前段时间浪尖推荐过一套奈学的pulsar课程,很多粉丝问浪尖pulsar到底值不值得学习,会不会替代kafka。浪尖个人2018年的时候就接触了pulsar,而且贡献了一点点代码到社区里,解决了一个和flink整合的bug。今天是整理一篇文章来简单介绍下pulsar。
1. pulsar的架构
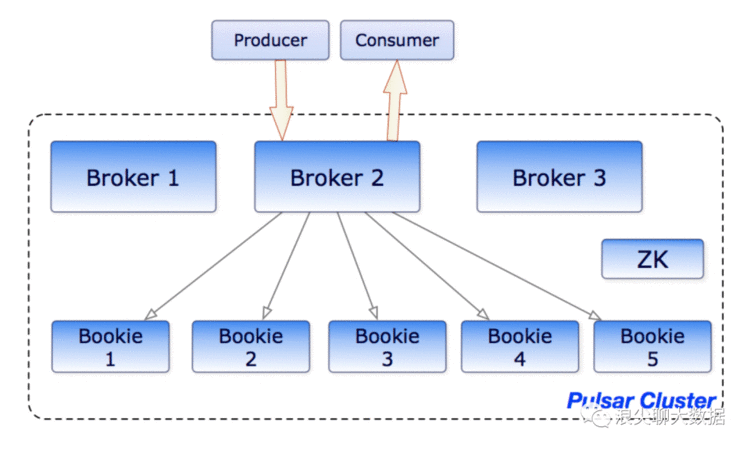
首先,我们先看下pulsar官网给出的pulsar架构,如下图:

从架构图中,pulsar集群主要四大模块:
1)一个或者多个broker节点。
broker负责处理和负载均衡从producer接收到的消息。
broker也负责分发消息给consumer。
broker也负责和pulsar的配置存储同步,以应对多变的协调任务。
broker负责将消息存储到BookKeeper集群中。
broker也依赖zookeeper集群,负责元数据存储,集群配置,协调任务。
broker是无状态的,跟kafka的broker不同之处就是broker本书不会负责数据存储,数据存储是交给了BookKeeper。
等等
2)BookKeeper集群。
消息队列本身理论上讲不需要持久化消息,它只需要完成消息的接收和投递,但是理想的消费者机会可以认为不存在。
pulsar支持临时消息存储的。
消息持久化投递-衍生出来的目的就是为了保证那些未确认送达的消息被再次消费处理的需求。
Pulsar用BookKeeper来做持久化层,这种计算存储-分离的系统还有很多,比如JanusGraph,nebula等。BookKeeper是一个分布式的预写日志(wal)系统。
BookKeeper以下几个特性,比较适合Pulsar的应用场景:
能让Pulsar创建多个独立的日志,这种独立的日志就是ledgers. 随着时间的推移,Pulsar会为Topic创建多个ledgers。
为按条目复制的顺序数据提供了非常高效的存储。
保证了多系统挂掉时ledgers的读取一致性。
提供不同的Bookies之间均匀的IO分布的特性。
容量和吞吐量都能水平扩展。并且容量可以通过在集群内添加更多的Bookies立刻提升。
Bookies被设计成可以承载数千的并发读写的ledgers。使用多个磁盘设备,一个用于日志,另一个用于一般存储,这样Bookies可以将读操作的影响和对于写操作的延迟分隔开。
除了消息数据,cursors也会被持久化入BookKeeper。Cursors是消费端订阅消费的位置。BookKeeper让Pulsar可以用一种可扩展的方式存储消费位置。
brokers和bookies是交互过程如下:
着重介绍下ledger
ledger是一个只追加的数据结构,并且只有一个写入器,这个写入器负责多个BookKeeper存储节点(就是Bookies)的写入。ledger的条目会被复制到多个bookies。Ledgers本身有着非常简单的语义:
Pulsar Broker可以创建ledeger,添加内容到ledger和关闭ledger。
当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,这个ledger只会以只读模式打开。
最后,当ledger中的条目不再有用的时候,整个legder可以被删除(ledger分布是跨Bookies的)。
读一致性。由于ledger只能被一个进程(也就是写入器进程)写入,这样这个进程就不会在写入时不会有冲突,从而保证了写入的高效。在一次故障之后,ledger会启动一个恢复进程来确定ledger的最终状态并确认提交到日志的是哪一个条。这就保证了所有ledger读进程读取到相同的内容。
Managed ledgers 。
由于BookKeeper提供了单一的日志抽象,在ledger的基础上pulsar提供了一个叫做managed ledger的库,用于表示单个topic的存储层。managed ledger即消息流的抽象,有一个写入器进程不断在流结尾添加消息,并且有多个cursors消费这个流,每个cursor有自己的消费位置。
一个managed ledger在内部用多个BookKeeper ledgers保存数据,这么做有两个原因:
3)zookeeper集群
pulsar主要依赖zookeeper做它擅长的,元数据存储,集群配置和一些协调任务。由于BookKeeper也需要zookeeper,所以企业中这两个zookeeper在负载不是很大的情况下,也可以共享的。
唠唠Zookeeper的观察者
对于pulsar实例:
4)client模块
Pulsar 通过“订阅”,抽象出了统一的: producer-topic-subscription-consumer 消费模型。Pulsar 的消息模型既支持队列模型,也支持流模型。
生产者没啥好介绍的,重点介绍一下,消费者的订阅模式。pulsar也有topic的概念,每个topic对应着BookKeeper中的一个分布式日志。生产者发送消息到指定topic,然后bookKeeper会讲消息存储到多个节点上。topic的消息可以被反复订阅。
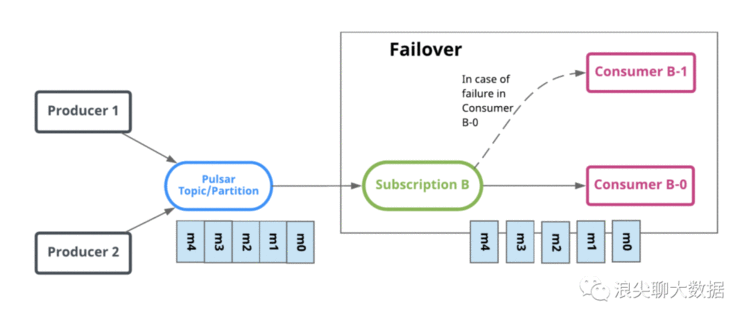
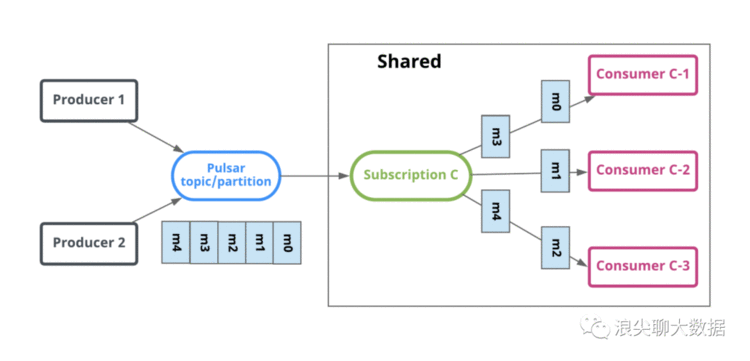
跟kafka一样,一个topic可以被多个消费者组消费,不同的是pulsar的每个消费者组可以拥有自己不同的消费方式:独占(Exclusive),故障切换(Failover)或共享(Share)。
2. pulsar vs kafka
对于很多粉丝关心的pulsar使用的优点,浪尖也不准备特别细致的介绍,这里主要从故障转移和扩容两个生产痛点介绍下。
a)broker故障
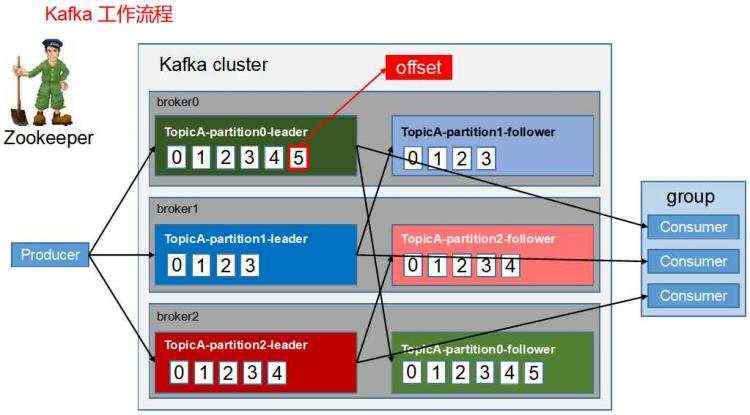
broker故障导致该节点所存储的分区不可用,这个在生产中常见的问题对于kafka来说是相当棘手。在isr列表不为空的情况下,还是能完成分区leader的切换的。但是还要完成副本增加的数据同步的过程,同时邀请ack大于1,才能保证数据不丢失。
pulsar的broker故障,由于broker无状态的(broker只是个代理,存储由BookKeeper负责),所以只牵涉到所有权被其他broker接管的问题。因为它不需要重新复制数据,所以所有权转移立即发生而不会牺牲主题分区的可用性。
b)扩容
kafka集群容量受限于做弱的机器最小的磁盘,当然这种不均衡很少发生,企业中kafka的机器配置往往最硬的。
kafka扩容感觉管理过kafka的朋友都应该体会过其复杂,扩容难点:
1)主要在于增加机器之后,数据需要rebalance到新增的空闲节点,即把partitions迁移到空闲机器上。kafka提供了bin/kafka-reassign-partitions.sh工具,完成parttition的迁移。
2)kafka的集群的数据量加大,数据rebalance的时间较长。
成长型的企业,这点确实会让kafka集群运维管理大佬深恶痛绝。
但是pulsar扩容就相当简单了,broker可以根据需要无影响扩容,存储只需要对BookKeeper集群扩容即可,无需人工去迁移数据,不干扰线上应用。
单就扩容这点,pulsar完虐kafka,pulsar甚至可以存储全量数据。










 京公网安备 11010802041100号
京公网安备 11010802041100号