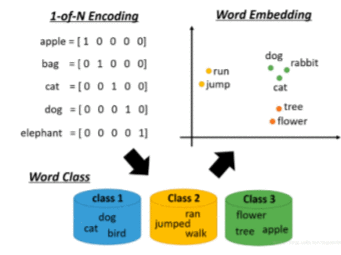
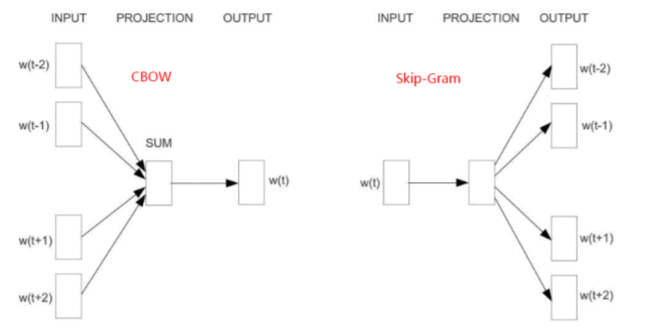
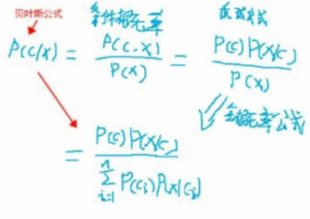
本文是用机器学习打造聊天机器人系列的第六篇,主要介绍代码中用到的相关算法的原理。了解算法原理,可以让我们知道程序背后都做了些什么,为什么有时候会出现错误以及什么场景下选择哪种算法会更合适。
本文是"手把手教你打造聊天机器人"系列的最后一篇,介绍了我们打造的聊天机器人的相关算法原理,下一篇会对本系列做一个总结。
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
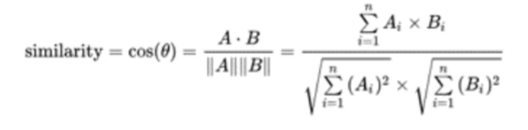
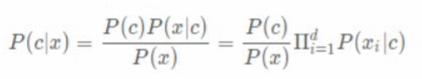

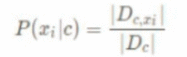
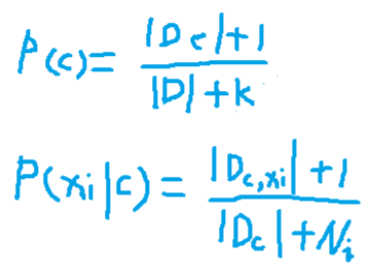










 京公网安备 11010802041100号
京公网安备 11010802041100号