作者:逍遥微博2011_213 | 来源:互联网 | 2023-07-05 18:20
前提: Solr、SolrCloud提供了一整套的数据检索方案,HBase提供了完善的大数据存储机制。
需求: 1、对于添加到HBase中的结构化数据,能够检索出来。
2、数据量较大,达到10亿,100亿数据量。
3、检索的实时性要求较高,秒级更新。
说明: 以下是使用Solr和HBase共同搭建的系统架构。
1.1一次性创建索引
l、删除全索引
效率很高,可以关闭Solr后,直接删除Data文件。
2、重新创建全索引
拉取HBase中全数据,分批次创建索引。
1.2增量创建索引
1、触发器发送数据到Solr建索引。
配置并使用HBase触发器功能,配置实现如下:
alter 'angelHbase', METHOD => 'table_att', 'coprocessor' => '/home/hbase/hbase-0.94.18-security/lib/solrHbase.jar|solrHbase.test.SorlIndexCoprocessorObserver|1073741823|'
alter 'angelHbase', METHOD =>'table_att_unset', NAME => 'coprocessor$1'
然后编写SorlIndexCoprocessorObserver extendsBaseRegionObserver,重写postPut方法。在postPut方法中,需要正确地读出写入HBase的数据结构及数据,然后转化为相应的SolrInputDocument,再使用ConcurrentUpdateSolrServer方式向Solr服务器发送SolrInputDocument数据,具体使用方法如之前博文介绍Solr的使用方法、性能对比所示。
注意:需要把Solr相关的jar包放入lib下,并且删除版本不一致的jar(有很多)。更新jar后要重启HBase才能生效。
具体性能如之前博文介绍Solr的使用方法、性能对比所示。http://www.cnblogs.com/wgp13x/p/3742653.htmlhttp://www.cnblogs.com/wgp13x/p/3748764.html
2、触发器发送数据到RabbitMQ,Solr端从RabbitMQ获取数据建索引。
embedded方式官方不推荐使用。而使用ConcurrentUpdateSolrServer性能与上种方式并无区别。
3、建议:
在HBase中只存储1列,存储值为PB或Json串。(存在由bean到SolrInputDocument转化的类及annotation,以及各自的压缩算法)
或者:插入HBase的数据均以Bytes.toBytes(String)类型存储,如long型数值2存储为Bytes.toBytes(""+2)。否则在postPut()中需要知道每列的具体类型才能生成正确的SolrInputDocument,因为SolrInputDocument中需要的是String类型的数据。
具体的postPut方法代码,如有需要可以留言或直接跟本人联系。http://www.cnblogs.com/wgp13x/
1.3HBase与Solr系统架构设计
使用HBase搭建结构数据存储云,用来存储海量数据;使用SolrCloud集群用来搭建搜索引擎,将要查找的结构化数据的ID查找出来,只配置它存储ID。
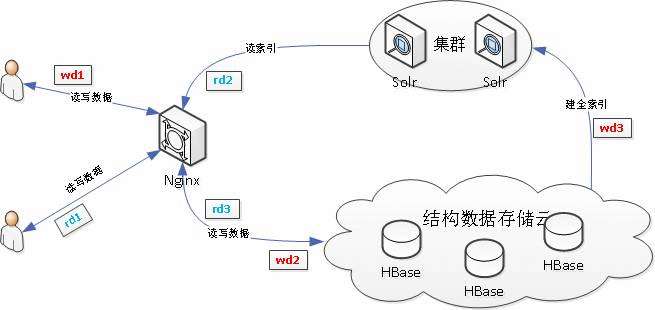
1、具体流程:
wd代表用户write data写数据,从用户提交写数据请求wd1开始,经历wd2,写入MySQL数据库,或写入结构数据存储云中,wd3,提交到Solr集群中,从而依据业务需求创建索引。
rd代表用户read data读数据,从用户提交读数据请求rd1开始,经历rd2,直接读取MySQL中数据,或向Solr集群请求搜索服务,rd3,向Solr集群请求得到的搜索结果为ID,再向结构数据存储云中通过ID取出数据,最后返回给用户结果。





 京公网安备 11010802041100号
京公网安备 11010802041100号