转自 CAAI会员中心

0 引言
本文谈谈我在语言与视觉的跨模态智能研究与产业应用方面的一些思考。
在人工智能领域中,模态是指智能体接收和输出信息的特定方式。当前人工智能领域研究的主要模态包括语音、文本、图像、视频等。近30来,计算机及相关技术的高速发展产生了大量的不同模态的信息(语音、文本、图像、视频,以及多样的结构化数据等),并进而催生出针对不同模态的专业领域研究,例如人类语言技术(Human Language Technology,HLT)、计算机视觉(Computer Vision,CV)等。

123
何晓冬

语言与视觉的跨模态智能
近年来,基于深度学习技术,语言和视觉等单一模态研究领域取得了突破性的进展,比如在人脸识别、物体识别与检测、图像生成、语音识别与合成、语义理解、机器翻译、机器应答及对话系统等单模态方向,智能体的表现已经在很多特定的数据集上达到与人相当的水平。这些研究成果也已在现实生活中落地成为重要的应用。但另一方面,随着单一模态的基础问题逐步得到解决,研究人员也意识到更高层次的人工智能任务往往涉及到更复杂的跨多个模态的信息处理问题,需要对跨模态信息处理进行研究。同时,单一模态专业领域的研究往往局限于某种特定模态的信息,未能充分利用跨模态信息的优势,而人类对复杂的智能任务的处理往往是基于不同神经中枢联动地处理各种模态信息进行的,不只是单单地利用某一种中枢进行任务处理。鉴于此,跨模态研究受到越来越多的关注,并逐步成为人工智能领域下一阶段的重要研究课题。
鉴于跨模态研究方向的重要性,本文将从表征学习、跨模态信息融合和典型应用三个角度简要介绍近年来跨模态领域,特别是语言与视觉跨模态领域的主要研究方向及相关研究进展,并探讨跨态方向未来的研究趋势。
1 研究发展状况
语言与视觉跨模态领域的研究可从以下3个角度来进行归纳。
1.1 跨模态表征学习
跨模态表征学习研究将多个模态数据所蕴含的语义信息投影到连续向量表征空间以进行信息融合和推理(见图1)。与单模态表征学习(如文本表征模型Deep Structured Semantic Models (DSSM)、Bidirectional Encoder Representations for Transformers(BERT)等)往往只关注单一模态数据自身的特点不同,跨模态表征学习需要同时从多个异质信息源(例如视觉、文字、语音等)中通过联合学习提取被研究对象的特征,并需要 将不同模态的语义信息投影到一个统一的表征空间。之前常用模型包括Deep Multimodal Similarity Models (DMSM)等模型,而近期在单一文本模态BERT的启发下提出的一系列图像/视频与文本融合的模型,比如VL-BERT等代表了这个方向的最新研究展。跨模态表征学习还包括通过建立跨模态的统一的语义空间将信息富集的模态上学习的知识迁移到信息匮乏的模态,比如跨模态的小样本学习、领域自适应等。该研究方向旨在对于缺乏标注数据、样本存在大量噪声,以及数据收集质量不可靠的情况下,尝试将其他模态上学 习到的知识迁移到目标模态,以提高其性能。
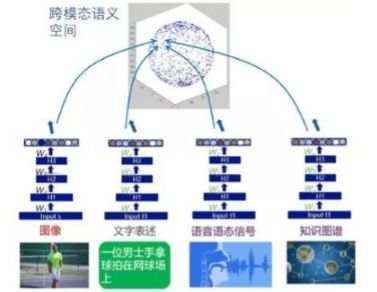
图 1 跨模态语义空间与表征学习
1.2 跨模态信息融合
跨模态信息融合研究如何融合不同模态的信息,以完成复杂的跨模态任务。信息融合的研究包括整合不同模态间的模型与特征,从而得到整合的表征输出。跨模态融合能获取更丰富的信息,提高模型的鲁棒性与准确性。常见的融合模型包括跨模态紧致双线性池化(Multimodal Compact Bilinear Pooling,MCB)等方法。这为下游的具体应用,如视觉问答(Visual Question Answering,VQA),提供了跨模态整合后的信息输入。跨模态信息融合的研究也包括研究不同模态之间的元素(比如视觉模态中的物体、姿态,以及语言模态中的实体、概念等)的对应关系。一方面,跨模态元素的对齐是一种更细粒度的映射关系,可以有效帮助提升跨模态映射任务;另一方面,跨模态数据对齐也可以帮助学习更优的跨模态表征。例如从图像中识别出实体,并与文本里的实体甚至知识图谱等结构化数据构建链接关系,以帮助构建跨模态知识,以及更好地提升跨模态信息理解。常见的跨模态对齐(Grounding)算法往往基于注意力模型(Attention),包括堆栈注意力网络(Stacked Attention Networks,SAN),自底向上和自顶向下的双向注意力模型(Bottom-Up and Top-Down(BUTD)Attention)等。
1.3 跨模态智能应用
典型的语言和视觉跨模态任务,包括图像/视频转文字(Image/Video Captioning)、文字转图像 (Text-to-Image Synthesis)、视觉问答(VQA)、跨模态检索(Cross Modal/Media Retrieval)、视觉+语言导航(Vision-and-Language Navigation)、跨模态人机对话与交互(Multimodal Dialogue and HumanComputer Interaction)等。这些任务一方面驱动了跨模态智能各方面的基础研究,另一方面也在实际场景中得到了广泛的应用。随着跨模态研究的深入,更多的应用还将被提出。
2 前景和机遇
在上面提到的研究方向之外,以下3个研究与应用方向在未来也有很大的发展空间。
2.1 跨模态常识知识学习
近年来学术界提出多个跨模态知识库和数据集,如MS-Celeb-1M包含了1000万张图片, 支持对全世界100万知名人物的识别及与知识库中的人物实体信息进行链接。进一步,我们也可从海量图像与视频内容中自动构建结构化的常识知识(Common-sense Knowledge)以帮助语义理解。图像与视频数据往往包含了广泛的日常事实。以其作为输入,借助目标检测、实体链接,自底向上和自顶向下的注意力机制(BUTD Attention)和自注意力机制(如视觉Hierarchical Attention Networks(HAN)) 等技术挖掘出海量视觉信息中的海量事实,比如实体、动作、属性、概念、及它们之间的关联等,从而构建广泛的、结构化的常识模型。构建出的常识模型可以帮助需要常识推理的应用,例如自然语言理解、机器阅读、视觉问答(VQA)等。该方向的研究重点包括:① 如何定义常识,并构造视觉与常识跨模态数据集;② 提出新的跨模态常识学习算法;③ 构造新的认知任务以体现常识的关键作用,以验证算法的进展;④常识更新机制等,均是亟待解决的问题。
2.2 跨模态情感智能
高级的情感智能是人类特有的一种认知能力。人类的交流天然是情感丰富的,并且往往跨越多个模态(语言、视觉、结构化知识等)。为建造高度拟人化的人机交互智能体,机器需要能理解以及生成跨模态的情感内容,能与人进行有同理心的跨模态情感交流。这个方面的基础研究不但可帮助我们理解认知智能机理,也有很大的实际应用价值。比如目前直播,以及短视频等文娱媒介极大地满足了众多用户的情感寄托需求,由此积累了大量用户,产生巨大商业价值。在这个方向业界已经有了一些尝试,比如微软的小冰机器人就将情感安抚作为一个主要的能力。跨模态情感智能的难点在于如何感知和对齐在不同模态下情感的微妙的表达,并保证不同模态之间数据的一致性与合理性。该任务属于跨模态研究的跨模态融合问题,目前该问题尚未有成熟的相关研究。
2.3 大规模复杂任务导向跨模态智能人机交互系统
服务产业智能化对人工智能技术而言是个巨大的机遇,也是个巨大的挑战。以电商为例,在业务不断拓展的背景下,电商产业面临的是超大规模的数据应用和零售全链条复杂人机交互的场景,需要对10亿级别的用户提供个性化的高效率的零售服务体验,所以急需大规模复杂任务导向跨模态智能人机交互技术的支撑。为此,在推动开源开放跨模态人机交互系统框架,构建大规模数据集和算法验证平台,开展跨媒体信息智能技术的基础研究等几个方面均充满机遇。而在这些方面的基础研究和技术突破也将为更广泛的服务产业的智能化提供支撑。
3 总结
语言与视觉跨模态智能的研究关注于将偏感知的视觉智能与偏认知的语言智能相结合,使得智能体能获取更全面的能力。目前跨模态的研究尚处于初级阶段,是新兴的研究方向,但却是人工智能发展历程上的重要节点。如何建造具有多重模态感知能力的智能体,并利用不同模态数据之间的联系来提升智能体对世界的认知能力是一个重要的课题。本文对跨模态研究的背景和研究方向做了简单的梳理,希望能进一步激发人工智能学者对语言与视觉跨模态研究的兴趣,推动这一研究领域的进展。
(参考文献略)
选自《中国人工智能学会通讯》
2020年 第10卷 第1期 特约专栏
何晓冬
博士、京东集团技术副总裁、人工智能研究院常务副院长、IEEE/CAAI Fellow。华盛顿大学(西雅图)等院校兼职教授。曾任多个国际一流学术期刊编委,发表了100多篇论文,谷歌学术论文引用超过1.5万次。

联系我们
地址:北京市海淀区西土城路10号
邮编:100876
电话:
010-62281360(秘书处)
010-62282983(综合办)
010-62283663(会员服务、学会通讯)
传真:010-62281360

邮箱
综合管理部:zhb@caai.cn
秘书处:msc@caai.cn
信息化与媒体宣传部:yuhui@caai.cn
出版部与编辑部:sunwl@bupt.edu.cn
会员服务:m@caai.cn

更多精彩
CAAI官方网站(http://caai.cn/)

CAAI官网微信公众号(CAAI-1981)

CAAI会员中心(CAAI-MemberCenter)

CAAI英文公众号(CAAI OFFICIAL)



点击左下角“阅读原文”,加入CAAI






 京公网安备 11010802041100号
京公网安备 11010802041100号