作者:吸毒草的秘密 | 来源:互联网 | 2023-09-18 17:53
前两天写了一篇关于AIOPS演进路线的文章,有些朋友对AIOPS为什么还要先走ALPHAGO 1.0的道路,学习运维专家的经验,而不能直接采用更为先进的ALPHAGO 2.0的模式,直接采用AI自己的数据去训练算法。其实如果没有ALPHAGO 1.0的基础,ALPHAGO 2.0也是不能凭空发展出来的。ALPHAGO 1.0已经具有相当高的水平了,连人类的顶级选手李世石都仅能侥幸赢下一局。因此可以说ALPHAGO 2.0的起点已经是相当高的了。对于AIOPS也是如此,这三十年来,人类已经积累了十分丰富的运维经验,其复杂度已经不亚于围棋了。以数据库IO分析为例,老白先展示一个专家梳理出来的数据库IO分析的诊断路径图。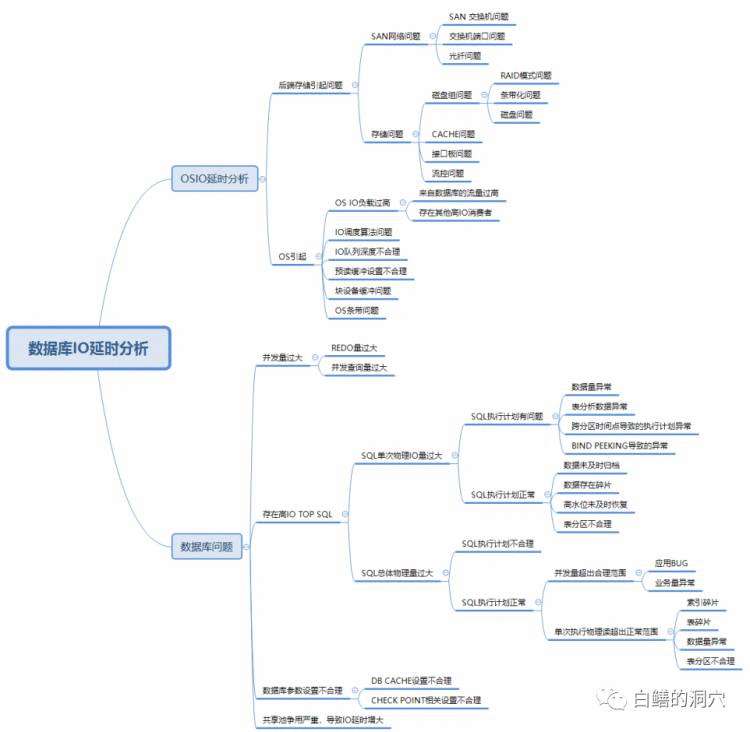
这张图仅仅列出了一部分诊断路径,并不完整,可以看出这张图已经是十分的复杂了。如果不依赖专家经验的梳理,仅仅通过异常检测,要想在一两年内收集齐这张诊断路径图中的所有的故障样本就已经是一个几乎不可能完成的任务了。更不要说每条诊断路径都需要至少几十个甚至几百个样本才能完成较为有效的模型训练。我曾经和不少做AIOPS的专家讨论过这个问题,有些人比较实在,看到这张图后立马就说,这么复杂的分析,我想是做不到的。还有一些嘴硬的,说没任何问题,你把数据给我收集齐了,我们立马能做出来。虽然老白收集了不少数据,但是想要收集齐所有的数据,自认为是做不到的,于是也只能姑且认为他们能做到了。也有人和老白说,那些指标异常检测确实复杂,不过日志分析就简单多了。于是老白又拿出一张图让他试试。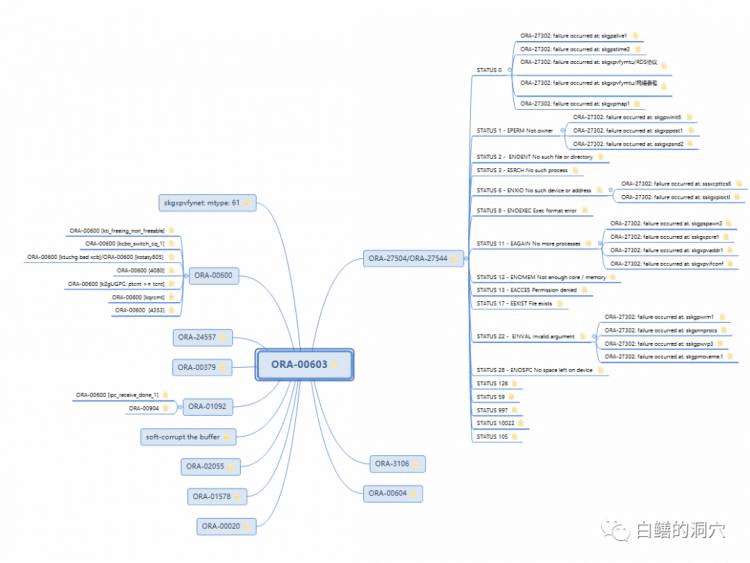
ORA-603这个ORACLE的错误号,其可能的问题根因有几十个,老白这张图中仅仅是列出了其中的一部分。我让他们评估一下训练这个模型大概要花多少钱。他比较实在,直接说这种模型训练不出来。不过随后又说,日志监测不是这么做的,不是通过单一的错误日志去分析问题,是通过一定时期内的长时间的日志的学习,来形成异常检测的算法的。因为系统中99%以上的时间里系统都是正常的,只有不到1%的日志状态是异常的。所以只要有足够的标注,就能够形成有效的模型。我又问他大概需要标注多少样本才能达到他所说的目标,开始他说大约几千,我就给他算了笔帐,就按1000算吧,如果一个客户每10天出一次故障,大约一年可以获得40个样本,他所需要的样本需要积累25年。对于10天出一次故障的运维单位,它的领导恐怕早就干不下去了吧。算了这笔账后他说日志异常检测不是这么做的,不是通过单一运维对象的日志去做分析,而是通过综合的日志序列,进行综合性的计算,从而形成模型,用于预测。
这似乎有点道理,不过问题又来了,通过综合性的日志分析,形成异常发现后,我们如何去确认这个问题发现是否准确呢?如何进一步定位问题出在哪里呢?他十分自信的说,哪个服务宕机了,哪个数据库无法访问了,可以很快就定位了啊。我总觉得这句话有点问题,哪个数据库无法访问,哪台服务器宕机了,用传统的方法不是很容易就发现了吗?还需要这么兴师动众的用AIOPS的算法来解决呢?
实际上,老白是在和他开玩笑。通过日志的综合分析进行故障预测与故障定位是肯定有一定的效果的,但是这里有一个十分重要的要素,就是必须有专家的参与,否则只能是一个实验室里的玩具,无法真正的成为生产力。当异常检测发现了疑点,需要有专家来进行确认,对发现进行标注,形成有效的训练样本,这种样本只有积累到一定的数量,才能训练出有效的模型。对于某一个企业来说,要积累足够的样本是十分困难的,最好的模式是能够建立一个行业案例库和公共案例库,跨企业,跨行业积累相关的样本,这样才有可能加快这个过程。
ALPHAGO的成功是在上千年人类对围棋理论和棋谱的积累的基础上的,所以能够在数年时间里完成对人类高手的碾压。AIOPS要想碾压人类的专家,也必然要经历这个过程。仅仅是一批软件看法和算法的高手要构建出一个能够超越人类专家的AIOPS系统,还是任重道远的。只有越来越多的人能够像老白一样来梳理十年二十年来的运维经验,并把这些经验分享出来,才能够缩短人工智能的成长时间,更快的让AIOPS产生真正的实战效用。在这个新春即将来临的时刻,写这段文字与从事AIOPS的朋友们共勉。
![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)






 京公网安备 11010802041100号
京公网安备 11010802041100号