在一个单独的JVM,MiddleManager负责创建执行任务的peon;peons自己运行是非常稀少的。
总结
- Historical是历史数据摄取和查询到节点,Coordinator监控协调Historical节点上的任务,确保segments自平衡;
- MiddleManager是一个新数据摄取和查询的节点;overlord监控和协调task任务的分配和segments的发布。
- 三种托管计划: "Data" servers run Historical and MiddleManager processes.
"Query" servers run Broker and (optionally) Router processes.
"Master" servers run Coordinator and Overlord processes. They may run ZooKeeper as well.
额外依赖
- Deep storage:一个被druid可访问的共享的文件存储;比如分布式文件系统HDFS、S3、一个网络挂在的文件系统;用它来存储已经陪摄入的任何数据;
- Metadata store:一个共享的元数据存储,典型的关系型数据库PostgreSql和Mysql;
- Zookeeper:一个被用来了额外服务发现、协调、领导选举的; 这个额外依赖设计的idea是为了druid集群在生产环境容易扩张;比如:独立的deep storage 和 metadata store 使集群处理是根本上的容错的;即使一个druid server失败;你可以重启集群从存储在deep storage 和 Metadata store;
Datasources 和 segments
druid data 被存储在打他source中,datasource按照时间进行分区;也可以用其他属性进行分区,每一个时间范围,叫做chunk;一个chunk被分区到一个或多个segments,一个segments是一个单一的文件;里面存储典型的被压缩的原生数据;segments被组织成chunks;就像生活在这个时间线上;datasource > chunk > segment;
一个datasource可能有几个或几千个甚至百万个segments;每一个segment在MiddleManager被创建,在这个时候segment是易变的没有提交的;生成紧凑的支持快速查询segment的步骤: 1. 转换为列模式 2. 建立位图索引 3. 各种算法压缩数据:
最小存储的字符串列的字典编码
位图索引的位图压缩
所有列的类型感知压缩
定期提交和发布segments;在这一时刻,他们被写入深度存储,变成不可变的,从MiddleManager移除到HIstorical流程;一个关于这个segment的条目被写入到Metadata store;这个条目关于segment是自描述的,包含segment的列信息,大小,deep storage的位置;这些条目是告诉Coordinator集群中有哪些数据是可以访问的。
查询处理
查询首先到达Broker,broker确定被修建的查询需要的数据在哪些segments上;这个segments经常按照时间被修剪,也可以按照你datasource分区时的属性进行修剪;broker确定Historical还是MiddleManager服务于这些segments,然后发出子查询向Historical和MiddleManager,Historical和MiddleManager处理这些查询,并返回结果,broker汇总结果,最终返回给调用者;
broker裁剪是druid限制每一个查询扫描数据的关键方法,但不是唯一途径;broker可以采用更细粒度的过滤器进行裁剪,segments内部索引结构允许druid指出过滤器匹配的数据,在查看任何原生数据之前;一旦druid知道匹配了一个特定查询哪些行,他就会访问查询的指定列;druid可以在行之间进行跳跃,避免读取查询过滤器不匹配的数据。
druid最大化查询性能的三种技术
- 为每一个查询修剪访问的segments
- 在每一个segment中,使用索引确定要访问的列
- 在每一个segment中,只读取特定查询的特定行和列
额外依赖
Deep storage
Druid使用deep stroage只作为一个数据的备份和一种druid内部处理转化数据的方式。为了相应查询,Historical预先拉取segment从你的本地硬盘,而不是deep stroage;这意味这druid在一个查询期间从不需要访问deep stroage,最少的降低延迟;这也意味着为了在deep storage和Historical处理你将要加载的数据,你必须有足够硬盘空间。
Metadata storage
存储各种各样的系统元数据
MySQL
metadata storage被访问的节点(only)
- Indexing Service Nodes
- Realtime Nodes
- Coordinator Nodes 只有overlord 和Coordinator能够直接访问Metadata storage
Zookeeper
druid使用zookeeper管理集群状态,使用场景 - Coordinator选举 - segment publishing协议从Historical和Realtime - segment 加载/删除协议在Coordinator和Historical - Overload选举 - Indexing Service管理任务
Task
Task Overview
tasks 跑在MiddleManager和总是操作单一的数据源 tasks 通过post请求发送到Overlord节点
几种不同的tasks类型
Segment Creation Tasks
- Hadoop Index Task
- Native Index Tasks
- Kafka Indexing Tasks
- Stream Push Tasks (Tranquility)
Compaction Tasks
Segment Merging Tasks
Indexing Service
Indexing service是一个跑关于task索引的、高可用、分布式服务。
Indexing tasks 创建了Druid的segments;Indexing service有一个主从架构。
Indexing service 主要由3个组件构成:a Peon、 a MiddleManager、a Overlord。
a Peon 跑一个单一的task;一个MiddleManager包含多个peons,an Overlord管理多个分布式任务到MiddleManager。
当MiddleManagers和peons总是跑在相同的节点时,Overlords和MiddleManager或许跑在同一个节点或跨越多个节点









 京公网安备 11010802041100号
京公网安备 11010802041100号