这篇文章给大家介绍RabbitMQ的工作原理是什么,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。RabbitMQ简介在介绍RabbitMQ
这篇文章给大家介绍RabbitMQ的工作原理是什么,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
RabbitMQ简介
在介绍RabbitMQ之前实现要介绍一下MQ,MQ是什么?
MQ全称是Message Queue,可以理解为消息队列的意思,简单来说就是消息以管道的方式进行传递。
RabbitMQ是一个实现了AMQP(Advanced Message Queuing Protocol)高级消息队列协议的消息队列服务,用Erlang语言的。
使用场景
在我们秒杀抢购商品的时候,系统会提醒我们稍等排队中,而不是像几年前一样页面卡死或报错给用户。
像这种排队结算就用到了消息队列机制,放入通道里面一个一个结算处理,而不是某个时间断突然涌入大批量的查询新增把数据库给搞宕机,所以RabbitMQ本质上起到的作用就是削峰填谷,为业务保驾护航。
为什么选择RabbitMQ
现在的市面上有很多MQ可以选择,比如ActiveMQ、ZeroMQ、Appche Qpid,那问题来了为什么要选择RabbitMQ?
除了Qpid,RabbitMQ是唯一一个实现了AMQP标准的消息服务器;
可靠性,RabbitMQ的持久化支持,保证了消息的稳定性;
高并发,RabbitMQ使用了Erlang开发语言,Erlang是为电话交换机开发的语言,天生自带高并发光环,和高可用特性;
集群部署简单,正是应为Erlang使得RabbitMQ集群部署变的超级简单;
社区活跃度高,根据网上资料来看,RabbitMQ也是首选;
工作机制
生产者、消费者和代理
在了解消息通讯之前首先要了解3个概念:生产者、消费者和代理。
生产者:消息的创建者,负责创建和推送数据到消息服务器;
消费者:消息的接收方,用于处理数据和确认消息;
代理:就是RabbitMQ本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。
消息发送原理
首先你必须连接到Rabbit才能发布和消费消息,那怎么连接和发送消息的呢?
你的应用程序和Rabbit Server之间会创建一个TCP连接,一旦TCP打开,并通过了认证,认证就是你试图连接Rabbit之前发送的Rabbit服务器连接信息和用户名和密码,有点像程序连接数据库,使用Java有两种连接认证的方式,后面代码会详细介绍,一旦认证通过你的应用程序和Rabbit就创建了一条AMQP信道(Channel)。
信道是创建在“真实”TCP上的虚拟连接,AMQP命令都是通过信道发送出去的,每个信道都会有一个唯一的ID,不论是发布消息,订阅队列或者介绍消息都是通过信道完成的。
为什么不通过TCP直接发送命令?
对于操作系统来说创建和销毁TCP会话是非常昂贵的开销,假设高峰期每秒有成千上万条连接,每个连接都要创建一条TCP会话,这就造成了TCP连接的巨大浪费,而且操作系统每秒能创建的TCP也是有限的,因此很快就会遇到系统瓶颈。
如果我们每个请求都使用一条TCP连接,既满足了性能的需要,又能确保每个连接的私密性,这就是引入信道概念的原因。

你必须知道的Rabbit
想要真正的了解Rabbit有些名词是你必须知道的。
包括:ConnectionFactory(连接管理器)、Channel(信道)、Exchange(交换器)、Queue(队列)、RoutingKey(路由键)、BindingKey(绑定键)。
**ConnectionFactory(连接管理器):**应用程序与Rabbit之间建立连接的管理器,程序代码中使用;
**Channel(信道):**消息推送使用的通道;
**Exchange(交换器):**用于接受、分配消息;
Queue(队列):用于存储生产者的消息;
RoutingKey(路由键):用于把生成者的数据分配到交换器上;
BindingKey(绑定键):用于把交换器的消息绑定到队列上;
看到上面的解释,最难理解的路由键和绑定键了,那么他们具体怎么发挥作用的,请看下图:
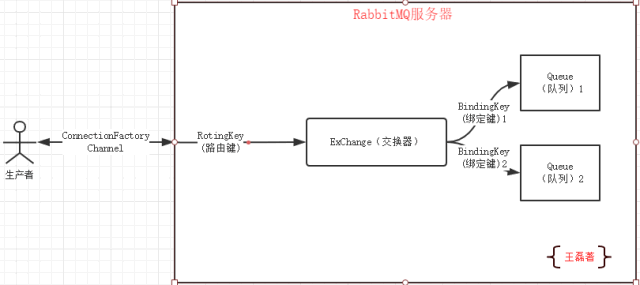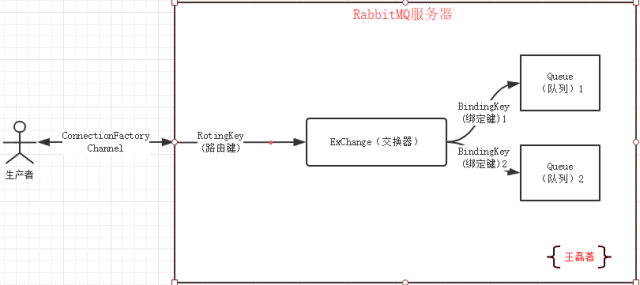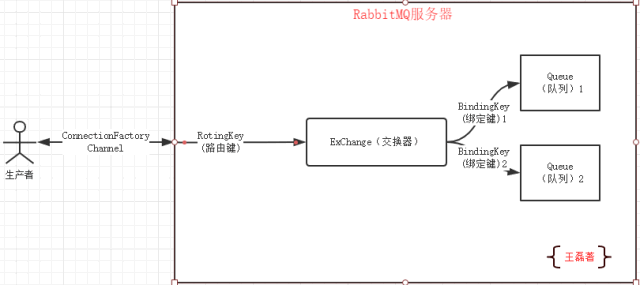
关于更多交换器的信息,我们在后面再讲。
消息持久化
Rabbit队列和交换器有一个不可告人的秘密,就是默认情况下重启服务器会导致消息丢失,那么怎么保证Rabbit在重启的时候不丢失呢?答案就是消息持久化。
当你把消息发送到Rabbit服务器的时候,你需要选择你是否要进行持久化,但这并不能保证Rabbit能从崩溃中恢复,想要Rabbit消息能恢复必须满足3个条件:
投递消息的时候durable设置为true,消息持久化,代码:channel.queueDeclare(x, true, false, false, null),参数2设置为true持久化;
设置投递模式deliveryMode设置为2(持久),代码:channel.basicPublish(x, x, MessageProperties.PERSISTENT_TEXT_PLAIN,x),参数3设置为存储纯文本到磁盘;
消息已经到达持久化交换器上;
消息已经到达持久化的队列;
持久化工作原理
Rabbit会将你的持久化消息写入磁盘上的持久化日志文件,等消息被消费之后,Rabbit会把这条消息标识为等待垃圾回收。
持久化的缺点
消息持久化的优点显而易见,但缺点也很明显,那就是性能,因为要写入硬盘要比写入内存性能较低很多,从而降低了服务器的吞吐量,尽管使用SSD硬盘可以使事情得到缓解,但他仍然吸干了Rabbit的性能,当消息成千上万条要写入磁盘的时候,性能是很低的。
所以使用者要根据自己的情况,选择适合自己的方式。
虚拟主机
每个Rabbit都能创建很多vhost,我们称之为虚拟主机,每个虚拟主机其实都是mini版的RabbitMQ,拥有自己的队列,交换器和绑定,拥有自己的权限机制。
vhost特性
RabbitMQ默认的vhost是“/”开箱即用;
多个vhost是隔离的,多个vhost无法通讯,并且不用担心命名冲突(队列和交换器和绑定),实现了多层分离;
创建用户的时候必须指定vhost;
vhost操作
可以通过rabbitmqctl工具命令创建:
rabbitmqctl add_vhost[vhost_name]
删除vhost:
rabbitmqctl delete_vhost[vhost_name]
查看所有的vhost:
rabbitmqctl list_vhosts
环境搭建
前文我们已经介绍了Ubuntu搭建RabbitMQ的步骤:RabbitMQ在Ubuntu上的环境搭建
如果你是在Windows10上去安装那就更简单了,先放下载地址:
Erlang/Rabbit Server百度网盘链接:https://pan.baidu.com/s/1TnKDV-ZuXLiIgyK8c8f9dg 密码:wct9
当然也可去Erlang和Rabbit官网去下,就是速度比较慢。我的百度云Rabbit最新版本:3.7.6,Erlang版本:20.2,注意:不要下载最新的Erlang,在Windows10上打开扩展插件有问题,打不开。
安装Erlang;
安装Rabbit Server;
进入安装目录\sbin下,使用命令“rabbitmq-plugins enable rabbitmq_management”启动网页管理插件;
重启Rabbit服务;
使用:http://localhost:15672进行测试,默认的登陆账号为:guest,密码为:guest
重复安装Rabbit Server的坑
如果不是第一次在Windows上安装Rabbit Server一定要把Rabbit和Erlang卸载干净之后,找到注册表:HKEY_LOCAL_MACHINE\SOFTWARE\Ericsson\Erlang\ErlSrv 删除其下的所有项。
不然会出现Rabbit安装之后启动不了的情况,理论上卸载的顺序也是先Rabbit在Erlang。
代码实现
java版实现,使用maven项目,创建可以查看:MyEclipse2017破解设置与maven项目搭建
项目创建成功之后,添加Rabbit Client jar包,只需要在pom.xml里面配置,如下信息:
com.rabbitmq
amqp-client
5.2.0
java实现代码分为两个类,第一个是创建Rabbit连接,第二是应用类使用最简单的方式发布和消费消息。
Rabbit的连接,两种方式:
方式一:
public static Connection GetRabbitConnection() {
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername(Config.UserName);
factory.setPassword(Config.Password);
factory.setVirtualHost(Config.VHost);
factory.setHost(Config.Host);
factory.setPort(Config.Port);
Connection conn = null;
try {
conn = factory.newConnection();
} catch (Exception e) {
e.printStackTrace();
} return conn;
}方式二:
public static Connection GetRabbitConnection2() {
ConnectionFactory factory = new ConnectionFactory();
// 连接格式:amqp://userName:password@hostName:portNumber/virtualHost
String uri = String.format("amqp://%s:%s@%s:%d%s", Config.UserName, Config.Password, Config.Host, Config.Port,
Config.VHost);
Connection conn = null;
try {
factory.setUri(uri);
factory.setVirtualHost(Config.VHost);
conn = factory.newConnection();
} catch (Exception e) {
e.printStackTrace();
} return conn;
}第二部分:应用类,使用最简单的方式发布和消费消息
public static void main(String[] args) {
Publisher(); // 推送消息
Consumer(); // 消费消息
}
/**
* 推送消息
*/
public static void Publisher() {
// 创建一个连接
Connection conn = ConnectionFactoryUtil.GetRabbitConnection(); if (conn != null) {
try {
// 创建通道
Channel channel = conn.createChannel();
// 声明队列【参数说明:参数一:队列名称,参数二:是否持久化;参数三:是否独占模式;参数四:消费者断开连接时是否删除队列;参数五:消息其他参数】
channel.queueDeclare(Config.QueueName, false, false, false, null);
String content = String.format("当前时间:%s", new Date().getTime());
// 发送内容【参数说明:参数一:交换机名称;参数二:队列名称,参数三:消息的其他属性-routing headers,此属性为MessageProperties.PERSISTENT_TEXT_PLAIN用于设置纯文本消息存储到硬盘;参数四:消息主体】
channel.basicPublish("", Config.QueueName, null, content.getBytes("UTF-8"));
System.out.println("已发送消息:" + content);
// 关闭连接
channel.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 消费消息
*/
public static void Consumer() {
// 创建一个连接
Connection conn = ConnectionFactoryUtil.GetRabbitConnection(); if (conn != null) {
try {
// 创建通道
Channel channel = conn.createChannel();
// 声明队列【参数说明:参数一:队列名称,参数二:是否持久化;参数三:是否独占模式;参数四:消费者断开连接时是否删除队列;参数五:消息其他参数】
channel.queueDeclare(Config.QueueName, false, false, false, null);
// 创建订阅器,并接受消息
channel.basicConsume(Config.QueueName, false, "", new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String routingKey = envelope.getRoutingKey(); // 队列名称
String contentType = properties.getContentType(); // 内容类型
String content = new String(body, "utf-8"); // 消息正文
System.out.println("消息正文:" + content);
channel.basicAck(envelope.getDeliveryTag(), false); // 手动确认消息【参数说明:参数一:该消息的index;参数二:是否批量应答,true批量确认小于index的消息】
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
}本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
关于RabbitMQ的工作原理是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。








 京公网安备 11010802041100号
京公网安备 11010802041100号