更多大数据架构、实战经验,欢迎关注【大数据与机器学习】,期待与你一起成长!
Flink SQL 中TableFunction使用分析
本篇幅介绍Flink Table/SQL中如何自定义一个表函数(TableFunction),介绍其基本用法以及与源码结合分析其调用流程。
基本使用
表函数TableFunction相对标量函数ScalarFunction一对一,它是一个一对多的情况,通常使用TableFunction来完成列转行的一个操作。先通过一个实际案例了解其用法:终端设备上报数据,数据类型包含温度、耗电量等,上报方式是以多条方式上报,例如:
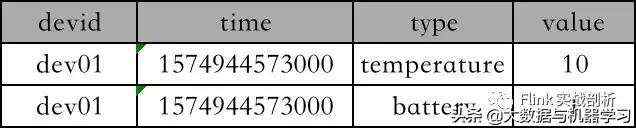
现在希望得到如下数据格式:
这是一个典型的列转行或者一行转多行的场景,需要将data列进行拆分成为多行多列,先看下代码实现:
public class MyUDTF extends TableFunction{
public void eval(String s){
JSONArray jsonArray =JSONArray.parseArray(s);
for(int i =0; i JSONObject jsonObject = jsonArray.getJSONObject(i);
String type = jsonObject.getString("type");
String value = jsonObject.getString("value");
collector.collect(Row.of(type, value));
}
}
@Overridepublic TypeInformation getResultType(){
returnTypes.ROW(Types.STRING(),Types.STRING());
}
}
在MyUDTF中继承了TableFunction, 所有的自定义表函数都必须继承该抽象类,其中T表示返回的数据类型,通常如果是原子类型则直接指定例如String, 如果是复合类型通常会选择Row, FlinkSQL 通过类型提取可以自动识别返回的类型,如果识别不了需要重载其getResultType方法,指定其返回的TypeInformation,重点看下eval 方法定义:
· eval 方法, 处理数据的方法,必须声明为public/not static,并且该方法可以重载,会自动根据不同的输入参数选择对应的eval, 在eval方法里面可以使用collector对象将数据发送出去,该对象是从TableFunction继承过来的。
调用如下:
def main(args:Array[String]):Unit={
val env =StreamExecutionEnvironment.getExecutionEnvironment
val tabEnv =TableEnvironment.getTableEnvironment(env)
tabEnv.registerFunction("udtf








 京公网安备 11010802041100号
京公网安备 11010802041100号