人工智能的参照样本始终没有离开人类本身。而终身式、增量式的学习能力是人类最重要的能力之一。机器人如果能像人类一样对环境以及任务进行增量的学习,这使得机器人终身学习成为可能。增量学习思想的重要性体现在2个方面:
(1)在实际的感知数据中,数据量往往是逐渐增加的,因此,在面临新的数据时,学习方法应能对训练好的系统进行某些改动,以对新数据中蕴涵的知识进行学习;
(2)对一个训练好的系统进行修改的时间代价通常低于重新训练一个系统所需的代价。
增量学习思想可以描述为:每当新增数据时,并不需要重建所有的知识库,而是在原有知识库的基础上,仅对由于新增数据所引起的变化进行更新。我们发现,增量学习方法更加符合人的思维原理。增量学习框架有很多,各框架最核心的内容是处理新数据与已存储知识相似性评价方法。因为该方法决定觉察新知识并增加知识库的方式,它影响着知识的增长。新知识的判定机制才是增量学习的核心部件。下面针对几种常见的增量式学习框架进行简单介绍,有自组织增量学习神经网络SOINN、情景记忆马尔可夫决策过程EM-MDP。
自组织增量学习神经网络SOINN是一种基于竞争学习的两层神经网络。SOINN的增量性使得它能够发现数据流中出现的新模式并进行学习,同时不影响之前学习的结果。因此SOINN能够作为一种通用的学习算法应用于各类非监督学习问题中。
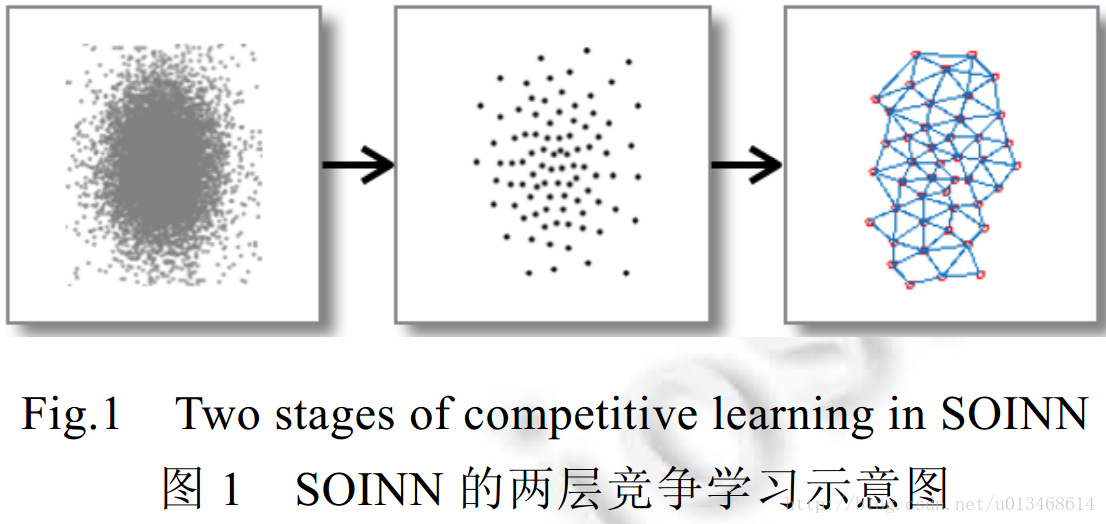
SOINN是两层结构(不包括输入层)的竞争性神经网络,它以自组织的方式对输入数据进行在线聚类和拓扑表示,其工作过程如图1所示。
第1层网络接受原始数据的输入,以在线的方式自适应地生成原型神经元来表示输入数据。这些节点和它们之间的连接反映了原始数据的分布情况;
第2层根据第1层网络的结果估计出原始数据的类间距离与类内距离,并以此作为参数,把第1层生成的神经元作为输入再运行一次SOINN算法,以稳定学习结果。
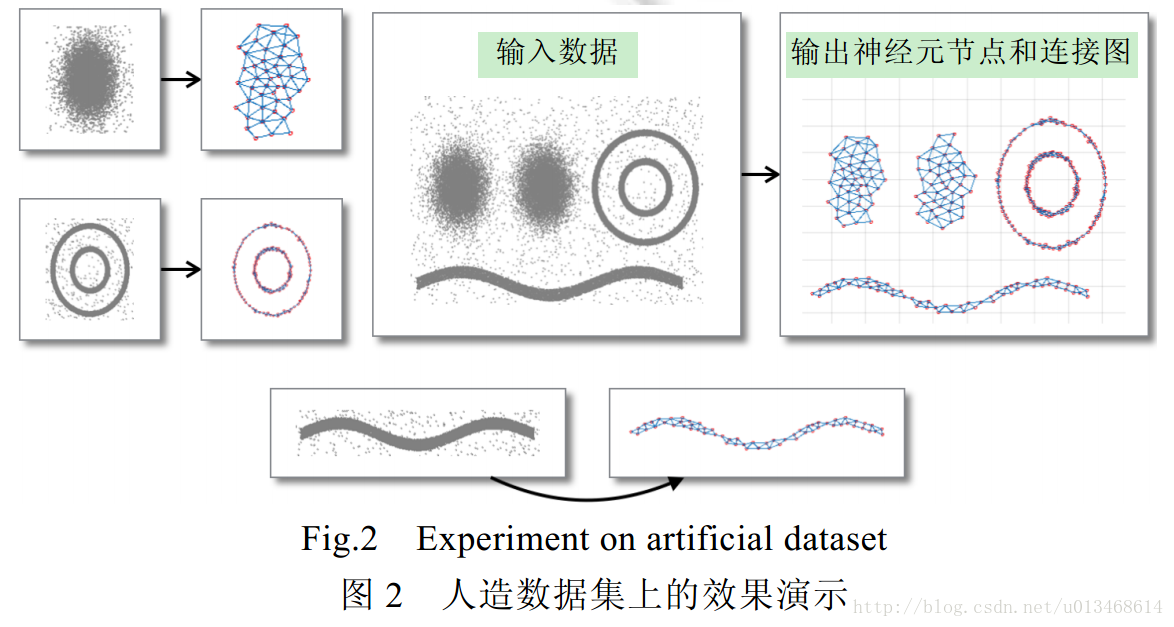
如图2所示:当输入数据存在多个聚类并存在噪声时,SOINN依然能够生成可靠的神经元节点来表示输入数据中的各个聚类;同时子图的拓扑结构反映了原始数据分布的性。
动态调整是SOINN实现自组织和增量学习的关键,它使得神经元的权值向量和网络的拓扑结构能够随着输入模式的到来动态地进行调整,以优化对输入数据的表达精度。此外,通过适时增加神经元不仅能够自适应地确定神经元的数量以满足一定的量化误差约束,同时还能在不影响之前学习结果的情况下适应之前没有学习过的输入模式。SOINN分别定义了类内节点插入和类间节点插入操作来达到这两个目的。
类内的节点插入操作主要是为了自适应地减小神经元的量化误差,尽可能准确地近似原始数据的分布.具体的,SOINN 在运行过程中会记录每个神经元的累积量化误差,每学习一段固定的时间之后,找出所有节点中累积量化误差最大的两个节点,然后在它们的中间插入一个新的节点,以插值的方式更新它们的累计量化误差值.考虑到并非每次插入操作都是有必要的,如果不进行一些限制的话,那么随着算法的进行,节点的数量会不断地增加.因此,SOINN 在每次类内的节点插入操作后都会再判断该次插入操作是否显著降低了量化误差:如果没有,则取消本次插入操作。
类间节点插入发生在新输入的数据与之前学习过的数据差异性较大的时候.SOINN 通过为每一个神经元i设置一个相似度阈值(similarity threshold)参数TiT_iTi来判断新来的数据样本是否有可能属于一个新的类别:如果该数据点与之前学习得到神经元差异性较大,就在该数据点的位置上生成一个新的节点来代表这个可能的模式.如图3 所示,ξ为新输入的数据点,SOINN 首先找到与其最相似的两个神经元s1s_1s1 与s2s_2s2,如果d(s1,ξ)>T(s1)d(s_1,ξ)>T_(s_1 )d(s1,ξ)>T(s1)或者 d(s2,ξ)>T(s2)d(s_2,ξ)>T_(s_2 )d(s2,ξ)>T(s2),就认为数据点ξ的差异性较大.其中,d(∙)d(∙)d(∙)为相似度度量函数(通常为欧氏距离函数).新生成的节点并不意味着最终一定属于一个新的聚类,只是在当前的相似度阈值下,该输入与之前学习到的模式存在较大差异.随着越来越多的输入模式得到学习,相似度阈值和神经元之间的连接也在不断变化。
可以看出:类间节点插入是SOINN 实现增量学习的关键,节点插入的时机对于最终的结果有较大影响,而每个节点的相似度阈值参数TTT 又是决定插入操作的关键.如果TTT值过小,则每个数据都会被认为是一个新的模式而生成一个节点;TTT 值过大,则会导致节点个数过少,此时量化误差增大,而且不能准确反映数据的分布.理想情况下,该参数应大于平均的类内距离同时小于平均的类间距离。SOINN在这个问题上采用了一种自适应的方式不断更新$T_i $ 的值,使得能够适应不断变化的输入模式。假设NNN为所有节点的集合,NiN_iNi为节点i的邻居节点集合。如果NiN_iNi不为空,即,存在其他节点通过一条边与其相连,就令:
Ti=maxj∈Ni∣∣Wi−Wj∣∣T_i=max_{j \in N_i}||W_i-W_j||Ti=maxj∈Ni∣∣Wi−Wj∣∣
否则,Ti=minj∈N∖i∣∣Wi−Wj∣∣T_i=min_{j \in N \setminus {i}}||W_i-W_j||Ti=minj∈N∖i∣∣Wi−Wj∣∣。可以看出,这两个定义实际上是当前对最大类内距离和最小类间距离的估计值。实际应用表明,这样的动态调整方法是行之有效的。
情景记忆马尔可夫决策过程EM-MDP准确来说是一套完整的人工智能方案(简化版),这个框架中包括对情景的认知、增量学习、短期与长期记忆模型。我们将焦点放在框架中的增量学习部分。该框架基于自适应共振理论(ART)与稀疏分布记忆(SDM)的思想实现对情景记忆序列的增量式学习。SDM是计算机科学家彭蒂.卡内尔瓦于1974年提出的能够将思维所拥有的任何感知存入有限记忆机制的方法。这样,在学习过程中,每次可有多个状态神经元同时被告激活,每个神经元均可看成一类相近感知的代表。相比SOINN网络每次最多只能有一个输出节点,该方法具有环境适应性好的优点。
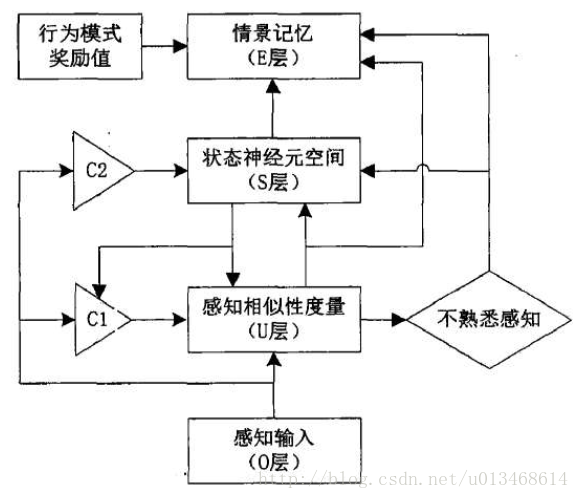
情景记忆网络学习模型的构建基于EM-MDP模型框架,由感知输入(O层)、感知相似性度量(U层)、状态神经元(S层)和输出情景记忆(E层)组成,其结构模型如图3所示。框架中U层与S层都具有增量式学习的能力,U层与S层的结构如图4所示。U层节点个数等于输入感知的维数,每个节点的输出由3个信号共同确定:(1)当前环境的感知输入oco_coc;(2)控制信号C1C1C1;(3)由S层反馈的获胜状态神经元的映射感知。
图3
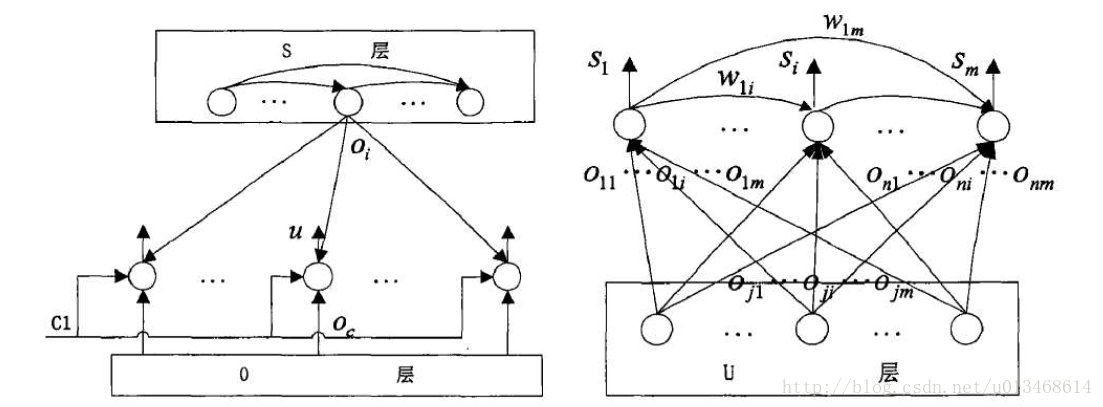
U层节点的输出u根层这3个信号采用“多数表决2/3”原则计算获得。当C1=1C1=1C1=1,反馈映射感知信号为0时,U层节点输出由输入感知决定,即u=ocu=o_cu=oc。当反馈映射感知信号不为0,C1=0C1=0C1=0时,U层节点输出取决于输入感知与反馈映射感知的比较情况,如果相似性度量大于阈值,则对感知向量学习进行调整,否则增加新的感知om+1=oco_{m+1}=o_com+1=oc。S层有m个节点,用以表示m个状态神经元,该状态神经元空间可通过增加新的神经元节点进行动态增长。状态神经元间具有权值,代表情景记忆的连接关系。
图4
情景网络接受来自环境的感知输入,通过检查当前感知输入与所有存储感知向量之间的匹配程度,确定新感知及其相关事件是否已存在机器人的情景记忆当中。按照预先设定的激活阈值来考察相似性度量,决定对新输入的感知采取何种处理方式。在网络每一次接受新的感知输入时,都需要经过一次匹配过程。相似性度量存在两种情况:
相似度超过设定阈值,则选择该邻近状态集为当前输入感知的代表状态神经元集合。感知通过学习进行调整以使其之后遇到与当前输入感知接近的感知时能获得更大的相似度,对非该邻近状态集,感知向量不做任何调整。实际上是对情景记忆中的映射感知进行重新编码,以稳定已经被学习了的熟悉事件。
相似度不超过设定阈值,需要在S层新增一个代表新输入感知的状态神经元并存储当前感知为该新增状态的映射感知,以便参加之后的匹配过程。同时建立与该状态神经元相连的权值,以存储该类感知和参与以后的匹配过程。实际上是对不熟悉事件建立新的表达编码。
通过查阅相关文献,SOINN被应用的相对较多。有用来对环境进行增量式构建路图,也有以处理过的视觉信息作为特征输入进行认知地图构建的。而EM-MDP结还未对其中增量式学习部分进行有效的框架分离,所以结构相对作为单独框架提出来的SOINN不是很清晰。增量式学习的核心部件是对新旧知识的处理上,而将一个输判定是否为新知识,则需要度量新输入与旧知识之间的“距离”。对知识网络中的噪声进行过滤处理也是维护一个有效知识网络的必不可少的部分。**最后值得注意的是,SOINN的评判阈值是自动动态调整的,而EM-MDP中的阈值是预先设定的一个定值。**当然,有效地自动调整参数是大家都喜闻乐见的。
END












 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有