目录
0、引言
1、病变检测
2、图像分割
基于深度学习的医学图像分割与检测
3、图像配准
图像配准的定义
4、图像融合
5、预测与挑战
6、结论
参考文献
医学图像处理的对象是各种不同成像机理的医学影像,临床广泛使用的医学成像种类主要有X-射线成像 (X-CT)、核磁共振成像(MRI)、核医学成像(NMI)、超声波成像(UI)四类。在目前的影像医疗诊断中,主要是通过观察一组二维切片图象去发现病变体,这往往需要借助医生的经验来判定。利用计算机图像处理技术对二维切片图象进行分析和处理,实现对人体器官、软组织和病变体的分割提取、三维重建和三维显示,可以辅助医生对病变体及其它感兴趣的区域进行定性甚至定量的分析,从而大大提高医疗诊断的准确性和可靠性;在医疗教学、手术规划、手术仿真及各种医学研究中也能起重要的辅助作用[1,2]。目前,医学图像处理主要集中表现在病变检测、图像分割、图像配准及图像融合四个方面。
用深度学习方法进行数据分析呈现快速增长趋势,称为2013年的10项突破性技术之一。深度学习是人工神经网络的改进,由更多层组成,允许更高层次包含更多抽象信息来进行数据预测。迄今为止,它已成为计算机视觉领域中领先的机器学习工具,深度神经网络学习自动从原始数据(图像)获得的中级和高级抽象特征。最近的结果表明,从CNN中提取的信息在自然图像中的对目标识别和定位方面非常有效。世界各地的医学图像处理机构已经迅速进入该领域,并将CNN和其它深度学习方法应用于各种医学图像分析。
在医学成像中,疾病的准确诊断和评估取决于医学图像的采集和图像解释。近年来,图像采集已经得到了显着改善,设备以更快的速率和更高的分辨率采集数据。然而,图像解释过程,最近才开始受益于计算机技术。对医学图像的解释大多数都是由医生进行的,然而医学图像解释受到医生主观性、医生巨大差异认知和疲劳的限制。
用于图像处理的典型CNN架构由一系列卷积网络组成,其中包含有一系列数据缩减即池化层。与人脑中的低级视觉处理一样,卷积网络检测提取图像特征,例如可能表示直边的线或圆(例如器官检测)或圆圈(结肠息肉检测),然后是更高阶的特征,例如局部和全局形状和纹理特征提取[3]。CNN的输出通常是一个或多个概率或种类标签。
CNN是高度可并行化的算法。与单核的CPU处理相比,今天使用的图形处理单元(GPU)计算机芯片实现了大幅加速(大约40倍)。在医学图像处理中,GPU首先被引入用于分割和重建,然后用于机器学习。由于CNN的新变种的发展以及针对现代GPU优化的高效并行网络框架的出现,深度神经网络吸引了商业兴趣。从头开始训练深度CNN是一项挑战[4]。首先,CNN需要大量标记的训练数据,这一要求在专家注释昂贵且疾病稀缺的医学领域中可能难以满足。其次,训练深度CNN需要大量的计算和内存资源,否则训练过程将是非常耗时。第三,深度CNN训练过程中由于过度拟合和收敛问题而复杂化,这通常需要对网络的框架结构或学习参数进行重复调整,以确保所有层都以相当的速度学习[5]。鉴于这些困难,一些新的学习方案,称为“迁移学习”和“微调”,被证明可以解决上述问题从而越来越受欢迎。
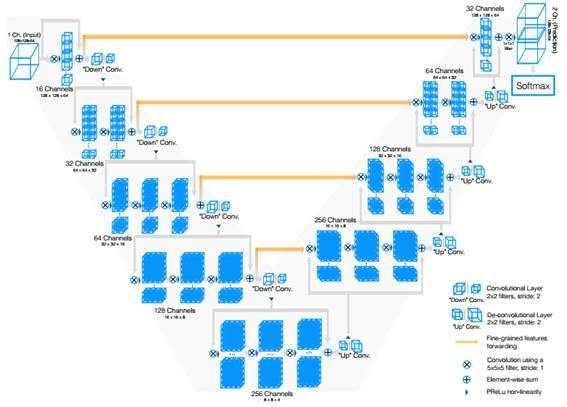
计算机辅助检测(CAD)是医学图像分析的有待完善的领域,并且非常适合引入深度学习。在CAD 的标准方法中,一般通过监督方法或经典图像处理技术(如过滤和数学形态学)检测候选病变位置。病变位置检测是分阶段的,并且通常由大量手工制作的特征描述。将分类器用于特征向量映射到候选者来检测实际病变的概率。采用深度学习的直接方式是训练CNN操作一组以图像为中心的图像数据候选病变。Setio 等在 3D 胸部 CT 扫描中检测肺结节,并在九个不同方向上提取以这些候选者为中心的2D贴片[6],使用不同CNN的组合来对每个候选者进行分类,CAD系统结构如图1所示。根据检测结果显示,与先前公布的用于相同任务的经典CAD系统相比略有改进。罗斯等人应用CNN改进三种现有的CAD系统,用于检测CT成像中的结肠息肉,硬化性脊柱变形和淋巴结肿大[7]。他们还在三个正交方向上使用先前开发的候选检测器和2D贴片,以及多达100个随机旋转的视图。随机旋转的“2.5D”视图是从原始3D数据分解图像的方法。采用CNN对这些2.5D视图图像检测然后汇总,来提高检测的准确率。对于使用CNN的三个CAD系统,病变检测的准确率度提高了13-34%,而使用非深度学习分类器(例如支持向量机)几乎不可能实现这种程度的提升。早在1996年,Sahiner等人就已将CNN应用于医学图像处理。从乳房X线照片中提取肿块或正常组织的ROI。 CNN由输入层,两个隐藏层和输出层组成,并用于反向传播。在“GPU时代”以前,训练时间被描述为“计算密集型”,但没有给出任何时间。1993年,CNN应用于肺结节检测;1995年CNN用于检测乳腺摄影中的微钙化。
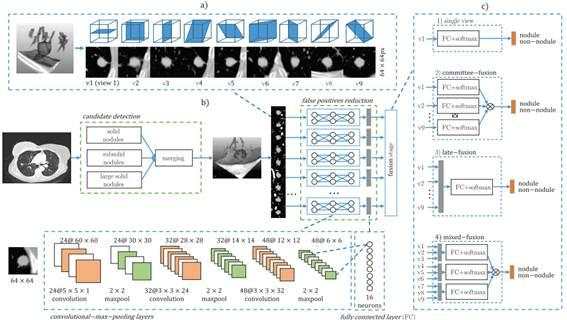
图1.CAD系统概述。(a)从立方体的九个对称平面中提取的二维斑块的示例。候选者位于贴片的中心,边界框为50 50 mm和64 64 px。(b)通过合并专门为固体,亚固体和大结节设计的探测器的输出来检测候选人。误报减少阶段是作为多个ConvNets的组合实现的。每个ConvNets流处理从特定视图中提取的2-D补丁。(c)融合每个ConvNet流输出的不同方法。 灰色和橙色框表示来自第一个完全连接的层和结节分类输出的连接神经元。 使用完全连接的层与softmax或固定组合器(产品规则)组合神经元。(a)使用体积对象的九个视图提取二维补丁。(b)拟议系统的示意图。(c)融合方法。
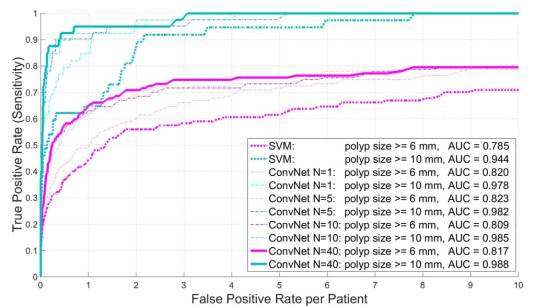
图2.结肠息肉的检测:不同息肉大小的FROC曲线,使用792测试CT结肠成像患者的随机视图ConvNet观察。
医学图像分割 就是一个根据区域间的 相似 或 不同 把图像分割成若干区域的过程。目前,主要以各种细胞、组织与器官的图像作为处理的对象。
传统的图像分割技术有:
基于区域的分割方法 ,依赖于图像的空间局部特征,如灰度、纹理及其它象素统计特性的均匀性等
基于边界的分割方法,主要是利用梯度信息确定目标的边界。
结合特定的理论工具,图象分割技术有了更进一步的发展。比如基于三维可视化系统结合FastMarching算法和Watershed 变换的医学图象分割方法,能得到快速、准确的分割结果[8]。
近年来,随着其它新兴学科的发展,产生了一些全新的图像分割技术。
虽然不断有新的分割方法被提出,但结果都不是很理想。目前研究的热点是一种基于知识的分割方法,即通过某种手段将一些先验的知识导入分割过程中,从而约束计算机的分割过程,使得分割结果控制在我们所能认识的范围内而不至于太离谱。比如在肝内部肿块与正常肝灰度值差别很大时,不至于将肿块与正常肝看成 2 个独立的组织。
医学图像分割方法的研究具有如下显著特点:
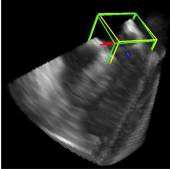
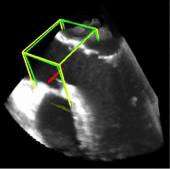
利用2891次心脏超声检查的数据集,Ghesu等结合深度学习和边缘空间学习进行医学图像检测和分割[12]。“大参数空间的有效探索”和在深度网络中实施稀疏性的方法相结合,提高了计算效率,并且与同一组发布的参考方法相比,平均分割误差减少了13.5%,八位患者的检测结果如图4所示。Brosch等人利用 MRI(核磁共振成像) 图像上研究多发性硬化脑病变分割的问题。开发了一种3D深度卷积编码器网络,它结合了卷积和反卷积[13],图5.增加网络深度对病变的分割性能的影响。卷积网络学习了更高级别的特征,并且反卷积网络预进行像素级别分割。将网络应用于两个公开的数据集和一个临床试验数据集,与5种公开方法进行了比较,展现了最好的方法。Pereira等人的研究中对MRI上的脑肿瘤分割进行了研究,使用更深层的架构,数据归一化和数据增强技巧[14]。将不同的CNN架构用于肿瘤,该方法分别对疑似肿瘤的图像增强和核心区域进行分割。在2013年的公共挑战数据集上获得了最高成绩。
 |  |  |
|---|---|---|
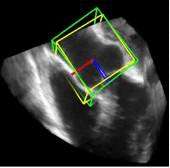 | 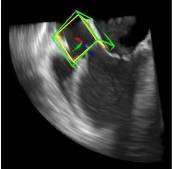 | 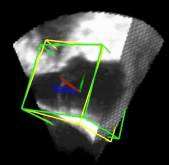 |
图4. 示例图像显示了不同患者的检测结果从测试集。检测到的边界框以绿色显示,标准的框以黄色显示。原点位于每个框中心的线段定义相应的坐标系
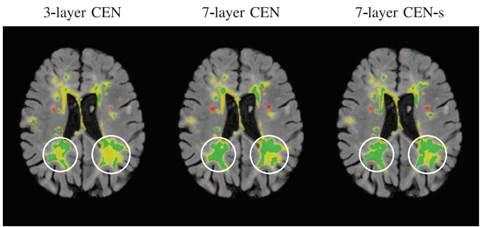
图5. 增加网络深度对病变的分割性能的影响。真阳性,假阴性和假阳性体素分别以绿色,黄色和红色突出显示。由于感受野的大小增加,具有和不具有捷径的7层CEN能够比3层CEN更好地分割大的病变。
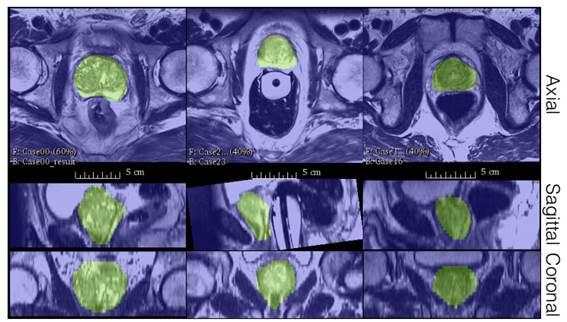
2018年德国医疗康复机构提出一种具有代表性的基于全卷积的前列腺图像分割方法。用CNN在前列腺的MRI图像上进行端到端训练,并可以一次完成整个分割。提出了一种新的目标函数,在训练期间根据 Dice 系数进行优化[15]。通过这种方式,可以处理前景和背景之间存在不平衡的情况,并且增加了随机应用的数据非线性变换和直方图匹配。实验评估中表明,该方法在公开数据集上取得了优秀的结果,并大大降低了处理时间。
图象配准是图象融合的前提,是公认难度较大的图象处理技术,也是决定医学图象融合技术发展的关键技术。
在临床诊断中,单一模态的图像往往不能提供医生所需要的足够信息,常需将多种模式或同一模式的多次成像通过配准融合来实现感兴趣区的信息互补。在一幅图像上同时表达来自多种成像源的信息,医生就能做出更加准确的诊断或制定出更加合适的治疗方法[16]。
医学图像配准包括图像的定位和转换,即通过寻找一种空间变换使两幅图像对应点达到空间位置和解剖结构上的完全一致。图8简单说明了二维图像配准的概念。图(a)和图(b)是对应于同一人脑同一位置的两幅 MRI 图像,其中图(a)是质子密度加权成像,图(b)是纵向弛豫加权成像。这两幅图像有明显的不同,
第一是方位上的差异,即图(a)相对于图(b)沿水平和垂直方向分别进行了平移;
第二是两幅图像所表达的内容是不一致的,图(a)表达不同组织质子含量的差别,而图(b)则突出不同组织纵向弛豫的差别。
图(c)给出了两幅图像之间像素点的对应映射关系,即(a)中的每一个点fx都被映射到(b)中唯一的一个点rx。
如果这种映射是一 一对应的,即一幅图像空间中的每一个点在另外一幅图像空间中都有对应点,或者至少在医疗诊断上感兴趣的那些点能够准确或近似准确的对应起来,我们就称之为配准[17,18]。
图(d)给出了图(a)相对于图(b)的配准图像。从图(d)中可以看出,图(d)与(b)之间的的像素点的空间位置已经近似一致了。1993 年 Petra 等综述了二维图像的配准方法,并根据配准基准的特性,将图像配准的方法分为基于外部特征的图象配准(有框架) 和基于图象内部特征的图象配准(无框架) 两种方法。 后者由于其无创性和可回溯性, 已成为配准算法的研究中心。
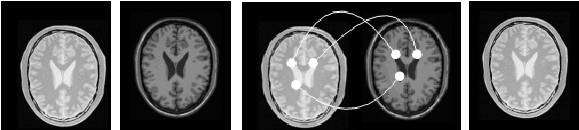
(a) (b) (c) (d)
图8 医学图像配准原理
2019年华中科技大学对基于 PCANet 的结构非刚性多模医学图像配准展开研究。提出了一种基于PCANet的结构表示方法用于多模态医学图像配准[19]。与人工设计的特征提取方法相比,PCANet可以通过多级线性和非线性变换自动从大量医学图像中学习内在特征。所提出的方法可以通过利用 PCANet 的各个层中提取的多级图像特征来为多模态图像提供有效的结构表示。对Atlas,BrainWeb和RIRE数据集的大量实验表明,与MIND,ESSD,WLD和NMI方法相比,所提出的方法可以提供更低的TRE值和更令人满意的结果。
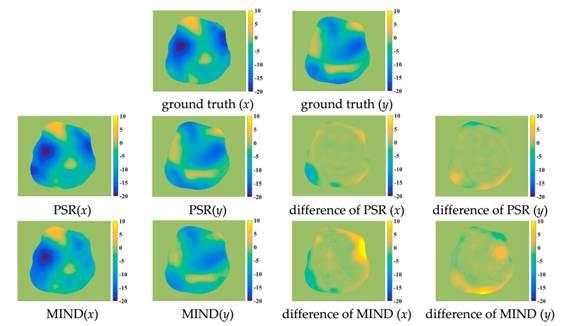
图9 第一行分别是x和y方向变形的真实结果,第二行是PSR与x和y方向的真实情况的差异;第三行是MIND方法的变形和真实值之间的差异
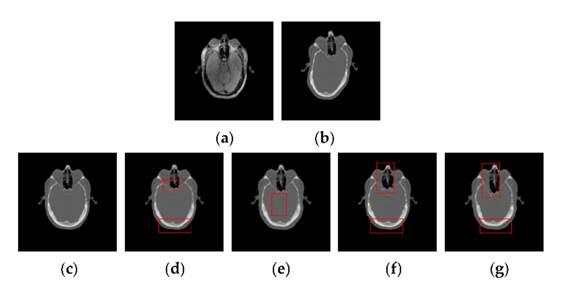
图10 PSR,MIND,ESSD,WLD和NMI方法的CT-MR图像配准。(a)参考PD图像;(b)浮动CT图像;(c)PSR方法;(d)MIND方法;(e)ESSD方法;(f)WLD方法;(g)NMI方法
近年来,医学图像配准技术有了新的进展,在配准方法上应用了信息学的理论和方法,例如应用最大化的互信息量作为配准准则进行图像的配准,基于互信息的弹性形变模型也逐渐成为研究热点[20]。在配准对象方面从二维图像发展到三维多模医学图像的配准。一些新算法,如基于小波变换的算法、统计学参数绘图算法、遗传算法等,在医学图像上的应用也在不断扩展。向快速和准确方面改进算法,使用最优化策略改进图像配准以及对非刚性图像配准的研究是今后医学图像配准技术的发展方向[21,22]。
图像融合的主要目的是通过对多幅图像间的冗余数据的处理来提高图像的可读性,对多幅图像间的互补信息的处理来提高图像的清晰度。多模态医学图像的融合把有价值的生理功能信息与精确的解剖结构结合在一起,可以为临床提供更加全面和准确的资料[23]。融合图像的创建分为图像数据的融合与融合图像的显示两部分来完成。
目前,图像数据融合主要有:
融合图像的显示常用的有伪彩色显示法、断层显示法和三维显示法等。伪彩色显示一般以某个图像为基准,用灰度色阶显示,另一幅图像叠加在基准图像上,用彩色色阶显示。断层显示法常用于某些特定图像,可以将融合后的三维数据以横断面、冠状面和矢状面断层图像同步地显示,便于观察者进行诊断。三维显示法是将融合后数据以三维图像的形式显示,使观察者可更直观地观察病灶的空间解剖位置,这在外科手术设计和放疗计划制定中有重要意义。
在图像融合技术研究中,不断有新的方法出现,其中小波变换、 基于有限元分析的非线性配准以及人工智能技术在图像融合中的应用将是今后图像融合研究的热点与方向。随着三维重建显示技术的发展,三维图像融合技术的研究也越来越受到重视,三维图像的融合和信息表达,也将是图像融合研究的一个重点。
在计算机辅助图像处理的基础上,开发出综合利用图像处理方法, 结合人体常数和部分疾病的影像特征来帮助或模拟医生分析、诊断的图像分析系统成为一种必然趋势。目前已有一些采用人机交互定点、自动测量分析的图像分析软件,能定点或定项地完成一些测量和辅助诊断的工作,但远远没有达到智能分析和专家系统的水平;全自动识别标志点并测量分析以及医学图像信息与文本信息的融合, 是计算机辅助诊断技术今后的发展方向。
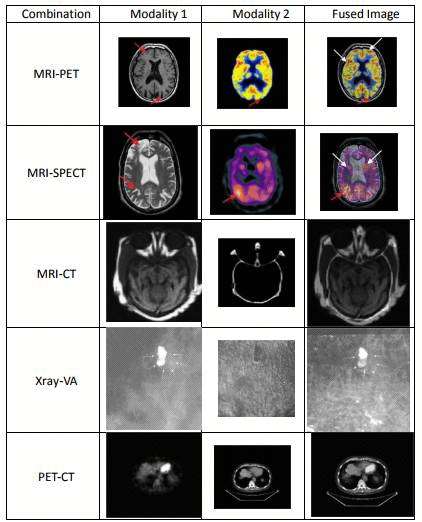
图12 多模态医学图像融合的例子。使用特定图像融合技术的模态1与模态2的组合可以使医学诊断和评估改进
1)数据维度问题-2D与3D:在迄今为止的大多数工作中,是在2D图像中进行处理分析。人们常常质疑向3D过渡是否是迈向性能提高的重要一步。数据增强过程中存在若干变体,包括2.5D。例如,在Roth等人的研究中,以结肠息肉或淋巴结候选体中的体素为中心截取轴向图像,存在冠状和矢状图像。
2)学习方法 - 无监督与监督:当我们查看网络文献时,很明显大多数工作都集中在受监督的CNN上,以实现分类。这种网络对于许多应用是重要的,包括检测,分割和标记。尽管如此,一些工作仍集中于无监督方案,这些方案主要表现为图像编码。诸如玻尔兹曼机器(RBM)之类的无监督表示学习方法可能胜过滤波器,因为它们直接从训练数据中学习特征描述。RBM通过生成学习目标进行培训;这使网络成为可能从未标记的数据中学习,但不一定产生最适合分类的特征。Van Tulder等人进行了一项调查,结合卷积分类和RBM的生成和判别学习目标的优点,该机器学习了对描述训练数据和分类都很好的过滤器。结果表明,学习目标的组合完全胜过生成性学习。
3)迁移学习和微调:在医学成像领域中获取与ImageNet一样全面注释的数据集仍然是一个挑战。当没有足够的数据时,有几种方法可以继续:
4)数据隐私受社会和技术问题的影响,需要从社会学和技术学的角度共同解决。在卫生部门讨论隐私时,会想到HIPAA(1996年健康保险流通与责任法案)。它为患者提供有关保护个人身份信息的法律权利,并为医疗保健提供者承担保护和限制其使用或披露的义务。在医疗保健数据不断增加的同时,研究人员面临如何加密患者信息以防止其被使用或披露的问题。同时带来,限制访问数据可能遗漏非常重要的信息。
近几年来,与传统的机器学习算法相比,深度学习在日常生活自动化方面占据了中心位置,并取得了相当大的进步。基于优秀的性能,大多数研究人员认为在未来15年内,基于深度学习的应用程序将接管人类和大多数日常活动。但是,与其它现实世界的问题相比,医疗保健领域的深度学习尤其是医学图像的发展速度非常慢。到目前为止深度学习应用提供了积极的反馈,然而,由于医疗保健数据的敏感性和挑战,我们应该寻找更复杂的深度学习方法,以便有效地处理复杂的医疗数据。随着医疗技术和计算机科学的蓬勃发展,对医学图象处理提出的要求也越来越高。有效地提高医学图象处理技术的水平,与多学科理论的交叉融合,医务人员和理论技术人员之间的交流就显得越来越重要。医学图象处理技术作为提升现代医疗诊断水平的有力依据, 使实施风险低、创伤性小的手术方案成为可能,必将在医学信息研究领域发挥更大的作用。
[1]林晓, 邱晓嘉. 图像分析技术在医学上的应用 [J] . 包头医学院学报, 2005, 21 (3) : 311~ 314
[2]周贤善. 医学图像处理技术综述[J]. 福建电脑, 2009(1):34-34.
[3]Mcinerney T , Terzopoulos D . Deformable models in medical image analysis: a survey[J]. Medical Image Analysis, 1996, 1(2):91.
[4]Litjens G , Kooi T , Bejnordi B E , et al. A survey on deep learning in medical image analysis[J]. Medical Image Analysis, 2017, 42:60-88.
[5]Deserno T M , Heinz H , Maier-Hein K H , et al. Viewpoints on Medical Image Processing: From Science to Application[J]. Current Medical Imaging Reviews, 2013, 9(2):79-88.
[6]A. Setio et al., “Pulmonary nodule detection in CT images using multiview convolutional networks,” IEEE Trans. Med. Imag., vol. 35, no. 5,pp. 1160–1169, May 2016.
[7]H. Roth et al., “Improving computer-aided detection using convolutional neural networks and random view aggregation,” IEEE Trans.Med. Imag., vol. 35, no. 5, pp. 1170–1181, May 2016
[8]林瑶, 田捷. 医学图像分割方法综述[J]. 模式识别与人工智能, 2002, 15(2).
[9]Ghesu F C , Georgescu B , Mansi T , et al. An Artificial Agent for Anatomical Landmark Detection in Medical Images[C]// International Conference on Medical Image Computing & Computer-assisted Intervention. Springer, Cham, 2016.
[10]Pham D L , Xu C , Prince J L . Current methods in medical image segmentation.[J]. Annual Review of Biomedical Engineering, 2000, 2(2):315-337.
[11]Lehmann T M , Gonner C , Spitzer K . Survey: interpolation methods in medical image processing[J]. IEEE Transactions on Medical Imaging, 1999, 18(11):1049-1075.
[12]Cootes T F , Taylor C J . Statistical Models of Appearance for Medical Image Analysis and Computer Vision[J]. Proceedings of SPIE - The International Society for Optical Engineering, 2001, 4322(1).
[13] T. Brosch et al., “Deep 3D convolutional encoder networks with shortcuts for multiscale feature integration applied to multiple sclerosis lesion segmentation,” IEEE Trans. Med. Imag., vol. 35, no. 5,pp. 1229–1239, May 2016.
[14]Ghesu F C , Krubasik E , Georgescu B , et al. Marginal Space Deep Learning: Efficient Architecture for Volumetric Image Parsing[J]. IEEE Transactions on Medical Imaging, 2016, 35(5):1217-1228.
[15]Milletari F , Navab N , Ahmadi S A . V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation[J]. 2016.
[16] .周永新, 罗述谦. 一种人机交互式快速脑图象配准系统[J] . 北京生物医学工程, 2002; 21 (1) :11~14
[17]杨虎, 马斌荣, 任海萍. 基于互信息的人脑图象配准研究[J] . 中国医学物理学杂志, 2001; 18 (2) :69~73
[18]汪家旺,愈同福,姜晓彤,等.肺部孤立性结节定量研究[J].中国医学影 像技术,2003,19(9):1218~1219
[19]Ishihara S , Ishihara K , Nagamachi M , et al. An analysis of Kansei structure on shoes using self-organizing neural networks[J]. International Journal of Industrial Ergonomics, 1997, 19(2):93-104.
[20]Maintz J B , Viergever M A . A Survey of Medical Image Registration[J]. Computer & Digital Engineering, 2009, 33(1):140-144.
[21]Hill D L G , Batchelor P G , Holden M , et al. Medical image registration[J]. Physics in Medicine & Biology, 2008, 31(4):1-45.
[22]Razzak M I , Naz S , Zaib A . Deep Learning for Medical Image Processing: Overview, Challenges and Future[J]. 2017.
[23]林晓, 邱晓嘉. 图像分析技术在医学上的应用 [J] . 包头医学院学报, 2005, 21 (3) : 311~ 314







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
