Azure Database for PostgreSQL 托管服务中的超大规模 (Citus) 选项使您能够做的一大新事情是,除了能够横向扩展 Postgres 之外,您现在可以在单个超大规模 (Citus) 上对 Postgres 进行分片。 ) 节点。借助预览版中称为“基本层”的新超大规模 (Citus) 功能,您可以从小处着手,经济高效地开始,同时随时准备横向扩展。
借助超大规模 (Citus) 中的新基本层功能(预览版),您现在可以:
使用基本层,您可以使用标准超大规模 (Citus) 服务器组中所期望的所有功能。换句话说,基本层不受任何限制:使用基本层,您不必牺牲任何超大规模 (Citus) 功能。
您可以在我最近发布的关于在单个 Citus 节点上分片 Postgres 的开源博客文章中阅读支持这个新的基本层功能的 Citus 功能的所有信息,我们首先在新的和壮观的 Citus 10 开源版本中推出了该功能。
在这篇文章中,我们将介绍如何在 Azure 门户中的超大规模 (Citus) 上预配基本层。然后,如何通过在门户中添加更多节点将超大规模 (Citus) 节点从基本层扩展到标准层。
你问的标准层是什么?标准层是多节点超大规模 (Citus) 集群的新名称,用于将多节点集群与仅具有单个超大规模 (Citus) 节点的基本层区分开来。
同样在这篇文章中,我们将向您展示使用新的基本层在单个超大规模 (Citus) 节点上对 Postgres 进行分片的一些有用方法。特别是,我喜欢高性价比的角度,因为每小时 0.27 美元,您可以试用 Hyperscale (Citus) 约 8 小时,而您只需支付 2-3 美元。

要开始在 Azure Database for PostgreSQL 托管服务中的超大规模 (Citus) 中使用基本层,一如既往,一个不错的起点是 docs.microsoft.com:
您需要配置的所有说明都在快速入门文档(上面的链接)中,用于在超大规模 (Citus) 中配置基本层。 尽管如此,我还是想通过来自 Azure 门户的屏幕截图来强调此可视化指南中的一些步骤。 从…开始:
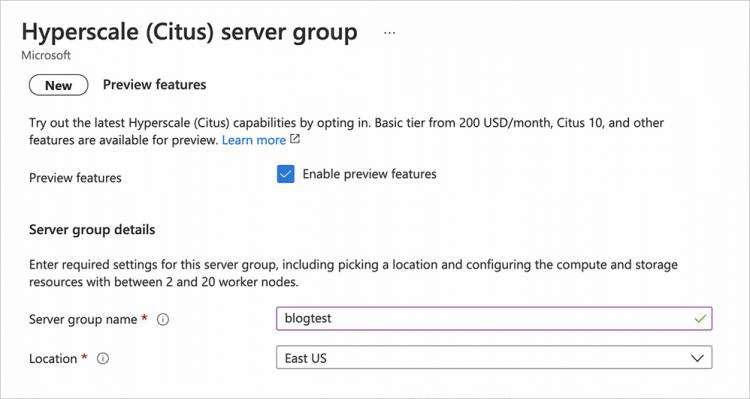
图 1:截至本博文发布之日,基本层是一项预览功能,因此请务必单击启用预览功能。
启用预览功能并进入 Azure 门户的预配工作流中的计算 + 存储屏幕后,请记住选择基本层:
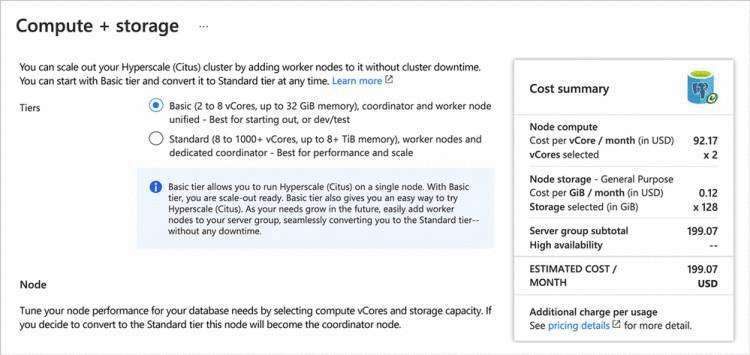
图 2:选择基本层来配置单个超大规模 (Citus) 节点,从小处着手并做好横向扩展准备。稍后在帖子中,我们还将扩展到标准层。
当您按照基本层快速入门文档配置超大规模 (Citus) 时,请务必特别注意:
配置可能需要几分钟时间。为您的超大规模 (Citus) 服务器组配置基本层后,您将看到“您的部署已完成屏幕”。您可以单击蓝色的“转到资源”按钮转到刚刚在 Azure 门户中创建的基本层实例。现在您已准备好按照以下步骤连接到数据库。
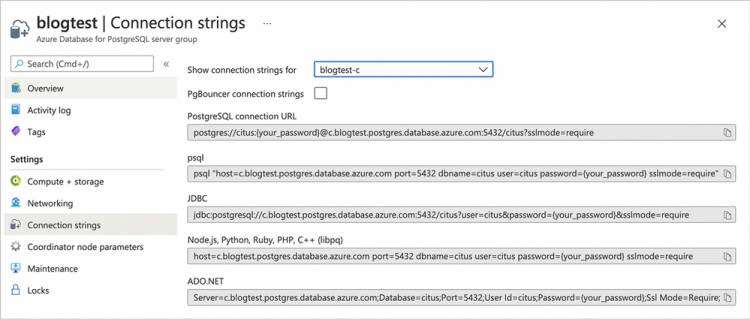
图 3:找到我们将用于连接到超大规模 (Citus) 服务器组的“连接字符串”。
在这篇文章中,我将使用 psql(PostgreSQL 的交互式终端前端)连接到超大规模(Citus)数据库并通过创建分布式表开始对 Postgres 进行分片。 (Azure 提示:您也可以将 psql 用作 Azure Cloud Shell 的一部分!)
-- Create a table with the usual PostgreSQL syntax
CREATE TABLE users_table (user_id bigserial primary key, age int);
-- Convert the table to a distributed table
SELECT create_distributed_table('users_table', 'user_id');
Hyperscale (Citus) create_distributed_table 函数将 Postgres 表划分为 32 个分片,但您仍然可以像所有数据都在一个表中一样查询 Postgres。因为分片是常规的 Postgres 表,所以您仍然可以依赖 Postgres 关系数据库的丰富功能,例如事务、索引、数据库约束、JOIN 等等。
正如您在上面看到的,只需单击几下,我们就能够使用基本层配置超大规模 (Citus) 数据库,然后在单个超大规模 (Citus) 节点上创建分布式表。
接下来,让我们探讨一下为什么你还是要使用这个新奇的基本层的东西?在单个节点上对 Postgres 进行分片对您有何帮助?
分片 Postgres 长期以来一直与大规模数据相关联。事实上,当大多数人想到 Citus 如何对 Postgres 进行分片时,您可能会想象一个具有 2 或 4 个工作节点,或者可能有 20 个或 50 个甚至 100 个工作节点的超大规模 (Citus) 集群。但是随着超大规模(Citus)上基本层的引入,我们都可以以不同的方式考虑分片。
即使数据量不大,在单个超大规模 (Citus) 节点上对 Postgres 进行分片也可以带来立竿见影的好处。通过使用分布式数据模型,您可以获得:
例如,在使用 create_distributed_table 函数对上面的 users_table 进行分片后,以下 SQL 命令现在将在 Hyperscale (Citus) 分片上并行运行,这可以显着减少执行次数:
-- load data, ingestion happens in parallel across shards
INSERT INTO users_table (age)
SELECT 20 + (random() * 70)::int
FROM generate_series(0, 100000);
-- this query runs in parallel across all shards
SELECT avg(age) FROM users_table;
-- index created in parallel across all shards
CREATE INDEX user_age ON users_table (age);
当您的数据不再适合内存时(或者如果数据库服务器受 CPU 限制),那么使用超大规模 (Citus) 中的基本层,您的数据将已经被分片,您将能够轻松地将更多节点添加到集群中以保持 您的数据库性能。
换句话说,使用超大规模 (Citus) 中的基本层,您已经准备好进行横向扩展,或者我喜欢称之为“可横向扩展”。
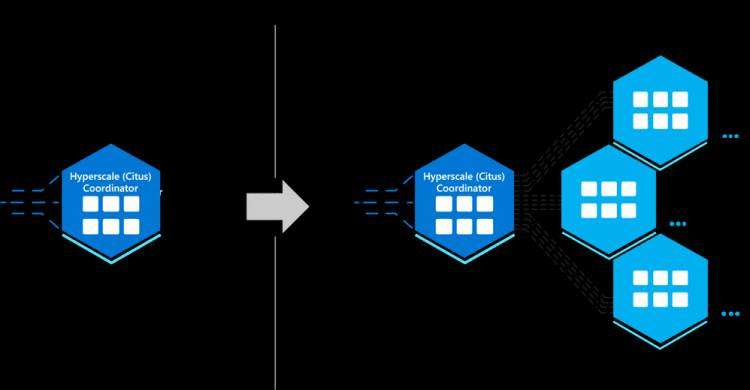
图 4:在具有超大规模 (Citus) 基本层的单个节点上对 Postgres 进行分片——从而从一开始就采用分布式数据模型——可以让您轻松地将 Postgres 数据库随时扩展到任何规模。我喜欢将其称为 Azure Database for PostgreSQL 中的超大规模 (Citus) 的“横向扩展就绪”。
当您准备好进行扩展时,可以轻松地将工作节点添加到您的超大规模 (Citus) 基础层。毕竟,您的数据模型已经是分布式的。而且您无需迁移、升级或经历任何麻烦。您只需在门户中添加更多工作节点并从基本层升级到标准层,我们将在下面一起做。
当您将工作节点添加到超大规模 (Citus) 集群时,它们上还没有数据。这是因为所有分片仍在旧节点上——在这种情况下,使用基本层,所有数据都在单个超大规模 (Citus) 节点上。因此,最初所有这些新的工作节点将什么都不做。
这就是超大规模 (Citus) 分片重新平衡功能发挥作用的地方。分片重新平衡可确保分片在集群中的所有节点上公平分布。 Citus 分片再平衡器通过将分片从一个节点移动到另一个节点来实现这一点。
在移动分片时,所有读取和写入查询都可以继续。换句话说,超大规模 (Citus) 实现了数据的在线再平衡——或者一些人称之为零停机时间的再平衡。
下面,我们将向超大规模 (Citus) 数据库集群添加新节点,并在整个集群中重新平衡分片。我们将只添加 2 个工作节点,但您可以将超大规模 (Citus) 服务器组扩展到您认为需要的任意数量的节点。

图 5:在 Azure 门户的计算 + 存储屏幕上的超大规模 (Citus) 中从基本层切换到标准层。
添加新的超大规模 (Citus) 工作节点并将基本层升级到标准层后,您就可以进行一些分片重新平衡了。
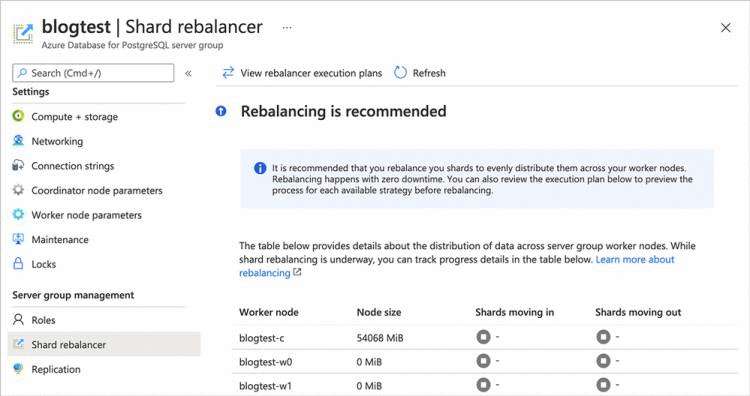
图 6:建议重新平衡时 Azure 门户的 Shard 重新平衡器屏幕截图。 在这种情况下,您可以看到 2 个新添加的工作节点(blogtest-w0 和 blogtest-w1)每个都有 0 MiB 的数据——它们是空的!
您可以使用之前使用的相同连接字符串通过 psql 连接回协调器。
正如我之前提到的,在重新平衡操作期间,所有读写查询都可以在超大规模(Citus)数据库上继续进行。 换句话说,您的生产工作负载不受分片重新平衡的影响。
-- move shards to new worker node(s)
SELECT rebalance_table_shards();
NOTICE: Moving shard 102008 from c.blogtest.postgres.database.azure.com:5432 to w1.blogtest.postgres.database.azure.com:5432 ...
NOTICE: Moving shard 102009 from c.blogtest.postgres.database.azure.com:5432 to w0.blogtest.postgres.database.azure.com:5432 ...
....
NOTICE: Moving shard 102028 from c.blogtest.postgres.database.azure.com:5432 to w1.blogtest.postgres.database.azure.com:5432 ...
在 Hyperscale (Citus) 中的分片重新平衡操作期间,您可以监控其进度。 为此,请按照以下步骤操作:
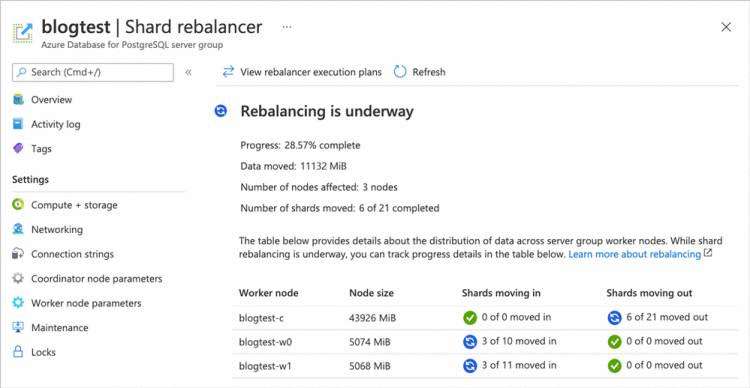
图 7:在重新平衡过程中,关注 Azure 门户的 Shard Rebalancer 屏幕上的重新平衡进度。
现在分片已分布在超大规模 (Citus) 集群中,您的应用程序可以使用工作节点和协调节点上的资源。但是,除了增加了应用程序可用的计算、内存和磁盘——从应用程序的角度来看,没有任何改变。
在向超大规模 (Citus) 数据库集群添加 2 个工作程序节点并在整个集群中重新平衡分片之后,您的应用程序仍在与同一个 Postgres 数据库通信。恭喜,您已经使用 Hyperscale (Citus) 无缝扩展了 Postgres 数据库!
你可能想知道:
“如果我现在不需要横向扩展 Postgres,为什么要使用 Hyperscale (Citus)?”
好吧,如果您认为您的数据库在未来不会增长(并且您的数据库将保持小于 ~100GB),那么我们的 Azure Database for PostgreSQL 托管服务中的其他部署选项之一 - 例如单服务器或灵活的服务器——很可能很好地处理您的工作负载。但是,如果您希望您的应用程序(以及因此您的 Postgres 数据库)随着时间的推移而增长,那么答案就会与您相关。
如果您从 Hyperscale (Citus) 的小规模开始——通过在单个 Hyperscale (Citus) 节点基本层上对 Postgres 进行分片——那么随着应用程序的增长(就用户或活动或功能或数据库大小而言),您将能够轻松地添加节点并在 Hyperscale (Citus) 上使用零停机时间分片重新平衡器。向您的超大规模 (Citus) 服务器组添加更多节点将使您能够将更多数据放入内存中,拥有更高的 I/O 带宽,并为您的 Postgres 数据库提供更多的计算能力 (CPU)。换句话说,即使在应用程序增长时,您也将拥有所有方法来保持应用程序的数据库性能。
您需要考虑一些事项,以使超大规模 (Citus) 可以使用新的基本层进行横向扩展。在横向扩展架构中,数据基于分片键(我们在 Citus 中称为分布列)进行分布。您选择的分片键不仅会影响数据的分布方式,还会影响您将获得什么样的查询性能得到。因此,对您的查询模式和数据模型进行一些前期思考可能会有很长的路要走。例如,对不包含分布键的 Postgres 列强制执行 UNIQUE 约束通常是不高效的(甚至是不可能的)。
如果在 Azure Database for PostgreSQL 中使用超大规模 (Citus) 中的基本层时遵循分布式数据库的数据建模最佳做法,则可以轻松横向扩展数据库。无缝扩展 Postgres 数据库的 Citus 最佳实践包括:
如果您按照上述最佳实践构建数据库,超大规模 (Citus) 的承诺是您将能够将 Postgres 数据库扩展到一些相当大的数据库集群大小。这里的关键点是,一旦您习惯了横向扩展系统的思维方式,您就会意识到遵循数据建模最佳实践是多么容易。
图 8:使用新的超大规模 (Citus)“基本层”功能(预览版)从小处着手,经济高效,然后如果需要,您可以通过添加更多超大规模(Citus)轻松升级到“标准层” ) 节点。
在超大规模 (Citus) 中使用基本层的另一个有趣场景是在您的开发和测试环境中。正如我之前提到的,与标准层相比,基本层没有任何限制。因此,对于许多用户而言,基本层可能是一种实用且经济高效的配置开发和测试数据库的方式。
正如我之前在博客中提到的,基本层目前处于预览状态。事实上,预览中有几个超级有用的超大规模(Citus)功能,包括:
我们很高兴为您带来 Azure Database for PostgreSQL 上超大规模 (Citus) 中新的基本层功能(预览版!)的预览。
虽然“打开通往新可能性的大门”可能听起来很崇高,但这是真的。超大规模 (Citus) 中的基本层为您提供了一种在云中的第 0 天“准备好向外扩展”的方法。如果您的应用程序已经在单节点 Postgres 上运行,那么您现在可以采用分片数据模型,该模型允许您在未来尽可能多地扩展 Postgres 数据库。从本质上讲,随着您的应用程序增长并且您需要向外扩展,您将不会面临任何类型的数据库迁移挑战。
当您准备好试用 Citus 时,一些有用的链接和资源:
如果您对我们的 Azure Database for PostgreSQL 托管服务中的超大规模 (Citus) 选项有任何疑问,我的产品团队成员很乐意听取您的意见。您可以随时通过 AskAzureDBforPostgreSQL 的电子邮件与我们联系。或在 Twitter @AzureDBPostgres 上关注我们。我们很想知道您的想法。
脚注
原文标题:Sharding Postgres with Basic tier in Hyperscale (Citus), how why & when
原文作者:Onder Kalaci
原文地址:https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/sharding-postgres-with-basic-tier-in-hyperscale-citus-how-why/ba-p/2275672











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有