分类目录:《知识图谱从入门到应用》总目录
相关文章:
· 知识图谱的基础知识
· 知识图谱的发展
· 知识图谱的应用
· 知识图谱的技术结构
知识图谱是有学识的人工智能
早期的人工智能有很多持不同观点的流派,其中两个历史比较悠久的流派通常被称为连接主义和符号主义。连接主义主张智能的实现应该模拟人脑的生理结构,即用计算机模拟人脑的神经网络连接。
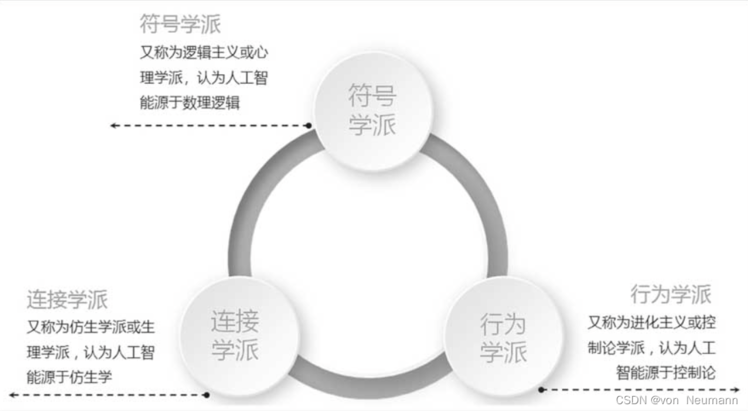
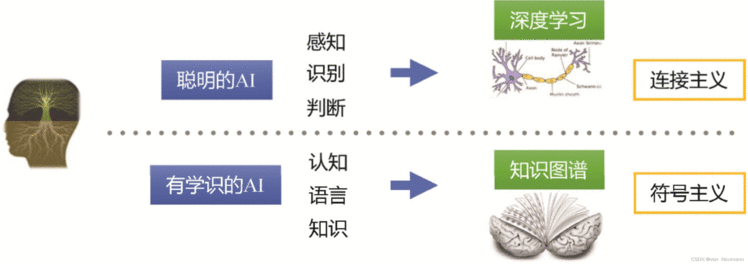
这个流派发展至今,即所谓广泛发展的深度神经网络。另外一个流派称为符号主义,主张智能的实现应该模拟人类的心智,即用计算机符号记录人脑的记忆,表示人脑中的知识,即所谓知识工程与专家系统等。深度学习首先在视觉、听觉等感知任务中获得成功,本质上解决的是模式识别的问题,可以比喻为实现的是一种聪明的AI。
但感知还是低级的智能,人的大脑依赖所学的知识进行思考、推理和理解语言等。因此,还有另外一种AI可以称为是有学识、有知识的AI。这和知识图谱有密切关系,
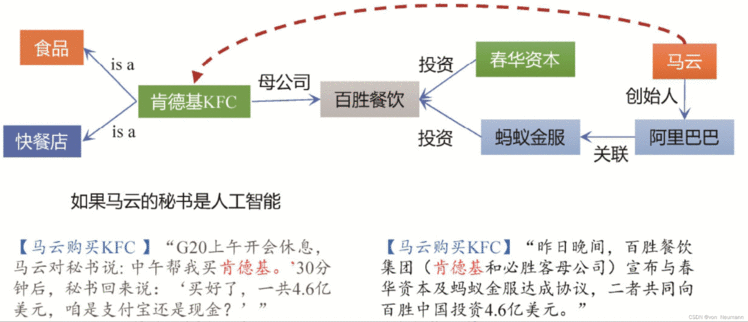
什么叫认知智能?认知智能有两个核心的研究命题,一个是语言理解,另外一个是知识的表示与处理。人类通过认识世界来积累关于世界的知识,通过学习到的知识来解决碰到的问题。比如,一位医生利用他的医学知识给病人看病。而语言则是知识最直接的载体,到目前为止,人类的绝大部分知识都是通过自然语言来描述、记录和传承的。与此同时,正确理解语言又需要知识的帮助。如下图所示,这里举一个有趣的例子:“G20上午开会休息,马云对他的秘书说:‘中午帮我买肯德基。’30分钟后,秘书回来说:‘买好了,一共4.6亿美元,咱是支付宝还是现金?’”。这当然只是个玩笑,当时的新闻是春华资本及蚂蚁金服共同向肯德基的母公司百胜餐饮投资了4.6亿美元。这里关注的是背景知识对于正确理解语言的重要性。假如马云的秘书是一个人工智能,它在第一个语境中,应该把肯德基识别为一种食品,而在第二个语境中,应该把肯德基识别为一家公司,而且它还需要知道肯德基的母公司是百胜餐饮,蚂蚁金服投资了百胜餐饮,而马云是阿里巴巴的创始人,阿里巴巴与蚂蚁金服存在关联关系,才能正确地建立马云和肯德基的关系。这个背后的事物关系网络其实就是知识图谱。事实上,每个人的大脑里面都有大量这种类型的关于万事万物之间关联关系的知识图谱,我们极大地依赖这些背景知识来准确理解语言并正确地做出判断。
以深度学习为代表的连接学派,主要解决了感知问题,也引领了这一轮人工智能的发展热潮。但是在更高层次的认知领域,例如自然语言理解、推理和联想等方面,还需要符号学派的帮助。知识图谱是符号学派的代表,可以帮助我们构建更有学识的人工智能,从而提升机器人推理、理解、联想等功能。而这一点,仅通过大数据和深度学习是无法做到的。多伦多大学的Geoffrey Hinton教授也提出,人工智能未来的发展方向之一就是深度神经网络与符号人工智能的深入结合。
知识的承载与表示方式
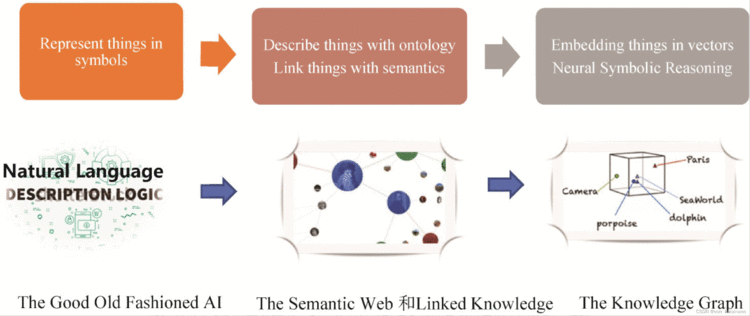
人类的自然语言,以及创作的绘画和音乐、数学语言、物理模型和化学公式等都是人类知识的表示形式和传承方式。具有获取、表示和处理知识的能力是人类心智区别于其他物种心智的最本质特征之一。传统的人工智能领域有一个经典的研究方向——知识工程和专家系统。这种经常被称为是GOFAI(Good Old Fashioned AI)的基本思想是建立一个系统,能够从专家大脑里获取知识,再通过一个推理引擎为非专家用户提供服务,如辅助诊断、判案等。而这个从人脑获取知识的过程就叫作知识工程。知识有很多种表达载体和存在形式,例如自然语言是人类知识最主要的表达载体。既然人脑能够通过阅读从文本获取和学习知识,机器脑也应该具备从文本中抽取知识的能力。但文本字符串似乎对机器不太友好,机器在理解人类语言方面仍然步履维艰。比如类似于微软小冰、苹果Siri、小米小爱音箱等产品在人机对话方面的体验仍然面临巨大的挑战。
当前,通过机器来理解文本中的知识有两大主要的技术路线。第一种是抽取技术,例如从文本中识别实体、关系和逻辑结构等;第二种是语言预训练,即通过大量的文本语料训练一个神经网络大模型,文本中的知识被隐含在参数化的向量模型中,而向量化的表示和神经网络是对机器友好的。所以,文本本身也可以作为一种知识库(Knowledge Base)。
知识图谱的本质是一种结构化的知识表示形式。简单地说,知识图谱旨在利用图结构建模、识别和推断事物之间的复杂关联关系和沉淀领域知识,已经被广泛地应用于语义搜索、智能问答、语言理解、媒体理解、推理引擎和决策引擎等众多领域,如下图所示。相比文本而言,结构化数据更易于被机器处理,比如查询和问答。同时图结构比起字符串序列能够表达更加丰富的语义和知识。

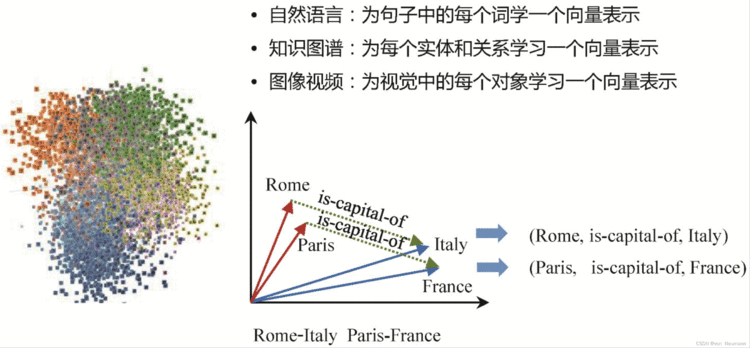
对于机器而言,图结构比文本当然更加友好。深度学习或者更为准确地说是表示学习的兴起,表明参数化的向量和神经网络是更适合机器完成快速计算的信息载体。比如,在自然语言中,可以为每个词学习一个向量表示;在图像处理中,也可以为视觉场景中的每一个对象学习一个向量表示;在知识图谱中,可以为每一个实体和关系学习一个向量表示。我们通常把这些向量化表示称为Embedding或Distributed Vector Representation。如下图所示,如果将所有数字对象的向量表示投影到向量空间,我们会发现,同一个数字对象的不同图像的向量在空间距离更近。进一步地,通过将词语、实体、对象和关系等都投影到向量空间,就可以更加方便地在向量空间对这些语言、视觉和实体对象进行操作,甚至可以利用神经网络实现逻辑推理。
知识图谱是一种世界模型知识
图谱本质上可以看作一种世界模型——World Model。纵观人工智能相关方向的发展历史,一直有一个核心的命题是寻找合适的万物机器表示,用于记录有关世界的知识。在传统的专家系统时代,人们发明了描述逻辑等符号化的知识表示方法来描述万物。人类的自然语言也是符号化的描述客观世界的表示方法。到了互联网时代,人们又设想用本体和语义链接有关互联网上发布的各种数据和知识,这也是知识图谱的起源之一。
随着表示学习和神经网络的兴起,人们发现数值化的向量表示更易于捕获那些隐藏的、不易于明确表示的知识,并且比符号表示更易于机器处理。知识图谱同时拥抱机器的符号表示和向量表示,并能将两者有机地结合起来,解决搜索、问答、推理和分析等多方面的问题。结合知识图谱、神经网络等新的人工智能技术手段,可以对专家系统进行重构。原有的知识库可以采用知识图谱的方式,让知识获取的手段更容易。除了传统的符号表示,也要考虑如何用向量表示实体、关系等知识。在知识获取方面,专家层面的经验为现代知识的构建提供了重要的输入,此外,现在还有设备传感数据、自动采集的日志数据、多种模态的数据等大量的机器数据。知识图谱在一定程度上可以起到桥梁的作用,将专家经验性的知识与机器数据通过比较有效的表示结合起来。
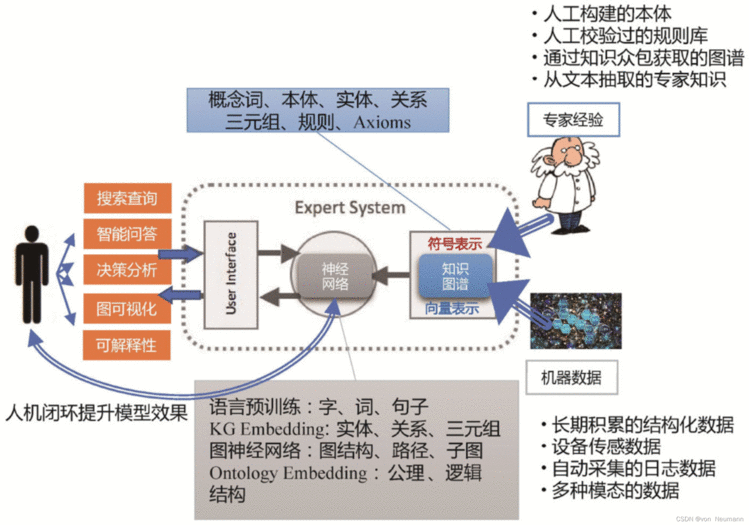
在推理引擎方面,传统的符号推理引擎有很多,由于有诸多瓶颈,例如对知识质量要求非常高,均未能实现大规模商业化应用。而现在的推理引擎可以在神经网络、表示学习等深度学习技术加持下实现更好的推理。在面向用户的交互方面,不再仅仅是简单查询,还可以实现搜索、智能问答和基于图分析的决策分析。并通过一些可视化的手段支撑对所有数据在各个维度的整体性分析,同时对所有推断结果提供可解释性。
知识图谱的定义
从上文也可以看到,知识图谱的概念是和Web、自然语言处理(NLP)、知识表示(KR)、人工智能(AI)、数据库(DB)等密切相关的。所以我们可以从以下几个角度去了解知识图谱。
- 从Web的角度来看,像建立文本之间的超链接一样,构建知识图谱需要建立数据之间的语义链接,并支持语义搜索,这样就改变了以前的信息检索方式,可以以更适合人类理解的语言来进行检索,并以图形化的形式呈现。
- 从自然语言处理(NLP)的角度来看,构建知识图谱需要了解如何从非结构化的文本中抽取语义和结构化数据。
- 从知识表示(KR)的角度来看,构建知识图谱需要了解如何利用计算机符号来表示和处理知识。
- 从人工智能(AI)的角度来看,构建知识图谱需要了解如何利用知识库来辅助理解人类语言,包括机器翻译问题的解决。
- 从数据库(DB)的角度来看,构建知识图谱需要了解使用何种方式来存储知识。由此看来,知识图谱技术是一个系统工程,需要综合利用各方面技术。
综上所述,我们可以总结出:
- 知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体–关系–实体”三元组,以及实体及其相关属性–值对,实体之间通过关系相互联结,构成网状的知识结构。
- 知识图谱以结构化的方式描述客观世界中概念、实体及其关系,将互联网的信息表示成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力。
- 知识图谱旨在建模、识别、发现和推断事物、概念之间的复杂关系,是事物关系的可计算模型,已经被广泛应用于搜索引擎、智能问答、语言理解、视觉场景理解、决策分析等领域。
- 知识图谱本质上是一种叫作语义网络的知识库,即一个具有有向图结构的知识库,其中图的结点代表实体或者概念,而图的边代表实体/概念之间的各种语义关系。
知识图谱里“实体–关系–实体”三元组我们可以这么理解:
- 实体:对应一个语义本体,例如“姚明”、“中国”等。
- 属性:描述一类实体的特性(例如“身高”:姚明的身高是229厘米)。
- 关系:对应语义本体之间的关系,将实体连接起来(例如“国籍”:姚明的国籍是中国)。
有些文章也将属性定义为关系,属于属性关系的一种。
知识图谱的模式
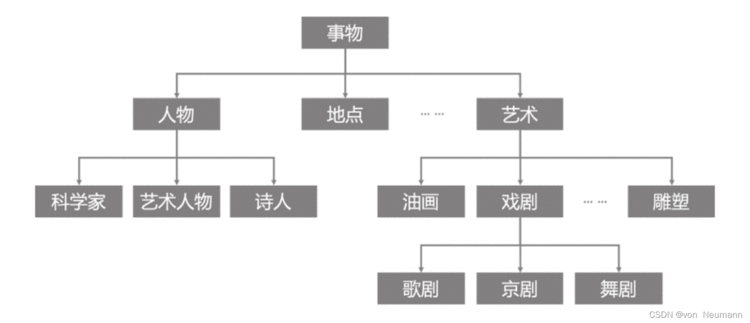
由概念组成的体系称为本体,本体的表达能力比模式强,且包含各种规则,而模式这个词汇则来源于数据库领域,可视为一个轻量级的本体。实体和概念之间通常是“是”的关系,也就是“isA”关系,比如“中国是一个国家”。而概念和概念之间通常是子集关系,如“subClassOf”,比如“篮球运动员是人的一个子集”,“国家是地点的一个子集”,一个简单的由本体所描述的模式如下图所示:
参考文献:
[1] 陈华钧.知识图谱导论[M].电子工业出版社, 2021
[2] 邵浩, 张凯, 李方圆, 张云柯, 戴锡强. 从零构建知识图谱[M].机械工业出版社, 2021








 京公网安备 11010802041100号
京公网安备 11010802041100号