作者:渐我素小黑陈琼敏 | 来源:互联网 | 2023-08-19 18:28
**简介:**ApacheSentry是Hadoop的基于角色的精细授权模块。Sentry为Hadoop集群上的经过身份验证的用户和应用程序提供了控制和实施数据特权级别的功能
**
简介:
**
Apache Sentry是Hadoop的基于角色的精细授权模块。Sentry为Hadoop集群上的经过身份验证的用户和应用程序提供了控制和实施数据特权级别的功能。Sentry当前可以与Apache Hive,Hive Metastore / HCatalog,Apache Solr,Impala和HDFS(仅限于Hive表数据)配合使用。 Sentry被设计为Hadoop组件的可插入授权引擎。它允许您定义授权规则,以验证用户或应用程序对Hadoop资源的访问请求。Sentry是高度模块化的,可以支持对Hadoop中各种数据模型的授权。
架构概述
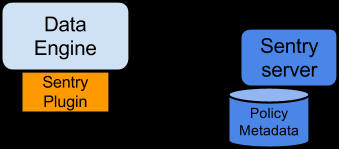
授权过程涉及以下组件:
Sentry服务器:Sentry RPC服务器管理授权元数据。它支持安全地检索和操作元数据的界面;
数据引擎:这是一个数据处理应用程序,例如Hive或Impala,需要授权访问数据或元数据资源。数据引擎加载Sentry插件,所有客户端访问资源的请求均被拦截并路由到Sentry插件进行验证;
Sentry插件:Sentry插件在数据引擎中运行。它提供了操作存储在Sentry服务器中的授权元数据的接口,并包括授权策略引擎,该引擎使用从服务器获取的授权元数据评估访问请求。
关键概念:
身份验证 -验证凭据以可靠地标识用户
授权 -限制用户对给定资源的访问
用户 -由基础身份验证系统标识的个人
组 -由验证系统维护的一组用户
特权 -允许访问对象的指令或规则
角色 -一组特权;组合多个访问规则的模板
授权 模型 -定义要遵循授权规则和允许的操作粒度的对象。例如,在SQL模型中,对象可以是数据库或表,而操作可以是 选择,插入,创建 等等。对于搜索模型,对象是索引,集合和文档。访问方式为查询,更新等。
**
Sentry与Hadoop生态系统的集成
**
 如上所述,Apache Sentry与多个Hadoop组件一起使用。在中心,您可以使用Sentry Server,该服务器存储授权元数据并提供用于工具的API,以安全地检索和修改此元数据。
如上所述,Apache Sentry与多个Hadoop组件一起使用。在中心,您可以使用Sentry Server,该服务器存储授权元数据并提供用于工具的API,以安全地检索和修改此元数据。
请注意,Sentry服务器仅辅助使用元数据。实际的授权决策由运行在数据处理应用程序(例如Hive或Impala)中的策略引擎做出。每个组件都加载Sentry插件,该插件包括用于处理Sentry服务的服务客户端和用于验证授权请求的策略引擎。
Sentry与hive集成 ## Sentry与Impala集成
## Sentry与Impala集成
 Impala中的授权处理与Hive中的授权处理相似。主要区别在于特权的缓存。Impala的目录服务器管理缓存架构元数据,并将其传播到所有Impala服务器节点。此目录服务器也缓存Sentry元数据。结果,Impala中的授权验证在本地进行并且速度更快。
Impala中的授权处理与Hive中的授权处理相似。主要区别在于特权的缓存。Impala的目录服务器管理缓存架构元数据,并将其传播到所有Impala服务器节点。此目录服务器也缓存Sentry元数据。结果,Impala中的授权验证在本地进行并且速度更快。
Sentry-HDFS同步
Sentry-HDFS授权专注于Hive仓库数据-即,Hive或Impala中表的一部分的任何数据。集成的真正目的是将相同的授权检查扩展到从其他任何组件(例如Pig,MapReduce或Spark)访问的Hive仓库数据。在这一点上,此功能不能代替HDFS ACL。与Sentry无关的表将保留其旧的ACL。
 Sentry特权到HDFS ACL权限的映射如下:
Sentry特权到HDFS ACL权限的映射如下:
SELECT特权->对文件的读取访问权限。
INSERT特权->对文件的写访问权。
ALL特权->对文件的读写访问权限。
NameNode加载一个Sentry插件,该插件缓存Sentry特权以及Hive元数据。这有助于HDFS保持文件权限和Hive表权限同步。Sentry插件会定期轮询Sentry和Metastore,以使元数据更改保持同步。









 京公网安备 11010802041100号
京公网安备 11010802041100号