前言
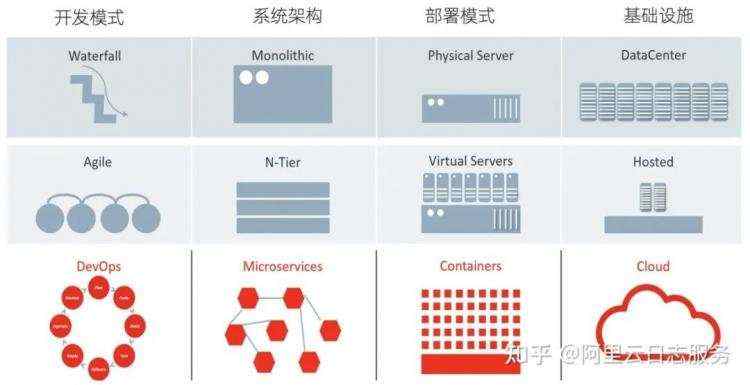
监控作为每个公司IT系统中必备的功能,伴随着计算机的诞生就已经开始出现,经过几十年的发展,现在的IT技术和架构已经出现了非常大的变化。开发模式、系统架构、部署模式、基础设施都已经经历过多次的架构变迁,目前主流以微服务、容器化、云、DevOps这些技术为主。
伴随着这些架构的变迁,带来的影响是整个的系统也更加的复杂、开发依赖更多的人和部门、部署模式和运行环境也更加动态和不确定,因此IT行业也已经到了需要更加系统化、体系化进行观测的这一过程。对于监控系统,也在经历着巨大的变革,朝向云原生、数据融合、智能等方向演进。
回顾整个IT监控的发展过程,我个人认为可分为4个阶段,分别是Unix时代、数据中心时代、分布式时代以及云原生时代:
Unix时代:随着Unix、Linux的流行,我们才有了真正意义上的IT系统,在80、90年代的时候,应用通常都是单机部署,而且很简单。为了能够定位单机应用的一些问题,Unix中增加了很多Metrics,例如CPU、内存、IO的使用情况。同时为了更快速的获取这些指标,Unix/Linux中提供了很多命令行工具,例如top、vmstat、iostat等,同时为使用桌面系统的人提供了很多图形化的工具来看问题,这也是IT监控中最早的折线图应用。在这一阶段,大家对于性能、用户体验等关注不是高,基本上只在乎可用性,也就是服务是否能够Work。
数据中心时代:在90年代,越来越多的公司开始搭建自己的数据中心,少到几台,多到成百上千台。这个时候出现了专门的IT运维人员,为了更好的管理这些机器,开发了SNMP(Simple Network Management Protocol)协议,用于管理和监控数据中心中每台机器的状态。这个时候的监控架构主要还是单机的方式来实现,通过SNMP协议,来监控各个主机的网络和硬件信息。这一阶段也出现了跨主机的应用以及提供对外服务的Web类应用,监控系统也会部分关注网络延迟,但并不是实际的用户请求延迟。
分布式时代:在21世纪后,互联网开始流行,应用场景也越来越广,单机已经逐渐承受不住日益上涨的请求量,因此分层式的分布式架构开始逐渐流行。而监控系统的分层模式也划分的逐渐明显,例如主机监控、网络监控、中间件监控、应用监控等,其中应用监控是新出现的范畴,对于应用监控要求不仅关注应用可用性问题,也要监控和解决性能问题。这一阶段监控系统的架构也变为分布式,后端会有多台机器多个模块组成,例如数据处理、存储、告警等,其中每个模块也可能是分布式的,例如分布式的流式处理、分布式的数据库等。
云原生时代:随着云计算、容器化技术的成熟,很多公司开始采用容器化、微服务的技术来开发应用,应用的部署环境也会选择公有云或者私有云的方式。在云原生的场景下,虚拟化会更加彻底、环境动态性更强,传统的一些监控方式将不再适合,因此需要有能够对接Kubernetes、微服务、云上资源的监控系统。而监控目的也更加向上,关注用户实际的体验和问题排查的效率,因此除了采集更多的监控信息外,也需要能够和其他的可观测数据(例如Logs/Traces)进行关联分析来快速定位问题,同时也引入AI的技术来进行自动化的异常发现、定位与修复。
云原生时代的监控方案,除了监控方案本身需要的进步外,监控的能力和效果也必须提升一个阶层,这里我们总结起来,需要以下几个特性:
范围广:从基础设施、容器/K8s、云厂商、中间件、数据库等都能够支持
统一视图:各种不同层级的数据都能有统一的入口和视图来查看
统一告警:告警是监控的重要组成部分,告警也必须能够实现统一的管理,并且具备智能降噪、动态值班表、告警合并/路由等一些高级特性,降低管理和使用成本
智能:企业的IT系统中所涉及的组件数量庞大,静态的规则告警很难适用,因此必须要有一些启发式的AIOps时序异常检测方式,能够自动发现异常的曲线并告警
数据融合分析:可以便捷的和Trace、Log、Event等其他可观测数据有效的进行关联分析,便于快速定位和解决问题
SLS作为阿里可观测性数据引擎,具备可观测数据日志、指标、分布式链路追踪、事件等的一站式采集和存储。为了便于用户快速接入和监控业务系统,SLS提供了全栈监控的APP,将各类监控数据汇总到一个实例中进行统一的管理和监控。全栈监控基于SLS的监控数据采集、存储、分析、可视化、告警、AIOps等能力构建,详细功能如下:
实时监控各类系统,包括主机监控、Kubernetes监控、数据库监控、中间件监控等。
支持ECS、K8s一键安装,支持图形化的监控配置管理,无需登录主机配置采集监控项。
运维老司机多年经验的报表总结,包括资源总览、水位监控、热点分析、详细指标等数十个报表。
支持自定义的分析,支持包括PromQL、SQL92等多种分析语法。
支持对接AIOps指标巡检,利用机器学习技术自动发现异常指标。
支持自定义告警配置,告警通知直接对接消息中心、短信、邮件、语音(电话)、钉钉,并支持对接自定义WebHook。
现阶段全栈监控提供了主机监控、K8s监控、数据库监控、中间件监控,后续横向和纵向的功能扩展也即将和大家见面,例如:
云资源监控,包括阿里云上各类监控以及AWS、Azure等其他云上的监控指标
主机增加更多的功能,例如进程级别监控、内核的监控、进程/内核Profile能力等
K8s增加性能、变更以及服务拓扑等监控能力;数据库增加诊断、Plan监控等;中间件支持更多的种类
增加和用户体验以及应用相关的监控能力,例如拨测、前端监控、移动端监控等
作者:阿里云日志服务链接:https://www.zhihu.com/question/27464246/answer/2425864444来源:知乎
小编有话说
➤推荐服务:
向下滑动查看更多
点击【IT面试精选】查看全网最权威的一线大厂面试真题及面试经验,每天更新哦!
点击【IT路边社】查看实时更新的IT新闻资讯
点击【互联网资料存储站】获取全网最全运维流程文档、表格、脚本、架构、等保资料等点击【安全加固】获取最新安全加固脚本
点击【一键iptables脚本】获取iptables自动设置脚本
回复【加群】群满啦!~添加波哥微信拉您进群
























 京公网安备 11010802041100号
京公网安备 11010802041100号