雷锋网AI科技评论编者按:自然语言并不等于英语。然而,目前NLP的研究中,大家潜意识里却认为英语是一种具有足够代表性的语言。而除英语以外的其他语言研究则通常被认为是“特殊语言”,在
雷锋网AI科技评论编者按:自然语言并不等于英语。然而,目前NLP的研究中,大家潜意识里却认为英语是一种具有足够代表性的语言。而除英语以外的其他语言研究则通常被认为是“特殊语言”,在审稿人的眼中同等情况下对它们的研究则不如英语研究重要。这本质上是对语言的“以偏概全”。近日华盛顿大学语言学家Emily M. Bender为此撰写了一篇文章《The Bender Rule: On Naming the Languages We Study and Why It Matters》,指出其中存在的问题,以及提出对学习语言进行命名和标记的方案。AI科技评论对其文章做如下不改变原意的编译。
一、高资源语言与低资源语言
自然语言处理(NLP)领域的进展取决于语言资源的存在。通常这些资源需要有带黄金标准(gold standard)的标签或注解来反映NLP系统对当前任务的预期输出。无监督、弱监督、半监督或远程监督等机器学习技术降低了对标记数据的依赖性,但即使是使用这些方法,也同样需要足够多的标记数据来评估系统的性能,此外对于数据需求量极大的机器学习技术,通常也需要大量未标记数据的支撑。
这样的需求导致了在NLP领域中出现了高资源语言和低资源语言的数字鸿沟。
高资源的语言种类只有几种,包括英语、汉语、阿拉伯语和法语,或许还可以将德语、葡萄牙语、西班牙语、芬兰语包括进去。这些语言具有大量可访问的文本和语音资源,以及一些注释资源如树图资料库(treebank)和评估集。
截止到2019年8月,LRE Map列出了961项英语资源,此外还有美式英语资源121项、德语资源216项、法语资源180项、西班牙语资源130项、汉语资源103项、日语资源103项。其他超过50项资源的语言只有葡萄牙语、意大利语、荷兰语、标准阿拉伯语和捷克语。世界上另外大约7000种其他的语言则只有极少的资源或没有。
同样值得强调的是,世界各地的研究人员在主要的NLP会议上发表的大部分研究工作都集中在高资源语言上,且不成比例地集中在英语上。Robert Munro,SebastianMielke和我对NLP领域的几个主要会议中的语言进行了一个调查,其结果如下:
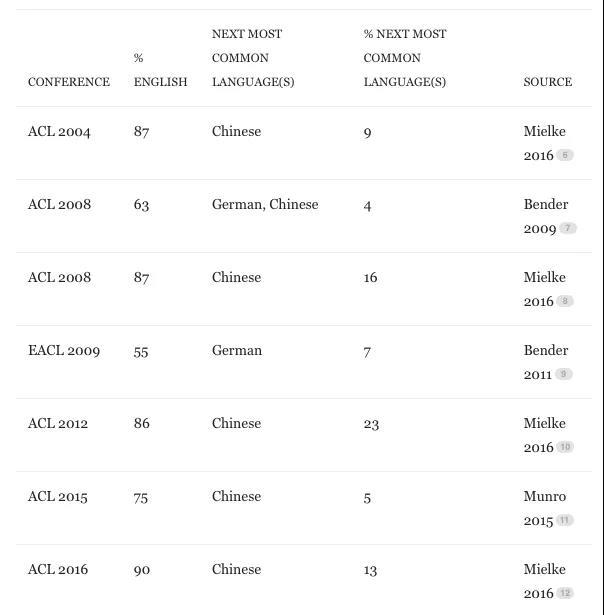
尽管英语和汉语广泛被作为第一语言或第二语言使用,但显然NLP的研究不应当只是去做这两种语言的研究。
但很不幸,NLP陷入了一种恶性循环:除英语以外的其他语言研究通常被认为是“特殊语言”,因此被认为同等情况下不如英语研究重要。
NLP会议的审稿人经常会有这样一种错误的理解:将某一任务上的最先进水平等同于该任务在英语上取得的最先进水平;如果一篇论文不能与之进行比较,那他们就无法判断这个研究是否是“有价值的”。
这里一个重要的因素是人们潜意识里认为英语是一种具有足够代表性的语言。当学习的资源是英语时,人们往往不会在名字中显示“英语”,这更助长了这种误解。
但英语既不是自然语言的代名词,也不是自然语言的代表。
二、英语不能代表全部
我最近在Widening NLP 2019大会的演讲中做了一个比喻,将NLP比作是一扇溅满了雨水的窗户。

我们知道NLP是一个跨学科的领域,不同领域的人所关注的视角也不相同。从事信息提取工作的人对用数字化语言编码的信息感兴趣,这就像是人在屋内凝视窗外的场景。而从事语言学工作的人则对语言的结构和模式以及它们与交际意图的关系很感兴趣,这就类似于想要探究雨滴下来的模式以及它们是如何影响我们看窗外的景色。
把这个比喻再延伸一点,每一种语言(包括英语)都只是一扇有特定雨滴模式的窗户,各自都有它自己特有的风格。
以下我罗列了一些英语不能代表所有语言的原因,这些原因即使是在四姐上使用最广泛的语言中也没有得到广泛的共享:
1、它是一种口头语言,而不是符号语言。如果我们只做英语的研究,我们就错失了一类重要的语言。
2、它有一个完善的、长期使用的、大致是基于发音拼写系统(phone-based orthographic system)。
“Phone-based”的意思是字母对应于单独的发音。英语拼写法仅近似于这个原理。西班牙语等其他语言,具有基于发音的拼写法系统更加透明化,还有一些语言仅代表辅音(例如传统的希伯来语和阿拉伯语)或具有代表音节而不是单一声音的符号(例如马拉雅拉姆语,韩语或日语假名),或者使用逻辑系统(例如中文,或者借鉴汉字形成的日文;参见Handel 2019)。 当然,世界上还有许多语言没有书面语,或者书面语的历史较短还没有发展出标准的拼写法。英语拼写的标准化事实上在很大程度上简化了NLP的任务,而我们常常没有意识到这个问题。
3、英语的标准化拼写法提供了一个成为“word”的概念,不同“word”之间会有一个空格留白。
然而并不是所有语言都有这个特点,例如汉语、日语、泰语等,对于这些语言,它们的NLP任务都必须从分词开始。
4、大部分的英语写作通常只使用在每台计算机上都能找到的低位ASCII字符。
在大多数情况下,当使用英语时我们都不用担心不常见的字符编码、不支持的Unicode符号等等。
5、英语的屈折形态(inflectionalmorphology)相对较少,因此每个单词的形式比较少。
许多NLP领域的技术都存在数据稀疏的问题,只有当同一个词以多种不同的形式出现在高度变化的语言中时,这种问题才会显得更加严重。(基于字符n-gram的深度学习模型在一定程度上解决了这个问题,但它仍然是英语和世界上许多语言之间的一个重要区别。)
6、英语有相对固定的语序。
与世界上许多语言相比,英语在词序上比较死板,在大多数情况下都保持主谓宾、形容词在名词前面、关系从句在后等等。如果不对更灵活的词序语言进行测试,我们怎么会知道哪些系统在多大程度上依赖英语的这种特性?
7、英文表单可能会“意外”匹配数据库字段名、本体条目等。
许多语言技术通过将输入语言中的字符串映射到外部知识库或者将这些字符串转换为语法或语义表示从而实现特定任务的目标。当输入的字符串和知识库中的字段名或条目使用同一种语言时,处理快捷方式就可用了。但是这又能适用于多少种语言呢?
8、英语有大量可用的训练数据(比如用来训练BERT的3.3B语言符号)(Devlin et.al,2019)。
如果我们将全部的精力都集中在依赖大量的训练数据这种方法上,而这些数据却无法适用于世界上大多数的语言,我们将如何构建适用于其他语言的系统?同样,如果我们只重视使用这些技术的工作(例如在会议论文评审中),那么我们怎么可能期待在跨语言NLP上取得进展呢?
三、Bender Rule
2009年,Tim Baldwin和ValiaKordoni在EACL上组织了一个研讨会,主题为“语言学与计算语言学之间的互动:良性的、恶性的还是空洞的?”(The Interaction between Linguistics andComputational Linguistics: Virtuous, Vicious or Vacuous?)当时,机器学习(深度学习之前)对NLP来说非常重要。很多人都在讨论围绕NLP的机器学习方法如何能够更经济,因为它们比以前基于规则的范式需要投入的语言专家更少。这在当时很流行。
在这次会议上有人指出(出现在当时部分论文中),不对任何特定语言知识进行编码的NLP系统都是与“语言无关的”。
我反对这种观点。我在其中的一个研讨会上也发表了一篇论文,题为《语言幼稚!=语言独立:为什么NLP需要语言类型学》(Linguistically Naïve != Language Independent: Why NLP NeedsLinguistic Typology)。我认为如果我们只使用英语(或英语加上一小部分其他语言),我们无法判断所构建的系统是否真正适合于所有语言。仅仅因为没有直接编码有关英语的特定语言知识并不意味着该模型适用于所有的语言。
此外,如果目标是语言独立或跨语言应用系统,那我们最好充分利用语言知识。特别是,我们应该利用语言类型学领域的研究成果,该领域研究世界上各种语言的变化范围以及这种变化还存在的局限性。
在Bender 2011(《关于实现和评估在NLP领域中的语言独立性》,“On Achieving and Evaluating Language-Independence in NLP”)中,我列出了语言无关NLP的“dos and don' ts”。它包括了后来被称为Bender Rule的早期声明(雷锋网(公众号:雷锋网)):
Do – 指明正在学习的语言类型,即使它是英语。要明确一点,我们正在研究的是一种特定的语言,这意味着由此开发的技术可能只适用于特定的语言。相反,如果不去声明正在使用的数据的语言类型,就会给工作带来是语言独立的假象。(Bender 2011:18)

然而,直到2019年,这段话才真正流行起来。2018年11月,当我在编撰计算语义学和语用学的语言资源时,再次遇到这样头疼的事情:那些使用英语语料的论文往往没有说明所讨论的语言是英语。于是我发了如下的推文:
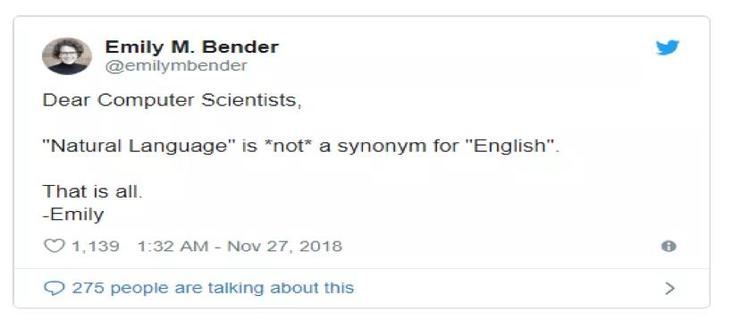
2019年3月到5月,Nathan Schneider、Yuval Pinter、Robert Munro、Andrew Caines等人分别提出了“Bender Rule”或“Bender Clauses”。他们的不同之处在于命名所研究语言的方式,作为论文评审人员应该询问研究者研究的是哪种/些语言,或者当仅使用一种语言时应当对所研究系统的语言独立性持怀疑态度。最终,BenderRule的声明合并为简单的一句话:始终注明你正在使用的语言。
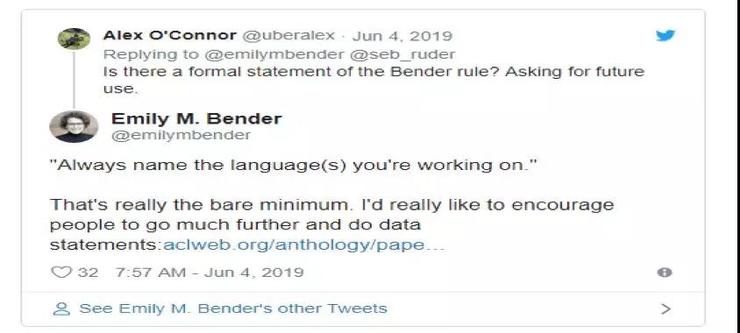
在NAACL 2019和ACL 2019及其研讨会上,有几张poster在命名其语言时直接提到了Bender Rule。
这样的原则似乎是显而易见的,且很琐碎。但我很荣幸能以我的名字来命名这个原则。因为我强烈地感觉到NLP领域必须扩大范围,超越英语和少数几种精心研究的语言。我相信,除非我们不再把英语当作默认语言,不再假装学习英语(且只学习英语)不是“language-specific”,否则我们永远无法做到这一点。
四、命名语言只是第一步
NLP领域开始考虑“为语言命名”使我深受振奋,即便大部分工作使用的显然还是英语。
但是,随着NLP领域的人们开始解决NLP技术所带来的道德影响以及语言技术对用户和旁观者产生的负面影响(参见Hovy&Spruit 2016,Speer2017,Grissom II 2019),我们应当清晰地认识到:关于训练和测试模型所使用的数据,我们应该提供更多信息。
首先是语言之间的差异性:所有语言都在不断地变化;除了那些使用人数极少的语言外,一种语言的不同变体之间总是存在着很大的差异。(参见Labov 1966,Eckert和Rickford2001)。这包括不同地域之间的差异,以及不同社会群体和社会身份相关的差异。针对某一特定人群的语音/文本/标志进行训练的模型不一定适用于其他人群,即使是在使用相同语言的人群中也是如此。
第二,模型会汲取训练文本中所包含的偏见,而这些偏见则来源于生产文本的人如何认识和谈论这个世界。(参见Bolukbasi et.al 2016,Speer2017)。
为了避免以上两个问题所带来的潜在问题,Batya Friedman和我在 ( Bender & Friedman2018) 中提出了“数据声明”的概念,这是一种清晰记录NLP系统中使用数据集的做法。我们建议所有NLP系统都应该附带关于训练数据的详细信息,包括所涉及的特定语言种类,选择数据的原理(如何选择数据以及为什么选择该数据),有关说话者和注释者的人口统计信息等等。当然,仅凭这些信息并不能解决偏见的问题,但它为解决这些问题提供了可能性。

头图来源(雷锋网):http://images.wired.it/wp-content/uploads/2014/01/1390576102_language.jpg
原文链接:https://thegradient.pub/the-benderrule-on-naming-the-languages-we-study-and-why-it-matters/
。



![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号