
一文入门Es、Logstash、Kibana

前言
Elasticsearch是什么?既然它是英文的,我们不妨借助有道从Elasticsearch这几个字母出发来看看其字面上所表达的意思吧。其分为elastic和search两个独立的单词,既然如此,我们无脑有道一波,得到的解释如下:
从有道的解释来看,我们可以简单的对其理解为:Elasticsearch是及其具有弹性的、灵活的、像松紧带一样的且可供搜寻检索的一款工具。o(*≧▽≦)ツ┏━┓
百度百科对其解释如下:
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache、Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
从如上信息我们可以得知,Elasticsearch是一款实时、分布式存储的搜索引擎,在实际开发过程中,我们常常会把数据放在Elasticsearch搜索引擎中,然后从引擎中去实际需要的数据。而且在实际搜索过程中,我们也会有许多的Api支持来对数据进行检索,比如排序、条件查询等,其中在Elasticsearch中最为强大之处就是他的模糊检索功能。讲到这,可能有些Mysql经验但没接触过Elasticsearch的朋友可能会有个疑问,Mysql大法不是无敌么,其中的like语句不能模糊查询么?where and不能条件检索么?orderby不能对数据进行排序么?我随随便便就信手拈来一个Sql语句不就能实现业务的需求么:
select department_name, count(*) 员工个数
from departments d, employees e
where d.department_id = e.department_id
group by d.department_id
having count(*)>5
order by count(*) desc;是这样没错,以上SQL代码的确能够实现实际需求,但是当我们的业务逐渐变得复杂、庞大,我们的用户量越来越多,我们就不得不站在用户的角度来想想了。试想一下,假设哪些淘宝er每天打开淘宝搜索自己想要的数据时都要等个几十秒,那会是怎样的一种画面。又比如,在打开我们常见文件来检索我们需要数据的时候,比如txt、word、excel,我们一般都能迅速打开,那是因为这些文件占用实际空间都太小,这些文件大多就几kb,假设我们打开一个以G为单位的日志文件,此时的系统还能像以往那样正常么?换言之,Elasticsearch采用的是索引搜索,能够具有强大的搜索能力,能够达到实时搜索,稳定,可靠,快速,安装的效用。
另外,Elasticsearch在处理日志的过程中,其常常与数据收集和日志解析引擎Logstash以及名为Kibana的分析和可视化平台配合使用,也就是常说的ELK系统。文本将主要介绍以下几个方面的内容
- 基于Docker容器来搭建ELK系统
- Elasticsearch集群的搭建
- 在Elasticsearch中引入IK分词器插件
- 重点讲解基于
SpringData Es来对Elasticsearch进行操作 - 最后基于本小程序中数据库中的数据来熟练操作Elasticsearch
ELK系统的搭建
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
1
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据
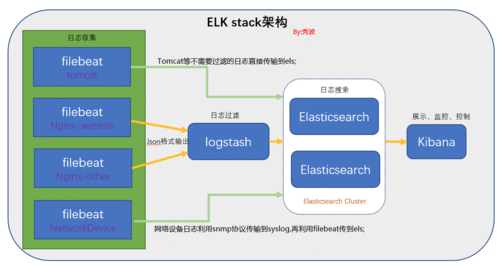
总结就是Elasticsearch用于搜索,Kibana用于可视化,Logstash用于搜集。下面我们来基于Docker来搭建一下ELK系统,关于Docker的安装及基本使用,前面的文章已经有过记录了,此处不再过多的介绍。另外,值得注意的是这三者之间的版本关系,(如果使用其他版本的工具,则按照如下方式搭建可能会产生其他问题):
- Elasticsearch:5.6.8
- Kibana:5.6.8
- Logstash:lastest
Elasticsearch的安装
- Docker拉取Elasticsearch镜像
docker pull elasticsearch:5.6.8- 在本地创建elasticsearch容器所映射的配置文件以及data目录
# 在centos本地创建配置文件,并配置
mkdir -p /resources/elasticsearch/config # 创建config目录
mkdir -p /resources/elasticsearch/data # 创建data目录
# 将http.host配置为0.0.0.0的授权对象,将配置写入config目录下的elasticsearch.yml配置文件中
echo "http.host: 0.0.0.0" >> /resources/elasticsearch/config/elasticsearch.yml- 创建一个elasticsearch容器,并开机自运行
# 创建容器并开机运行(single-node表示单节点模式,后面会介绍集群方式下elasticsearch的搭建)
# 注意:在docker中表示换行
docker run --name elasticsearch -p 9200:9200
-e "discovery.type=single-node"
-e ES_JAVA_OPTS="-Xms256m -Xmx256m"
-v /resources/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /resources/elasticsearch/data:/usr/share/elasticsearch/data -d elasticsearch:5.6.8
# 参数介绍:
# --name:为容器起一个别名
# -p:将容器的运行端口映射到本地端口
# -e "discovery.type=single-node":表示单节点模式下创建,后文将介绍集群模式的搭建
# -v:表示将容器中的配置文件和data文件映射到上文本地所创建的文件,方便后面的配置
# 将elasticsearch容器设置为开机自启动
docker update new-elasticsearch --restart=always这样一来,我们便安装好elasticsearch了,我们可以使用curl命令来测试一下:
# 使用curl来访问elasticsearch的运行端口
curl localhost:9200
# 运行输出结果如下则成功安装
{
"name" : "XwmNOpR",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "yB3VNHxmQzevk1vXUQTkcg",
"version" : {
"number" : "5.6.8",
"build_hash" : "688ecce",
"build_date" : "2018-02-16T16:46:30.010Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}当然了,我们也可以使用浏览器来对其进行访问,访问方式为http://[ip]:9200,端口为虚拟机ip,同样可以得到对应的结果,另外如果使用的是阿里云或腾讯云服务器,则需要在控制台中配置相应的安全组,否则无法访问
安装kibana
- Docker拉取Kibana镜像
# Docker拉取Kibana镜像
docker pull kibana:5.6.8- 创建容器并设置开机自启动
# 创建容器kibana容器,对应的参数如上,另外需要指定elasticsearch的地址
docker run --name kibana -e ELASTICSEARCH_URL=http://[ip]:9200 -p 5601:5601
-d kibana:5.6.8
# 配置开机自启动
docker update new-kibana --restart=always安装完成之后,我们便可curl一下kibana的地址,或在浏览器访问http://[ip]:5601即可:
[root@iZm5eei156c9h3hrdjpe77Z ~]# curl localhost:5601
[root@iZm5eei156c9h3hrdjpe77Z ~]# 安装logstash
- 拉取Logstash镜像
# 拉取镜像
docker pull logstash- 创建一个配置文件,并进行input和output的配置
# 在/resources/logstash中创建logstash.conf文件,并使用vim来对其进行编辑
mkdir /resources/logstash
# 使用vim编辑
vim logstash.conf
# 配置文件内容如下,更换为自己Elasticsearch的ip即可
input {
tcp {
port => 4560
codec => json_lines
}
}
output{
elasticsearch {
hosts => ["[ip]:9200"]
index => "applog"
}
stdout { codec => rubydebug }
}- 创建容器并开机自启动
# 创建容器,这里需要指明Elasticsearch来进行链接
docker run -d -p 4560:4560
-v /resources/logstash/logstash.conf:/etc/logstash.conf
--link elasticsearch:elasticsearch
--name logstash logstash
logstash -f /etc/logstash.conf
# 开机自启动
docker update new-logstash --restart=always- 以上便是Logstash的安装过程,我们可以进入Logstash容器内来简单的使用以下
进入Logstash容器,并cd到bin目录
docker exec -it logstash /bin/bash
cd /usr/share/logstash/bin执行logstash命令
# 注意:需要这里需要指定--path.data参数,否则在运行的过程会出错
logstash -e 'input { stdin { } } output { stdout {} }' --path.data=/root/运行之后,我们在控制台输入hello world,即会出现以下结果
基于Logstash对Elasticsearch索引库中数据的导入和导出
应用需求:在192.168.220.201主机中的es中并没有info索引库,而192.168.220.202中的es有info索引库,此时我们可以尝试借助logstash来先将skuinfo索引库从192.168.220.202导出成一个json文件,然后将该文件借助logstash导入到192.168.220.201的es索引库中。
使用logstash将es数据从索引库中导出
创建一个临时的文件夹,用于保存导出的数据以及配置文件
mkdir /resources/mydata/logstash_temp使用vim来创建一个export.conf配置文件,并对其进行配置
vim export.confexport.conf文件内容如下
# 将192.168.220.202 Elasticsearch中info索引库导出为一个info.json文件
input{
elasticsearch {
hosts => ["192.168.220.202:9200"] # 指定Elasticsearch的地址,该地址中含有目标数据
index => "info" # 指定需要导出的索引库
size => 200 # 指定每次导出数据每批次的大小,注意不能设置太大,否则会出错
scroll => "5m"
docinfo => false
}
}
output{
file {
path => "skuinfo.json" # 指定保存的数据路径和json文件的名称
}
}使用docker cp命令将该导出的配置文件复制的logstash容器的bin目录中
# 将export.conf文件cp到logstash容器中
docker cp ./export.conf logstash:/usr/share/logstash/bin进入logstash容器,并执行配置文件
# 进入logstash,然后执行配置文件
docker exec -it logstash /bin/bash
cd /usr/share/logstash/bin
./logstash -f ./export.conf --path.data=/root/ # 务必要指定path.data属性,不然会报错执行完成之后便会在当前目录下产生一个info.json文件,将该数据文件导出到centos中
# 执行完成之后就会在当前目录下产生一个info.json文件,将该文件导出到centos中
docker cp logstash:/usr/share/logstash/bin/info.json /resources/mydata/即可完成将索引库中的数据导出成一个json文件,该文件存在于/resources/mydata/info.json
logstash对Elasticsearch索引库中数据的导入
- 完成json数据的导入及conf文件的配置
# 1. 将192.168.220.202中的info.json文件使用xftp工具导入到windows本地
# 2. 将该文件通过xftp工具导入到192.168.220.201 /resources/mydata/logstash_temp中
cd /mydata/mysources/logstash_temp
# 使用vim对import.conf进行配置
vim import.conf- import.conf的配置文件如下
# 读取json文件
input {
file {
# 设置json文件路径,多个文件路径可设置成数组[],模糊匹配用*
path => "/root/skuinfo.json"
start_position => "beginning"
# 设置编码
codec => json {charset => "UTF-8"}
# 当存在多个文件的时候可使用type指定输入输出路径
type => "json_index"
}
}
# 过滤格式化数据
filter {
mutate{
#删除无效的字段
remove_field => ["@version","message","host","path"]
}
# 新增timestamp字段,将@timestamp时间增加8小时
ruby { code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)" }
}
# 数据输出到ES
output {
#日志输出格式,json_lines;rubydebug等
stdout {
codec => rubydebug
}
#输出到es
if[type] == "json_index"{
#无法解析的json不记录到elasticsearch中
if "_jsonparsefailure" not in [tags] {
elasticsearch {
#es地址ip端口
hosts => "192.168.220.201:9200"
# 配置数据转入到es中的
index => "info"
#类型
document_type => "skuinfo"
}
}
}
}- 完成import.conf文件的配置之后,我们即可来真正实现数据导入
# 将import.conf文件和info.json文件导入到logstash容器中
docker cp ./import.conf logstash:/usr/share/logstash/bin # 导入conf配置文件
docker cp ./skuinfo.json logstash:/root/ # 导入json数据文件,导入的路径注意与conf配置文件中的配置路径保持一致
# 进入到logstash容器中,并执行logstash命令完成数据的导入
docker exec -it logstash /bin/bash
cd /usr/share/logstash/bin
./logstash -f ./import.conf --path.data=/root/等待执行完成之后访问192.168.220.201:5601即可访问到info索引库中的数据
安装ik中文分词器
ik中文分词器插件的安装
坑一:我们安装ik分词器的时候,一般是在github中来下载zip文件,然后传送到centos中,最后再上传到elasticserch容器中,但是github中标明的版本与实际版本根本不相同。另一方面,在我们下载不同版本的elasticsearch时,有的版本容器运行会出错,有些正常。所以我们以后我们搭建elk的时候就同一安装5.6.8版本(一定要注意)
坑二:我们一般在github上下载zip文件(无论什么文件)的时候会非常非常的慢(不是一般的慢),所以我们以后在使用github来下载的时候可以借助gitee(码云)来下载,在码云中创建一个仓库的时候,选择导入已有的仓库,然后将原github的git连接复制粘贴上去,最后create。一旦创建,我们就可以借助码云中来间接下载github仓库的任何文件,且下载的速度会大大加快
ik分词器链接:https://gitee.com/tianxingjian123/elasticsearch-analysis-ik
# ik分词器链接:https://gitee.com/tianxingjian123/elasticsearch-analysis-ik
# 下载5.6.8的ik分词器之后,我们需要使用maven将其打包
cd C:UsersMDesktopcode-demoelasticsearch-analysis-ik
mvn package -Pdist,native -DskipTests -Dtar
# 使用maven打包完成之后,即可生成一个target文件夹,里面有./releases/elasticsearch-analysis-ik-5.6.8.zip
# 在虚拟机中创建一个ik文件夹
mkdir ik
# 之后使用xftp将该zip文件上传到ik文件夹中,然后使用unzip命令解压该zip文件,解压之后删除zip文件
unzip elasticsearch-analysis-ik-5.6.8.zip
rm -rf elasticsearch-analysis-ik-5.6.8.zip
# 之后使用docker将该ik文件夹传到elasticsearch容器的plugins中
docker cp ./ik elasticsearch:/usr/share/elasticsearch/plugins
# 进入elasticsearch容器
docker exec -it new-elasticsearch /bin/bash
# 之后如下命令可查看是否成功上传ik文件夹
root@78f36ce60b3f:/usr/share/elasticsearch# cd plugins/
root@78f36ce60b3f:/usr/share/elasticsearch/plugins# ls
ik
root@78f36ce60b3f:/usr/share/elasticsearch/plugins# cd ik
root@78f36ce60b3f:/usr/share/elasticsearch/plugins/ik# ls
commons-codec-1.9.jar httpclient-4.5.2.jar
commons-logging-1.2.jar httpcore-4.4.4.jar
config plugin-descriptor.properties
elasticsearch-analysis-ik-5.6.8.jar
root@78f36ce60b3f:/usr/share/elasticsearch/plugins/ik#
# 之后进入到bin目录下,并查看已经安装的ik分词器插件
root@78f36ce60b3f:cd /usr/share/elasticsearch/bin
root@78f36ce60b3f:/usr/share/elasticsearch/bin# elasticsearch-plugin list
ik以上操作完成之后,就算是完成了在Elasticsearch中引入ik中文分词器插件了,注意:以上步骤务必需要完全一致,否则会造成各种问题。
分词结果测试
# 打开chrom浏览器,访问:http://192.168.220.201:5601/,若出现kibana界面,说明kibana安装正常
# 进入kibana的Dev Tools界面,然后使用如下测试ik中文分词器插件是否正常安装
GET bank/_analyze
{
"text": "现在是大年三十凌晨一点三十分,有点冷,我写完这篇文章就睡觉!",
"analyzer": "ik_smart"
}运行之后,测试ik中文分词结果如下,可见已经完成了对中文句子的分词
Elasticsearch集群的搭建
创建集群所需要的配置文件及数据文件,以便容器的映射
mkdir /mydata
cd /mydata
mkdir elasticsearch1
cd elasticsearch1
mkdir data # 注意要确保data目录下为空,否则在实际运行过程中会出错
mkdir config
cd conf
vim elasticsearch.yml
# elasticsearch.yml文件配置信息如下elasticsearch.yml文件的配置信息:
# 开启跨域,为了让es-head可以访问,此处需要额外安装header插件
http.cors.enabled: true
http.cors.allow-origin: "*"
# 集群的名称(一样)
cluster.name: elasticsearch
# 节点的名称(不一样,根据别名来配置)
node.name: es1
# 指定该节点是否有资格被选举成为master节点,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master
node.master: true
# 允许该节点存储数据(默认开启)
node.data: true
# 允许任何ip访问
network.host: 0.0.0.0
# 通过这个ip列表进行节点发现,我这里配置的是各个容器的ip
discovery.zen.ping.unicast.hosts: ["192.168.220.200:9300","192.168.220.200:9301","192.168.220.200:9302"]
#如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 – 导致脑裂 - 这将导致数据丢失
discovery.zen.minimum_master_nodes: 2第一个elasticsearch配置文件创建好后,同理创建其他两个节点
# 配置es2
cd /mydata
cp -r ./elasticsearch1 ./elasticsearch2
# 将其中的conf/elasticsearch.yml中配置修改一处信息
node.name=es2
# 配置es3
cd /mydata
cp -r ./elasticsearch1 ./elasticsearch3
# 将其中的conf/elasticsearch.yml中配置修改一处信息
node.name=es3创建elasticsearch容器并启动
# 创建es1容器并启动
docker run --name es1 -p 9200:9200 -p 9300:9300
-e ES_JAVA_OPTS="-Xms256m -Xmx256m"
-v /mydata/elasticsearch1/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /mydata/elasticsearch1/data:/usr/share/elasticsearch/data -d elasticsearch:5.6.8
# 引入ik分词器
docker cp ./ik es1:/usr/share/elasticsearch/plugins
# 创建es2容器并启动
docker run --name es2 -p 9201:9200 -p 9301:9300
-e ES_JAVA_OPTS="-Xms256m -Xmx256m"
-v /mydata/elasticsearch2/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /mydata/elasticsearch2/data:/usr/share/elasticsearch/data -d elasticsearch:5.6.8
# 创建es3容器并启动
docker run --name es3 -p 9202:9200 -p 9302:9300
-e ES_JAVA_OPTS="-Xms256m -Xmx256m"
-v /mydata/elasticsearch3/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /mydata/elasticsearch3/data:/usr/share/elasticsearch/data -d elasticsearch:5.6.8至此,完成以上操作即可实现了Elasticsearch集群的搭建
- 分别访问
http://192.168.220.200:9200、http://192.168.220.200:9201、http://192.168.220.200:9202,即可发现已经搭建完成,并显示了各个es节点的对应信息。 - 访问
http://192.168.220.200:9200/_cat/nodes可查看集群节点。 - 访问
http://192.168.220.200:9200//_cat/health查看健康状况(green,yellow、red)
所遇问题
- 实例化容器之后,可能会受到进程数的限制,我们需要提高虚拟机的进程数
vim /etc/sysctl.conf
# 添加如下一条配置
vm.max_map_count=655360
# 退出后重启配置
sysctl -p- 当实例化以上三个es容器之后,可能会存在一定的内存问题,这个时候,我们需要提高虚拟机的内存
# 实例化以上三个es容器之后,查看当前可用内存
free -m
# 运行以上命令之后,可能会发现当前可用配置只有50多,而且当我们访问http://192.168.220.200:9200的时候也会发现请求失败这个时候我们打开对应虚拟机的设置,将内存设置3GB即可,不一会儿重新进入虚拟机,使用free -m命令即可发现此时内存还剩1000多可用
# 完成上述配置之后,我们重启三个es容器
docker restart es1 es2 es3 || docker start es1 es2 es3
# 等待容器重启之后,使用chrom浏览器访问es
http://192.168.220.200:9200
http://192.168.220.200:9201
http://192.168.220.200:9202
# 可发现已经搭建完成,且显示了各个es节点的对应信息
# 在kibana的dev tools下查看集群节点
GET /_cat/nodes
# 查看健康状况(green,yellow、red)
GET /_cat/health





 京公网安备 11010802041100号
京公网安备 11010802041100号