Bin log 用于记录了完整的逻辑记录,所有的逻辑记录在 bin log 里都能找到,所以在备份恢复时,是以 bin log 为基础,通过其记录的完整逻辑操作,备份出一个和原库完整的数据。
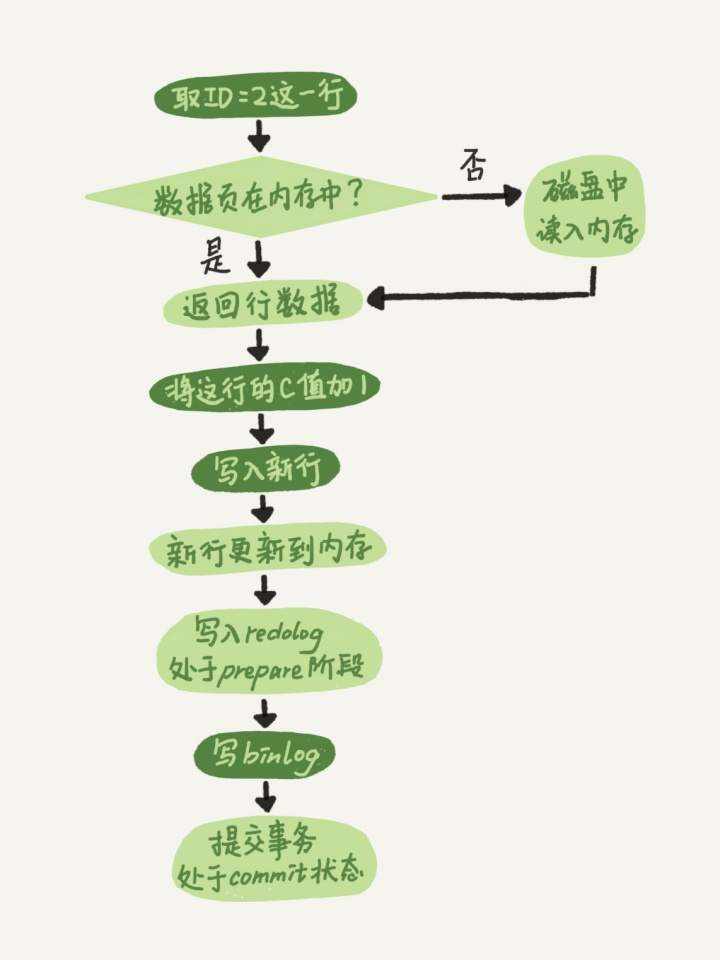
在两阶段提交时,若 redo log 写入成功,bin log 写入失败,则后续通过 bin log 恢复时,恢复的数据将会缺失一部分。(如 redo log 执行了 update t set status = 1,此时原库的数据 status 已更新为 1,而 bin log 写入失败,没有记录这一操作,后续备份恢复时,其 status = 0,导致数据不一致)。
若先写入 bin log,当 bin log 写入成功,而 redo log 写入失败时,原库中的 status 仍然是 0 ,但是当通过 bin log 恢复时,其记录的操作是 set status = 1,也会导致数据不一致。
其核心就是, redo log 记录的,即使异常重启,都会刷新到磁盘,而 bin log 记录的, 则主要用于备份。
本文深入探讨了NoSQL数据库的四大主要类型:键值对存储、文档存储、列式存储和图数据库。NoSQL(Not Only SQL)是指一系列非关系型数据库系统,它们不依赖于固定模式的数据存储方式,能够灵活处理大规模、高并发的数据需求。键值对存储适用于简单的数据结构;文档存储支持复杂的数据对象;列式存储优化了大数据量的读写性能;而图数据库则擅长处理复杂的关系网络。每种类型的NoSQL数据库都有其独特的优势和应用场景,本文将详细分析它们的特点及应用实例。 ...
[详细]









 京公网安备 11010802041100号
京公网安备 11010802041100号