作者:小妖 | 来源:互联网 | 2023-07-17 13:07
来源:AINLPer微信公众号编辑:ShuYini校稿:ShuYini时间:2019-8-27引言 今天主要和大家分享一篇关于中文命名实体识别的文章,本文分析Lattice-
来源:AINLPer微信公众号
编辑: ShuYini
校稿: ShuYini
时间: 2019-8-27
引言
今天主要和大家分享一篇关于中文命名实体识别的文章,本文分析Lattice-LSTM模型,并针对该方法的弊端提出将字符符号信息合并到字符向量表示中,提高了模型的性能(计算量、效果)。
First Blood
TILE: Simplify the Usage of Lexicon in Chinese NER
Contributor : 复旦大学(计科院)
Paper: https://arxiv.org/pdf/1908.05969v1.pdf
Code: https://github.com/v-mipeng/LexiconAugmentedNER
文章摘要
对于中文命名实体是识别,考虑到实际生产应用,本文主要针对Lattice-LSTM模型的弊端(复杂的模型结构和计算效率低),提出了一种简洁而有效的方法,即将字符符号信息合并到字符向量表示中。 这样,我们的方法可以避免引入复杂的序列建模体系结构来对词汇信息进行建模。相反,它只需要微调神经序列模型的字符表示层。通过在四组中文基准NER数据集上的验证,可以发现该方法可以实现更快的推理速度,相对于LSTM及其衍生模型具有更好的性能。
模型的核心思想
本文的核心目标是找到一个更简单的方法来实现LSTM网格思想。即将句子中所有匹配的单词合并到基于字符的NER模型中。首要原则是实现快速的推理速度。为此,本文提出将从词典中获得的匹配词编码成字符的表示形式。与LSTM相比,该方法更加简洁,易于实现。
本文模型介绍
Lattice-LSTM模型分析
优点: 第一、它为每个字符保存所有可能匹配的单词。这可以通过启发式地选择与NER系统匹配的字符结果来避免错误传播。第二、它可以在系统中引入预先训练好的word嵌入,这对最终的性能有很大的帮助。
缺点: Lattice-LSTM模型的缺点是它将句子的输入形式从一个链式序列转换为一个图。这将大大增加句子建模的计算成本。
Proposed Model
基于Lattice-LSTM的思考,本文的设计应尽量保持句子的链式输入形式,同时保持Lattice-LSTM模型的两个优点。
首先本文提出了ExSoftWord,但是通过对ExSoftword的分析,发现ExSoftword方法不能完全继承Lattice-LSTM的两个优点。首先,它不能引入预先训练过的单词嵌入。其次,虽然它试图保持现有的匹配结果为多个分割标签,但它仍然会丢失大量的信息。 为此本文提出不仅保留字符可能的分割标签,而且保留它们对应的匹配词。 具体地说,在这种改进的方法中,句子s的每个字符c对应于由四个分段标签“bmes”标记的四个单词集。词集b(c)由在句子s上以c开头的所有词库匹配词组成。同样,m(c)由c出现在句子s中间的所有词库匹配词组成,e(c)由以c结尾的所有词库匹配词组成,s(c)是由c组成的单个字符词。如果一个词集是空的,我们将在其中添加一个特殊单词“None”来表示这种情况。
然后是将每个字符的四个词集压缩成一个固定维向量。为了尽可能多地保留信息,我们选择将四个单词集的表示连接起来表示为一个整体,并将其添加到字符表示中。
此外,我们还尝试对每个单词的权重进行平滑处理,以增加非频繁单词的权重。
最后,基于增强字符表示,我们使用任何合适的神经序列标记模型进行序列标记,如基于LSTM的序列建模层和CRF标记推理层。
实验结果
不同 v s v^s vs下本文方法的F1得分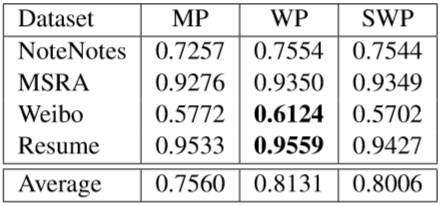 是否使用bichar,所提方法对OntoNotes上的训练迭代次数对比。
是否使用bichar,所提方法对OntoNotes上的训练迭代次数对比。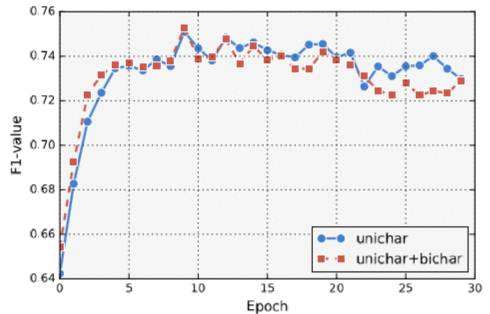 与Lattice LSTM和LR-CNN相比,本方法在不同的序列建模层下的计算速度(平均每秒句子数,越大越好)。
与Lattice LSTM和LR-CNN相比,本方法在不同的序列建模层下的计算速度(平均每秒句子数,越大越好)。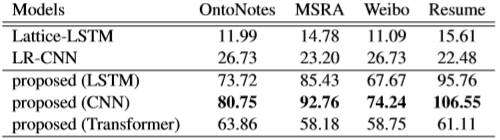 在OntoNotes上的性能[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FLk0EcCH-1579348245258)(https://upload-images.jianshu.io/upload_images/18628169-11860b35824b525a.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/540)] 在MRSA上的性能
在OntoNotes上的性能[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FLk0EcCH-1579348245258)(https://upload-images.jianshu.io/upload_images/18628169-11860b35824b525a.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/540)] 在MRSA上的性能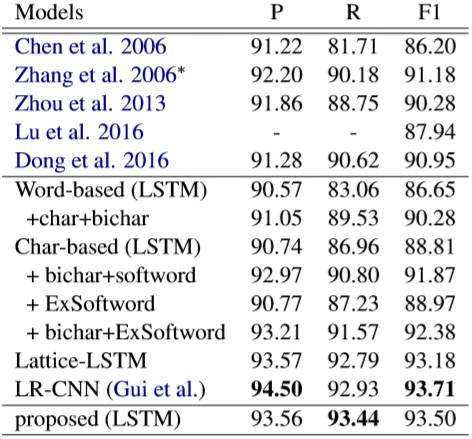
ACED
Attention
更多自然语言处理相关知识,还请关注**AINLPer**公众号,极品干货即刻送达。








![python的交互模式怎么输出名文汉字[python常见问题]](https://img1.php1.cn/3cd4a/24cea/978/9f39a0b333a15215.gif)



 京公网安备 11010802041100号
京公网安备 11010802041100号