作者:ociVyouzhangzh063_1fd2bf_633 | 来源:互联网 | 2023-08-24 18:21
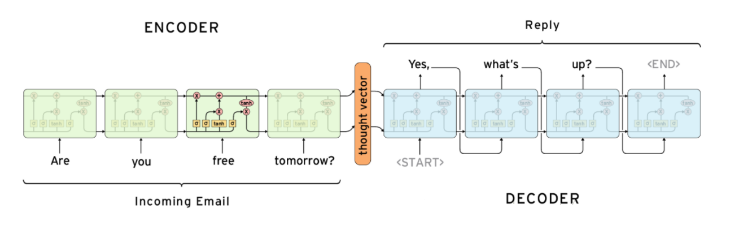
Seq2Seq 属于 Encoder-Decoder 结构。基本思想就是利用两个 RNN,一个 RNN 作为 Encoder,另一个 RNN 作为 Decoder。Encoder 负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码。Decoder负责告诉模型对应的输出是什么。两个RNN通过语义向量连接,得以实现输入与输出长度不同。
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
import pandas as pd
batch_size = 32
epochs = 100
latent_dim = 256
num_samples = 5000
data_path = './中文bot数据.txt'
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()with open(data_path, 'r', encoding='utf-8') as f:lines = f.read().split('\n')
for line in lines[: min(num_samples, len(lines))]:input_text, target_text = line.split('\t')target_text = target_text[0:100]target_text = '\t' + target_text + '\n'input_texts.append(input_text)target_texts.append(target_text)for char in input_text:if char not in input_characters:input_characters.add(char)for char in target_text:if char not in target_characters:target_characters.add(char)input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])encoder_input_data = np.zeros((len(input_texts), max_encoder_seq_length, num_encoder_tokens), dtype='float32')
decoder_input_data = np.zeros((len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype='float32')
decoder_target_data = np.zeros((len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype='float32')for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):for t, char in enumerate(input_text):encoder_input_data[i, t, input_token_index[char]] = 1.for t, char in enumerate(target_text):decoder_input_data[i, t, target_token_index[char]] = 1.if t > 0:decoder_target_data[i, t - 1, target_token_index[char]] = 1.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.summary()
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,batch_size=batch_size,epochs=epochs,validation_split=0.2)
model.save('s2s.h5')
encoder_model = Model(encoder_inputs, encoder_states)decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs,[decoder_outputs] + decoder_states)
reverse_input_char_index = dict((i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict((i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):states_value = encoder_model.predict(input_seq)target_seq = np.zeros((1, 1, num_decoder_tokens))target_seq[0, 0, target_token_index['\t']] = 1.stop_condition = Falsedecoded_sentence = ''while not stop_condition:output_tokens, h, c = decoder_model.predict([target_seq] + states_value)sampled_token_index = np.argmax(output_tokens[0, -1, :])sampled_char = reverse_target_char_index[sampled_token_index]decoded_sentence += sampled_charif (sampled_char == '\n' orlen(decoded_sentence) > max_decoder_seq_length):stop_condition = Truetarget_seq = np.zeros((1, 1, num_decoder_tokens))target_seq[0, 0, sampled_token_index] = 1.states_value = [h, c]return decoded_sentence
def predict_ans(question):inseq = np.zeros((1, max_encoder_seq_length, num_encoder_tokens), dtype='float16')for t, char in enumerate(question):inseq[0, t, input_token_index[char]] = 1.decoded_sentence = decode_sequence(inseq)return decoded_sentenceprint('Decoded sentence:', predict_ans("你是ai?"))
原文:
https://soyoger.blog.csdn.net/article/details/108729400



![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号