前一篇文章 用 CNTK 搞深度学习 (一) 入门 介绍了用CNTK构建简单前向神经网络的例子。现在假设读者已经懂得了使用CNTK的基本方法。现在我们做一个稍微复杂一点,也是自然语言挖掘中很火的一个模型: 用递归神经网络构建一个语言模型。
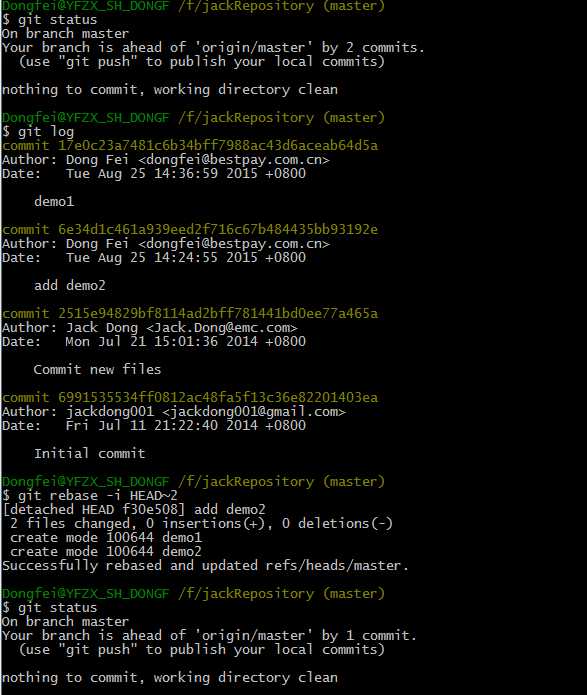
递归神经网络 (RNN),用图形化的表示则是隐层连接到自己的神经网络(当然只是RNN中的一种):

不同于普通的神经网络,RNN假设样例之间并不是独立的。例如要预测“上”这个字的下一个字是什么,那么在“上”之前出现过的字就很重要,如果之前出现过“工作”,那么很可能是在说“上班”; 如果之前出前过“家乡”,那么很可能就是“上海”。 RNN就可以很好的学习出时序的特征。简单的说,RNN把前一时刻的隐层的值也作为一类feature,作为下一时刻输入的一部分。
我们这里构建这样一种language model:给定一个单词,预测下一个可能出现的单词。
这个RNN的输入是dim维的,dim等于词汇量的大小。输入向量只有在代表这个单词的分量上是1,其余为0,即[0,0,0,...0,1,0,...0]。 输出也是dim维的向量,表示每个单词出现的概率。
CNTK上构建RNN模型,主要有两点与普通的神经网络很不一样:
(1)输入格式。 此时输入的是按句子分开的文本,同一个句子内部的单词是有顺序的。所以输入要指定成 LMSequenceReader 的格式。 这个格式很麻烦(再吐槽一下,我也不是很懂,就不详细解释了,大家可以按照格式自行领悟)
(2) 模型:要使用递归模型。 主要是Delay() 函数的使用
一个可用的代码如下(再次被官方教程坑了好久,现代码改编自 CNTK-2016-02-08-Windows-64bit-CPU-Only\cntk\Examples\Text\PennTreebank\Config ):
# Parameters can be overwritten on the command line # for example: cntk cOnfigFile=myConfigFile RootDir=../.. # For running from Visual Studio add # currentDirectory=$(SolutionDir)/RootDir = ".." ConfigDir = "$RootDir$/Config" DataDir = "$RootDir$/Data" OutputDir = "$RootDir$/Output" ModelDir = "$OutputDir$/Models" # deviceId=-1 for CPU, >=0 for GPU devices, "auto" chooses the best GPU, or CPU if no usable GPU is available deviceId = "-1" command = writeWordAndClassInfo:train #command = write precision = "float" traceLevel = 1 modelPath = "$ModelDir$/rnn.dnn" # uncomment the following line to write logs to a file stderr=$OutputDir$/rnnOutput type = double numCPUThreads = 4 confVocabSize = 3000 confClassSize = 50 #trainFile = "ptb.train.txt" trainFile = "review_tokens_split_first5w_lines.txt" #validFile = "ptb.valid.txt" testFile = "review_tokens_split_first10_lines.txt" writeWordAndClassInfo = [ action = "writeWordAndClass" inputFile = "$DataDir$/$trainFile$" outputVocabFile = "$ModelDir$/vocab.txt" outputWord2Cls = "$ModelDir$/word2cls.txt" outputCls2Index = "$ModelDir$/cls2idx.txt" vocabSize = "$confVocabSize$" nbrClass = "$confClassSize$" cutoff = 1 printValues = true ] ####################################### # TRAINING CONFIG # ####################################### train = [ action = "train" minibatchSize = 10 traceLevel = 1 epochSize = 0 recurrentLayer = 1 defaultHiddenActivity = 0.1 useValidation = true rnnType = "CLASSLM" # uncomment below and comment SimpleNetworkBuilder section to use NDL to train RNN LM NDLNetworkBuilder=[ networkDescription="D:\tools\Deep Learning\CNTK-2016-02-08-Windows-64bit-CPU-Only\cntk\Examples\Text\PennTreebank\AdditionalFiles\RNNLM\rnnlm.ndl" ] SGD = [ learningRatesPerSample = 0.1 momentumPerMB = 0 gradientClippingWithTruncation = true clippingThresholdPerSample = 15.0 maxEpochs = 6 unroll = false numMBsToShowResult = 100 gradUpdateType = "none" loadBestModel = true # settings for Auto Adjust Learning Rate AutoAdjust = [ autoAdjustLR = "adjustAfterEpoch" reduceLearnRateIfImproveLessThan = 0.001 continueReduce = false increaseLearnRateIfImproveMoreThan = 1000000000 learnRateDecreaseFactor = 0.5 learnRateIncreaseFactor = 1.382 numMiniBatch4LRSearch = 100 numPrevLearnRates = 5 numBestSearchEpoch = 1 ] dropoutRate = 0.0 ] reader = [ readerType = "LMSequenceReader" randomize = "none" nbruttsineachrecurrentiter = 16 # word class info wordclass = "$ModelDir$/vocab.txt" # if writerType is set, we will cache to a binary file # if the binary file exists, we will use it instead of parsing this file # writerType=BinaryReader # write definition wfile = "$OutputDir$/sequenceSentence.bin" # wsize - inital size of the file in MB # if calculated size would be bigger, that is used instead wsize = 256 # wrecords - number of records we should allocate space for in the file # files cannot be expanded, so this should be large enough. If known modify this element in config before creating file wrecords = 1000 # windowSize - number of records we should include in BinaryWriter window windowSize = "$confVocabSize$" file = "$DataDir$/$trainFile$" # additional features sections # for now store as expanded category data (including label in) features = [ # sentence has no features, so need to set dimension to zero dim = 0 # write definition sectionType = "data" ] # sequence break table, list indexes into sequence records, so we know when a sequence starts/stops sequence = [ dim = 1 wrecords = 2 # write definition sectionType = "data" ] #labels sections labelIn = [ dim = 1 labelType = "Category" beginSequence = "" endSequence = "" # vocabulary size labelDim = "$confVocabSize$" labelMappingFile = "$OutputDir$/sentenceLabels.txt" # Write definition # sizeof(unsigned) which is the label index type elementSize = 4 sectionType = "labels" mapping = [ # redefine number of records for this section, since we don‘t need to save it for each data record wrecords = 11 # variable size so use an average string size elementSize = 10 sectionType = "labelMapping" ] category = [ dim = 11 # elementSize = sizeof(ElemType) is default sectionType = "categoryLabels" ] ] # labels sections labels = [ dim = 1 labelType = "NextWord" beginSequence = "O" endSequence = "O" # vocabulary size labelDim = "$confVocabSize$" labelMappingFile = "$OutputDir$/sentenceLabels.out.txt" # Write definition # sizeof(unsigned) which is the label index type elementSize = 4 sectionType = "labels" mapping = [ # redefine number of records for this section, since we don‘t need to save it for each data record wrecords = 3 # variable size so use an average string size elementSize = 10 sectionType = "labelMapping" ] category = [ dim = 3 # elementSize = sizeof(ElemType) is default sectionType = categoryLabels ] ] ] ] write = [ action = "write" outputPath = "$OutputDir$/Write" #outputPath = "-" # "-" will write to stdout; useful for debugging outputNodeNames = "Out,WFeat2Hid,WHid2Hid,WHid2Word" # when processing one sentence per minibatch, this is the sentence posterior #format = [ #sequencePrologue = "log P(W)=" # (using this to demonstrate some formatting strings) #type = "real" #] minibatchSize = 1 # choose this to be big enough for the longest sentence # need to be small since models are updated for each minibatch traceLevel = 1 epochSize = 0 reader = [ # reader to use readerType = "LMSequenceReader" randomize = "none" # BUGBUG: This is ignored. nbruttsineachrecurrentiter = 1 # one sentence per minibatch cacheBlockSize = 1 # workaround to disable randomization # word class info wordclass = "$ModelDir$/vocab.txt" # if writerType is set, we will cache to a binary file # if the binary file exists, we will use it instead of parsing this file # writerType = "BinaryReader" # write definition wfile = "$OutputDir$/sequenceSentence.bin" # wsize - inital size of the file in MB # if calculated size would be bigger, that is used instead wsize = 256 # wrecords - number of records we should allocate space for in the file # files cannot be expanded, so this should be large enough. If known modify this element in config before creating file wrecords = 1000 # windowSize - number of records we should include in BinaryWriter window windowSize = "$confVocabSize$" file = "$DataDir$/$testFile$" # additional features sections # for now store as expanded category data (including label in) features = [ # sentence has no features, so need to set dimension to zero dim = 0 # write definition sectionType = "data" ] #labels sections labelIn = [ dim = 1 # vocabulary size labelDim = "$confVocabSize$" labelMappingFile = "$OutputDir$/sentenceLabels.txt" labelType = "Category" beginSequence = "" endSequence = "" # Write definition # sizeof(unsigned) which is the label index type elementSize = 4 sectionType = "labels" mapping = [ # redefine number of records for this section, since we don‘t need to save it for each data record wrecords = 11 # variable size so use an average string size elementSize = 10 sectionType = "labelMapping" ] category = [ dim = 11 # elementSize = sizeof(ElemType) is default sectionType = "categoryLabels" ] ] #labels sections labels = [ dim = 1 labelType = "NextWord" beginSequence = "O" endSequence = "O" # vocabulary size labelDim = "$confVocabSize$" labelMappingFile = "$OutputDir$/sentenceLabels.out.txt" # Write definition # sizeof(unsigned) which is the label index type elementSize = 4 sectionType = "labels" mapping = [ # redefine number of records for this section, since we don‘t need to save it for each data record wrecords = 3 # variable size so use an average string size elementSize = 10 sectionType = "labelMapping" ] category = [ dim = 3 # elementSize = sizeof(ElemType) is default sectionType = "categoryLabels" ] ] ] ]
rnnlm.ndl:
run=ndlCreateNetwork ndlCreateNetwork=[ # vocabulary size featDim=3000 # vocabulary size labelDim=3000 # hidden layer size hiddenDim=200 # number of classes nbrClass=50 initScale=6 features=SparseInput(featDim, tag="feature") # labels in classbasedCrossEntropy is dense and contain 4 values for each sample labels=Input(4, tag="label") # define network WFeat2Hid=Parameter(hiddenDim, featDim, init="uniform", initValueScale=initScale) WHid2Hid=Parameter(hiddenDim, hiddenDim, init="uniform", initValueScale=initScale) # WHid2Word is special that it is hiddenSize X labelSize WHid2Word=Parameter( hiddenDim,labelDim, init="uniform", initValueScale=initScale) WHid2Class=Parameter(nbrClass, hiddenDim, init="uniform", initValueScale=initScale) PastHid = Delay(hiddenDim, HidAfterSig, delayTime=1, needGradient=true) HidFromHeat = Times(WFeat2Hid, features) HidFromRecur = Times(WHid2Hid, PastHid) HidBeforeSig = Plus(HidFromHeat, HidFromRecur) HidAfterSig = Sigmoid(HidBeforeSig) Out = TransposeTimes(WHid2Word, HidAfterSig) #word part ClassProbBeforeSoftmax=Times(WHid2Class, HidAfterSig) cr = ClassBasedCrossEntropyWithSoftmax(labels, HidAfterSig, WHid2Word, ClassProbBeforeSoftmax, tag="criterion") EvalNodes=(Cr) OutputNodes=(Cr) ]
从代码上看,CNTK会让人花很大一部分精力在Data Reader上。
writeWordAndClassInfo 是简单的对所有词汇做个统计,并对单词聚类。 这里用的class based RNN,主要是为了加速计算,先把单词分成不相交的几类。 这个模块输出的文件有4列,分别是单词索引,出现频率,单词,类别。
Train 当然就是训练模型了,文本量大的话,训练还是很慢的。
Write 是输出模块,注意看这一行: outputNodeNames = "Out,WFeat2Hid,WHid2Hid,WHid2Word"
我想最多人关心的应该是对于一个句子,运行这个训练好的RNN之后,如何得到隐层的值吧? 我的做法是把训练好的RNN的参数给保存下来,然后...然后无论是用java还是用python的人,都能根据这个参数还原一个RNN网络,然后我们想干嘛就能干嘛了。
Train中我是用了自己定义的模型:NDLNetworkBuilder 。 也可以用通用的递归模型,此时只要简单地规定一个参数就行了,例如
SimpleNetworkBuilder=[ trainingCriterion=classcrossentropywithsoftmax evalCriterion=classcrossentropywithsoftmax nodeType=Sigmoid initValueScale=6.0 layerSizes=10000:200:10000 addPrior=false addDropoutNodes=false applyMeanVarNorm=false uniformInit=true; # these are for the class information for class-based language modeling vocabSize=10000 nbrClass=50 ]
我这里使用自己定义的网络,主要是为了日后想改成LSTM结构。
原创博客,未经允许,请勿转载。
用CNTK搞深度学习 (二) 训练基于RNN的自然语言模型 ( language model )


 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有