问题描述:YARN莫名重启、Flink任务挂掉(脚本检测到之后自动恢复任务)
YARN后台日志
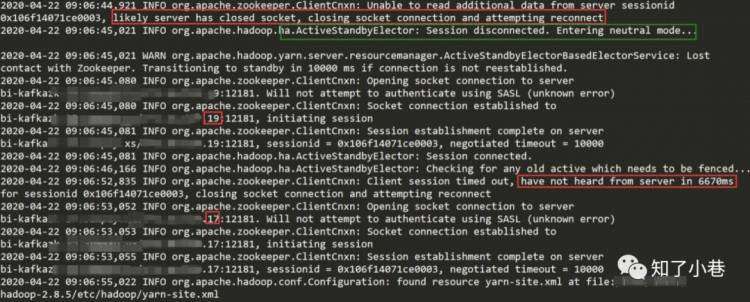
显示连不上Zookeeper并触发ResourceManager HA选举,
找不到Active的ResourceManager了。
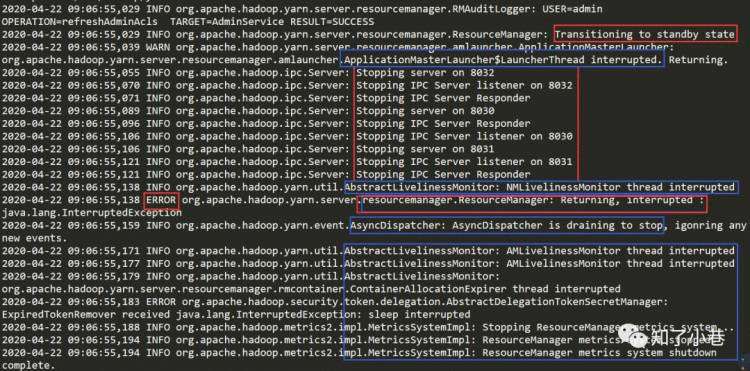
HA状态切换为standby之后,开始停止ResourceManager相关服务(8032-RM对Client的服务端口、8030-RM对AM的服务端口、8031-RM对NM的服务端口)。
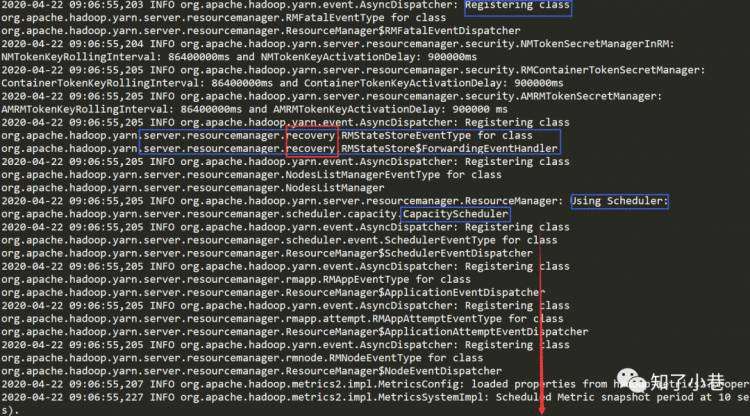
然后开始Recover,恢复RM...。
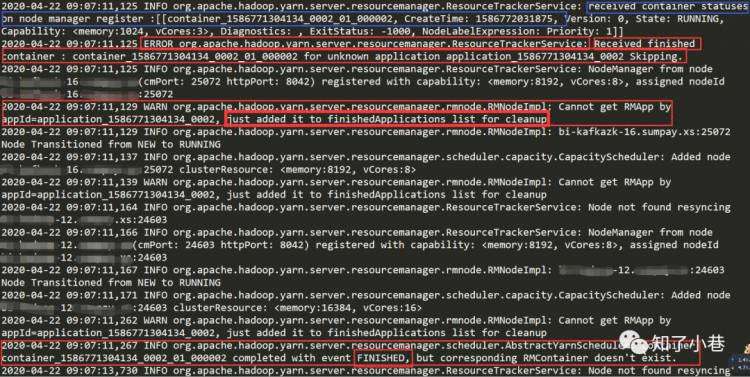
RM重启后开始接收Container状态注册(Flink任务),时间戳1586772031875 显示是2020-04-13 18:00:31创建的任务。RM发现注册的Container是未知应用,在RM上下文环境里面找不到了,然后就添加到已完成的应用列表里面了-后续清理掉。
源码简读
org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNodeImpl
private static void handleRunningAppOnNode(RMNodeImpl rmNode,
RMContext context, ApplicationId appId, NodeId nodeId) {
RMApp app = context.getRMApps().get(appId);
if we failed getting app by appId, maybe something wrong happened, just
add the app to the finishedApplications list so that the app can be
cleaned up on the NM
if (null == app) {
LOG.warn("Cannot get RMApp by appId=" + appId
+ ", just added it to finishedApplications list for cleanup");
rmNode.finishedApplications.add(appId);
rmNode.runningApplications.remove(appId);
return;
}
Add running applications back due to Node add or Node reconnection.
rmNode.runningApplications.add(appId);
context.getDispatcher().getEventHandler()
.handle(new RMAppRunningOnNodeEvent(appId, nodeId));
}
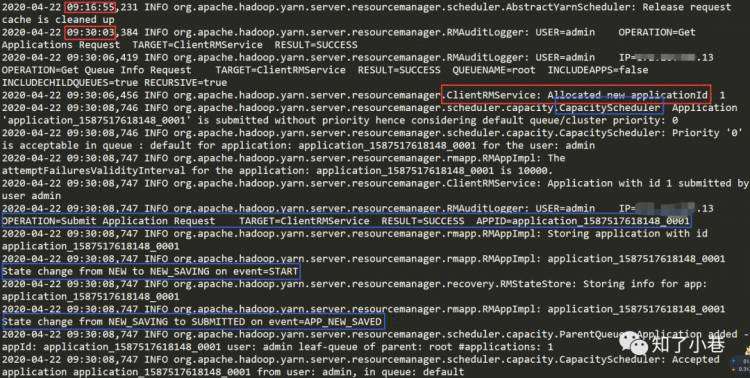
Flink任务检测脚本检测到任务挂了之后重新提交给YARN。
ZK后台日志
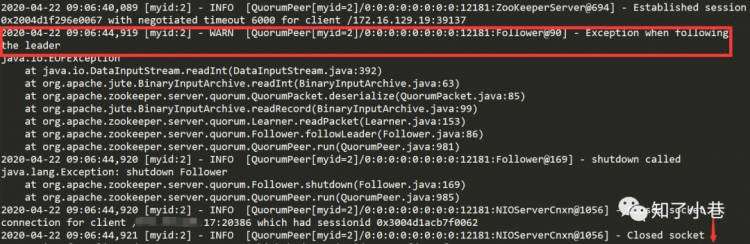
相同时间,发现WARN异常警告。session超时、然后shutdown。
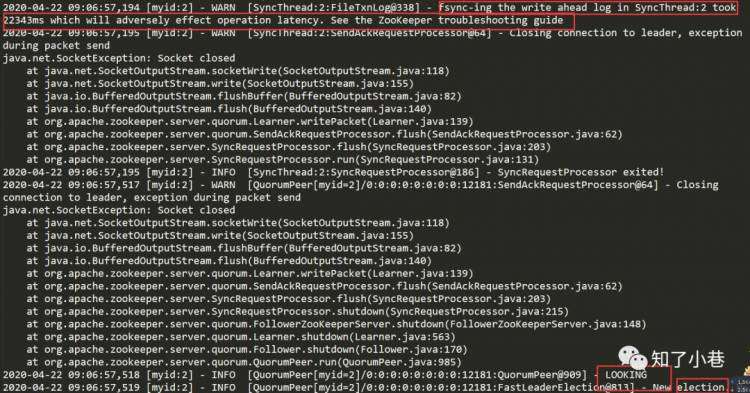
重点:WAL同步延迟,耗时约22秒,关闭了与leader的连接变为LOOKING状态,而后根据FastLeaderElection算法进行新的选举。
源码简读
org.apache.zookeeper.server.SyncRequestProcessor#flush(zks.getZKDatabase().commit();)
org.apache.zookeeper.server.ZKDatabase#commit(this.snapLog.commit();)
org.apache.zookeeper.server.persistence.FileTxnSnapLog#commit(txnLog.commit();)
org.apache.zookeeper.server.persistence.FileTxnLog#commit
/**
* commit the logs. make sure that everything hits the
* disk
*/
public synchronized void commit() throws IOException {
if (logStream != null) {
logStream.flush();
}
for (FileOutputStream log : streamsToFlush) {
log.flush();
if (forceSync) {
long startSyncNS = System.nanoTime();
FileChannel channel = log.getChannel();
channel.force(false);
syncElapsedMS = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startSyncNS);
if (syncElapsedMS > fsyncWarningThresholdMS) {
if (serverStats != null) {
serverStats.incrementFsyncThresholdExceedCount();
}
LOG.warn(
"fsync-ing the write ahead log in {} took {}ms which will adversely effect operation latency."
+ "File size is {} bytes. See the ZooKeeper troubleshooting guide",
Thread.currentThread().getName(),
syncElapsedMS,
channel.size());
}
ServerMetrics.getMetrics().FSYNC_TIME.add(syncElapsedMS);
}
}
while (streamsToFlush.size() > 1) {
streamsToFlush.poll().close();
}
// Roll the log file if we exceed the size limit
if (txnLogSizeLimit > 0) {
long logSize = getCurrentLogSize();
if (logSize > txnLogSizeLimit) {
LOG.debug("Log size limit reached: {}", logSize);
rollLog();
}
}
}
问题解决
修改ZK配置并重启集群、问题解决(if (forceSync)),但是这里也是有缺陷的,force是用来保证数据完全刷到磁盘的。设置为no后,一定程度上提高ZK的写性能,但同时也会存在类似于机器断电这样的安全风险。
另外:在没有与HBase共用ZK之前一直没有出现此异常,因此需要注意多份ZK集群的隔离部署问题。
minSessionTimeout=30000
maxSessionTimeout=60000
skipACL=yes
forceSync=no
【END】










 京公网安备 11010802041100号
京公网安备 11010802041100号