redis是目前最流行的 NoSQL 内存数据库,然而如果在使用过程中出现滥用、乱用的情况,很容易发生性能问题,此时我们就要去关注慢查询日志,本文尝试给大家介绍一种通过 elastic stack 来快速分析 redis 慢查询日志的方法,希望能给大家提供帮助。
redis slowlog简介
redis是目前最流行的缓存系统,因其丰富的数据结构和良好的性能表现,被各大公司广泛使用。尽管redis性能极佳,但若不注意使用方法,极容易出现慢查询,慢查询多了或者一个20s的慢查询会导致操作队列(redis是单进程)堵塞,最终引起雪崩甚至整个服务不可用。对于慢查询语句,redis提供了相关的配置和命令。
配置有两个:slowlog-log-slower-than 和 slowlog-max-len。slowlog-log-slower-than是指当命令执行时间(不包括排队时间)超过该时间时会被记录下来,单位为微秒,比如通过下面的命令,就可以记录执行时长超过20ms的命令了。
config set slowlog-log-slower-than 20000
slowlog-max-len是指redis可以记录的慢查询命令的总数,比如通过下面的命令,就可以记录最近100条慢查询命令了。
config set slowlog-max-len 100
操作慢查询的命令有两个:slowlog get [len] 和 slowlog reset。slowlog get [len]命令获取指定长度的慢查询列表。
redis 127.0.0.1:6379> slowlog get 2
1) 1) (integer) 142) (integer) 13094482213) (integer) 154) 1) "ping"
2) 1) (integer) 132) (integer) 13094481283) (integer) 304) 1) "slowlog"2) "get"3) "100"
上面返回了两个慢查询命令,其中每行的含义如下:
- 第一行是一个慢查询id。该id是自增的,只有在 redis server 重启时该id才会重置。
- 第二行是慢查询命令执行的时间戳
- 第三行是慢查询命令执行耗时,单位为微秒
- 第四行是慢查询命令的具体内容。
slowlog reset命令是清空慢日志队列。
elastic stack
elastic stack是elastic公司的一系列软件产品,包括elasticsearch、kibana、logstash、beats等,感兴趣的可以去官网看各个产品的详细介绍,此次不再做详细的讲解。本次分析过程中,我们会用到elasticsearch、kibana和beats三款产品。elasticsearch用来存储解析后的redis slowlog,kibana用于图形化分析,beats用于收集redis slowlog。
这里着重讲一下beats,它是一系列轻量级的数据收集产品统称,目前官方提供了filebeat、packetbeat、heartbeat、metricbeat等,可以用来收集日志文件、网络包、心跳包、各类指标数据等。像我们这次要收集的redis slowlog,官方还没有提供相关工具,需要我们自己实现,但借助beats的一系列脚手架工具,我们可以方便快速的创建自己的rsbeat---redis slowlog beat。
rsbeat原理简介
接下来我们先讲解一下rsbeat的实现原理,一图胜千言,我们先来看下它的工作流。
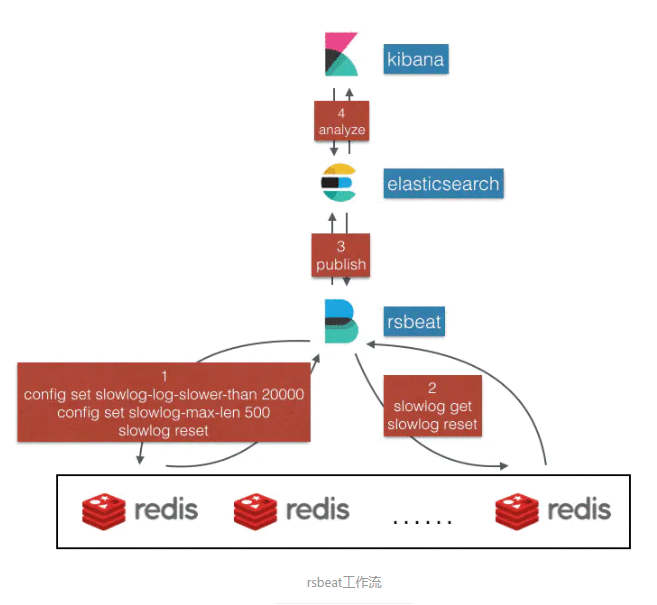
我们由下往上分析:
- 最下面是我们要分析的redis server列表
- 再往上便是
rsbeat,它会与这些redis server建立连接并定期去拉取 slowlog。 - 在启动时,
rsbeat会发送下面的命令到每一台redis server,来完成slowlog的配置,这里设置记录最近执行时长超过20ms的500条命令。
config set slowlog-log-slower-than 20000
config set slowlog-max-len 500
slowlog reset
然后rsbeat会定时去拉取每台redis server的慢查询命令
slowlog get 500
slowlog reset
注意之类slowlog reset是因为此次已经将所有的慢日志都取出了,下次获取时取最新生成的,防止重复计算。
rsbeat将解析的慢日志发布到elasticsearch中进行存储- 通过
kibana进行slowlog的图形化分析
rsbeat的整个工作流到这里已经介绍完毕了,是不是很简单呢?下面我们来简单看一下rsbeat的核心代码实现。
rsbeat核心代码讲解
rsbeat已经在github上开源了,感兴趣的同学可以自己去下下来使用。下面我们分析的代码位于beater/rsbeat.go,这也是rsbeat的核心文件。
func poolInit(server string, slowerThan int) *redis.Pool {return &redis.Pool{MaxIdle: 3,MaxActive: 3,IdleTimeout: 240 * time.Second,Dial: func() (redis.Conn, error) {c, err := redis.Dial("tcp", server, redis.DialConnectTimeout(3*time.Second), redis.DialReadTimeout(3*time.Second))if err != nil {logp.Err("redis: error occurs when connect %v", err.Error())return nil, err}c.Send("MULTI")c.Send("CONFIG", "SET", "slowlog-log-slower-than", slowerThan)c.Send("CONFIG", "SET", "slowlog-max-len", 500)c.Send("SLOWLOG", "RESET")r, err := c.Do("EXEC")if err != nil {logp.Err("redis: error occurs when send config set %v", err.Error())return nil, err}logp.Info("redis: config set %v", r)return c, err},TestOnBorrow: func(c redis.Conn, t time.Time) error {_, err := c.Do("PING")logp.Info("redis: PING")return err},}
}
poolInit方法是rsbeat初始化时进行的操作,这里也就是发送slowlog配置的地方,代码很简单,就不展开解释了。
func (bt *Rsbeat) redisc(beatname string, init bool, c redis.Conn, ipPort string) {defer c.Close()logp.Info("conn:%v", c)c.Send("SLOWLOG", "GET")c.Send("SLOWLOG", "RESET")logp.Info("redis: slowlog get. slowlog reset")c.Flush()reply, err := redis.Values(c.Receive()) // reply from GETc.Receive() // reply from RESETlogp.Info("reply len: %d", len(reply))for _, i := range reply {rp, _ := redis.Values(i, err)var itemLog itemLogvar args []stringredis.Scan(rp, &itemLog.slowId, &itemLog.timestamp, &itemLog.duration, &args)argsLen := len(args)if argsLen >= 1 {itemLog.cmd = args[0]}if argsLen >= 2 {itemLog.key = args[1]}if argsLen >= 3 {itemLog.args = args[2:]}logp.Info("timestamp is: %d", itemLog.timestamp)t := time.Unix(itemLog.timestamp, 0).UTC()event := common.MapStr{"type": beatname,"@timestamp": common.Time(time.Now()),"@log_timestamp": common.Time(t),"slow_id": itemLog.slowId,"cmd": itemLog.cmd,"key": itemLog.key,"args": itemLog.args,"duration": itemLog.duration,"ip_port": ipPort,}bt.client.PublishEvent(event)}
}
redisc方法实现了定时从redis server拉取最新的slowlog列表,并将它们转化为elasticsearch中可以存储的数据后,发布到elasticsearch中。这里重点说下每一个字段的含义:
- @timestamp是指当前时间戳。
- @log_timestamp是指慢日志命令执行的时间戳。
- slow_id是该慢日志的id。
- cmd是指执行的 redis 命令,比如
sadd、scard等等。 - key是指redis key的名称
- args是指 redis 命令的其他参数,通过
cmd、key、args我们可以完整还原执行的redis命令。 - duration是指redis命令执行的具体时长,单位是微秒。
- ip_port是指发生命令的 redis server 地址。
有了这些字段,我们就可以用kibana来愉快的进行可视化数据分析了。
Kibana图形化分析slowlog
Kibana提供了非常方便的数据分析操作,这里不展开解释了,感兴趣的可以自行去学习,这里直接上图,看下最终的分析结果。


 查看慢日志按照时间的分布情况
查看慢日志按照时间的分布情况
上图可以看到最近有一个很明显的数量减少,原因是我们解决了相关的慢查询。
 按慢查询数目来查看cmd分布和key分布
按慢查询数目来查看cmd分布和key分布
 按慢查询时长来查看cmd分布和key分布
按慢查询时长来查看cmd分布和key分布
 表格呈现慢查询的具体命令
表格呈现慢查询的具体命令
看完上面的截图,有没有心动,想亲自操刀试一下?Kibana操作起来非常简单,尤其对于程序员来讲,使用起来得心应手。赶紧下载rsbeat下来自己试一下吧!
总结
随着 elastic stack 的发展,其使用门槛越来越低,我认为目前所有的有志于做数据分析的工程师都应该了解和掌握它的用法。有了它的帮助,你可以以极快的速度搭建起自己的一套免费强大的数据分析软件,它的优点包括但不限于下面提到的:
- 数据源任意且自定制。只要你能将数据读取出来并存储到
elasticsearch中即可分析。 - 支持海量数据分析。得益于
elastic多年的迅猛发展,其产品已经非常成熟,上TB的数据都可以轻松应对存储与分析。有了它,你就可以舍弃数据一多就卡顿的excel了。 - 强大的开源社区支持。
elastic产品的迅猛发展离不开开源社区的支持,你只要在社区中提出自己的问题或者需求,总会有人即时给你答复和建议。如果你有一定的开发能力,那么完全可以按照自己的想法来折腾。
作者:rockybean
链接:https://www.jianshu.com/p/f0878aaacf77
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。








 京公网安备 11010802041100号
京公网安备 11010802041100号