一文概览用于图像分割的CNN 论智调调参,论论AI【公众号:论智(jqr_AI)】作者:MOHITJAIN编译:Bot在计算机视觉领域,图像分割指的是为图像中的每个像素分配一个标
一文概览用于图像分割的CNN 作者:MOHIT JAIN
编译:Bot
在计算机视觉领域,图像分割指的是为图像中的每个像素分配一个标签的任务,它也可以被看作是dense prediction task,对图像中每个像素进行分类。和使用矩形候选框的目标检测不同,图像分割需要精确到像素级位置,因此它在医学分析、卫星图像物体检测、虹膜识别和自动驾驶汽车等任务中起着非常重要的作用。
随着深度学习的不断发展,近年来图像分割技术也在速度和准确率上迎来了一次次突破。现在,我们能在几分之一秒内完成分割,同时保证极高的准确性。在这篇文章中,我们将介绍一些用于图像分割的主要技术及其背后的简单思路。我们将从最基础的语义分割(semantic segmentation)开始,慢慢进阶到更复杂的实例分割(instance segmentation)。
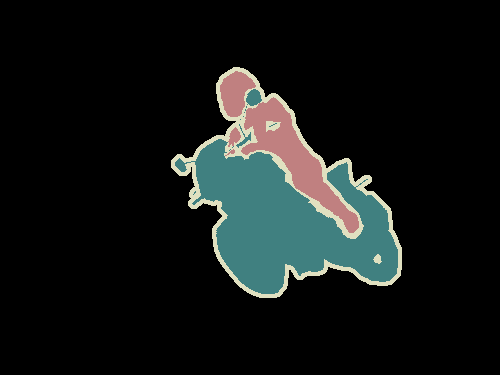
目标检测、语义分割和实例分割
语义分割 语义图像分割是为图像中的每个像素分配语义类别标签的任务,它不分割对象实例。现在,处理这类任务的主流方法是FCN及其衍生,所以我们先从FCN看起。
全卷积网络(FCN) FCN架构
创建FCN的方法很简单,我们只需把CNN里的所有全连接层替换成宽高1×1的卷积层,这时卷积层的filter数量等于全连接层的神经元(输出)数量 ,所有层都是卷积层,故称全卷积网络。之所以要这么做,是因为每个像素的空间位置对于分割来说都很重要,而卷积层能分类全连接层无法处理的单个像素。作为处理结果,神经网络较高层中的位置会对应于它们路径连接的图像中的位置,即它们的感受野。
如上图所示,FCN的架构非常简单,主要由编码器CNN(以VGG为例)构成,只不过其中和分类网络对应的最后三层被改成了(4096,1,1)(4096,1,1)(N+1,1,1)的卷积层 (N表示类别数量)。编码器后是一个解码器网络,它只包含一个反向的卷积层(也称为转置卷积transposed convolution或反卷积deconvolution)。它的输出与输入图像具有相同的空间维度,并具有N+1个通道,每个通道预测一个类别。
反向的卷积操作
仍以VGG为例,由于前面采样部分过大,有时候会导致后面进行反向卷积操作得到的结果分辨率较低,会出现细节丢失等问题。为此,FCN的解决方法是叠加第三、四、五层池化层的特征 ,以生成更精准的边界分割。如下图所示:
需要注意的一点是,在进行上采样之前,所有池化特征都会先通过(N+1,1,1)这个卷积层。
FCN分割效果
U-NET U-NET架构
U-NET常被用于生物医学图像分割,它遵循了FCN的编码器-解码器结构,不使用任何全连接层。如上图所示,常规情况下,U-NET的编码器是一个包含10个卷积层的CNN,中间包含最大池化层(红色箭头)。它的解码器会对feature map进行多次上采样和卷积,目的是为了提取更高效、更抽象的特征。得到heatmap后,U-NET最后再用1×1的卷积层做分类,也就是说解码器一共有13层,整个架构总共由23层可学习的卷积层组成。
为什么要做上采样?直接复制过来再裁剪到与上采样图片一样大小 ),这就相当于在高分辨率和更抽象特征当中做一个折衷,因为随着卷积次数增多,提取的特征也更加有效,更加抽象。—— jianyuchen23 SEGNET SegNet架构
SegNet的全称是“用于图像分割的深度卷积编码器-解码器架构”,事实上,大多数语义分割方法都遵循这种基本架构,它们的编码器都是用VGG16,解码器都仿照U-NET——多次上采样后再卷积。但是,SegNet有自己独到的特点:
上采样是不可学习的 解码器使用和编码器相同的卷积(filter大小和相应层的通道数量) SegNet中的上采样是一种反向最大池化操作 。为了补足图像信息,U-NET会对编码阶段的特征做通道降维,再把它和特征反向卷积后得到上采样进行相加,这一过程需要学习。而SegNet采用的方法是记录下编码阶段的最大池化index,比如在某层移动2×2的最大池化窗口时最高值像素的位置,然后把这个index用于解码阶段的上采样。空白的值用0填充:
SegNet上采样
在这个稀疏feature map进行正常卷积后,我们就能得到密集feature map。因此相比较FCN,SegNet的内存利用率更高,计算效率也更高。
需要注意的是,一般来说,解码器每一层的输入通道数和feature map大小都与其对应的编码器相同,但第一层不是。编码器的第一层都3个输入通道(RGB),但解码器第一层有更多通道,这是为了给每个类别生成分割掩膜。
用SegNet进行道路场景分割
实例分割 所谓实例分割,指的就是结合了语义分割和分类的任务。它在本质上更复杂,因为为了区分同一类的不同实例,我们往往需要为每个独立对象创建单独的、缩小的掩膜,然后再把它的大小调整为输入图像中对象的大小。
下面是实例分割的一些常用方法。
DEEPMASK DeepMask架构
DeepMask是FAIR于2015年提出的一种实例分割方法,输入一张图片后,它能为子图像块(image patch)中的对象生成56×56的分割掩膜,并以掩膜为中心进行分类。对于图像的子图像块,它有两个约束:
子图像块中必须包含一个大致居中的对象 这个对象必须被完整包含在子图像块中,且在给定的比例范围内 由于DeepMask一次只能为子图像块分割一个对象,当它处理包含复杂、重复对象的图像时,它会在多个位置以多个比例密集应用。鉴于以上两个约束条件,这是可以理解的,也是必要的。
整个模型由VGG-A构成,它保留了两个全连接层,但删去了最后一个最大池化层,共有8个卷积层和4个池化层。模型输出的下采样因子为16,共有2个输出,一是子图像块对应物体的一个掩膜,二是这个子图像块包含一个物体的得分。
DeepMask分割效果
Multi-task Network Cascades(MNC) MNC架构,右上为简化原理图
MNC不直接进行实例分割,它把这个任务分成了三个更小、更简单的子任务:
区分实例。这个子任务的目标是为每个实例预测候选框和候选框是否包含对象的概率; 估计掩膜。这个子任务的目标是预测对象的像素级掩膜; 对对象进行分类。这个子任务的目标是为每个掩膜级实例预测类别标签。 这三个子任务不是并行执行的,它们要按照顺序一个个完成,这也是MNC的全称“多任务网络级联”的原因。模型用移除了所有全连接层的VGG-16处理输入图像,生成feature map,作为三个子任务的共用数据。
子任务1:预测实例候选框
首先,神经网络以窗口的形式提取对象实例,这些候选框不包含分类预测信息,但有一个包含/不包含对象的概率。这是个全卷积的子网络,结构类似RPN。
子任务2:估计实例掩膜
基于子任务1返回的候选框预测,模型再用ROI pooling从共享卷积特征中提取该候选框的特征,之后是两个全连接层(fc),第一个fc负责把维度降到256, 第二个fc负责回归像素级的掩膜。掩膜的预定义分辨率是M×M,这和DeepMask中使用的预测方法有些类似,但不同的是MNC只从几个候选框中回归掩膜,计算成本大大降低。
子任务3:对实例进行分类
现在模型有了子任务1给出的候选框预测,也有了子任务2用ROI pooling提取的feature map,之后就是基于掩膜和候选框预测实例类别。
这是两条并行路径。在基于掩膜的路径中,ROI提取的feature map被子任务2预测的掩膜“覆盖”,使模型更关注预测掩膜的前景特征,计算乘积后,将特征输入两路4096维的fc层。在基于候选框的路径中,用ROI pooling提取的特征被直接传递到4096维的fc层(图中未画出),目的是为了解决特征大幅被掩模级通道“覆盖”的情况(如目标对象很大)。之后,基于掩膜和基于候选框的路径被连接起来,紧接着是N+1类的Softmax分类器,其中N类是物体,1类是背景。
MNC分割效果
即便是这么复杂的架构,整个网络也是可以端到端训练的。
INSTANCEFCN InstanceFCN是FCN的改进版,它不仅在语义分割任务上表现出色,在实例分割上也有不错的结果。之前我们提到过,FCN的每个输出像素是一个类别的分类器,那么InstanceFCN的每个输出像素就是实例相对位置的分类器。例如,下图被分为9块区域,在其中的第6个得分图中,每个像素就是对象是否在实例右侧的分类器。
试想一下,如果图像中只有一个实例,分割过程会很简单;如果有多个重叠实例,那么我们就得先区分实例,然后再进行分割。相比FCN,InstanceFCN的最大改进是引入相对位置,它在输入图像上生成k2实例敏感分数图,每个分数图对应于特定的相对位置,这就实现了相同位置不同语义的预测。
为了从这些分数图上生成图像实例,InstanceFCN在这组分数图上用了一个m×m的滑动窗口。在这个滑动窗中,每一个m/k×m/k的子窗口直接从相应的分数图中同样的子窗口复制那一部分数值。之后这组子窗口按照相对位置拼起来就得到了m×m的结果。这一部分被称为实例组合模块(instance assembling module)。
模型的架构包括在输入图像上用VGG-16做特征提取。在输出的feature map顶部,有两个全卷积分支:一个用来估计分割实例(如上所述),另一个用来对实例进行评分。
InstanceFCN架构
如上图所示,对于第一个分支,模型先采用一个512维的1×1卷积层转换特征,然后用3x3的卷积层生成一组k2实例敏感分数图。这个实例组合模块负责在分辨率为m×m(m=21)的滑动窗中预测分割掩膜。
对于第二个分支,模型先采用一个512维的3×3卷积层,后面跟随一个1x1的卷积层。这个1x1的卷积层是逐像素的逻辑回归,用于分类以像素为中心的m×m滑动窗口中的对象是/不是实例。因此,这个分支的输出是对象分数图,其中一个分数对应于生成一个实例的一个滑动窗口,所以它对不同的对象类别会“视而不见”。
InstanceFCN分割效果
FCIS 正如InstanceFCN是对FCN的改进,完全卷积实例感知语义分割(FCIS)也是在InstanceFCN基础上做出的进一步优化。上节我们说道,InstanceFCN预测分割掩膜的分辨率都是m×m,而且没法将对象分类为不同类别。FCIS解决了这两个问题,它既能预测不同分辨率的掩膜,也能预测不同的对象类别。
FCIS实例敏感分数图
给定ROI,首先用InstanceFCN的实例组合模块生成上述分数图。对于ROI中的每个像素,有两个任务(所以要生成两个分数图):
检测:它是否在某相对位置的对象检测候选框内,是(detection+),否(detection-) 分割:它是否在对象实例的边界内,是(segmentation+),否(segmentation-) 基于上述任务,这时出现了三种情况:
内部得分高,外部得分低:detection+,segmentation+(像素点位于ROI中的目标部分) 内部得分低,外部得分高:detection+,segmentation-(像素点位于ROI中的背景部分) 两个得分都很低:detection-,segmentation-(像素点不在ROI中) 对于检测,我们可以用取最大值把前两种情况(detection+)和情况3(detection-)区分开。整个ROI的得分是求取最大值得到分数图的所有值的平均数,之后再通过一个softmax分类器。对于分割,softmax可以区分情况1(segmentation+)和其他情况(segmentation-)。ROI的前景掩膜是每个类别每个像素分割分数的合并。
FCIS架构
FCIS分割效果
MASK R-CNN MASK R-CNN是目标检测模型Faster R-CNN的进阶版,它在后者候选框提取的基础上添加了一个并行的分支网络,用预测分割掩膜。这个分支网络是个共享feature map的FCN,它为每个ROI提供Km2 维的输出,其中K对应类别个数,即输出K个掩膜,m对应池化分辨率。这样的设计允许网络为每个类别生成掩膜,避免了不同类实例之间因重叠产生混淆。此外,分类分支是直接在掩膜上分类,所以分割和分类是分离的。
Mask R-CNN架构中用于预测掩膜的分支
关注输入图像的空间结构是准确预测掩膜的前提,而这种像素到像素的操作需要ROI特征的完全对齐。在目标检测任务中,一些模型会用RoIPool提取这些特征,但它们不总是严格对齐的,因为ROI的维度不仅可以是积分,也可以是浮点数。RoIPool通过将它们四舍五入到最接近的整数来量化这些维度,不仅如此,量化的RoI还被进一步细分为量化的空间区间,在该区间上执行合并。虽然这些量化对分类问题没什么影响,但如果把它们用于像素级对齐,分割掩膜预测会出现巨大偏差。
RoIAlign: 虚线网格表示feature map,实线表示RoI(有2×2个bin,每个bin中4个采样点)
考虑到实例分割要求像素级别的精准,MASK R-CNN引入了一种新的方法来提取特征,称为RoIAlign。它背后的想法是很简单:既然错位是由量化引起的,那就避免所有量化。RoIAlign不会对维度做任何约减,它引入了一个插值过程,先通过双线性插值到14×14,再池化到7×7,很大程度上解决了由直接池化采样造成的Misalignment对齐问题。需要注意的是,使用RoIAlign提取的RoI特征具有固定的空间维度,这点和RoIPool一样。
小结 以上就是现在常用的语义分割、实例分割模型,它们基本上都是FCN的变体,把编码器作为简单的特征提取器,重点放在解码器创新上。此外,一些研究人员也尝试过用其他方法来解决实例分割问题,比如上面提到的MASK R-CNN就是改造目标检测模型的成果,总而言之,FCN还是解决这类任务的重要基石。
译者的话:以上只是简短的关键提炼,如果读者希望了解这些模型的具体细节,可以参考文末推荐的几篇中文论文解读,点击阅读原文获取超链接。
参考文献 [1] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. (paper)
[2] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in MICCAI, pp. 234–241, Springer, 2015. (paper)
[3] Badrinarayanan, V., Kendall, A., & Cipolla, R. (2017). SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39, 2481-2495. (paper)
[4] P. O. Pinheiro, R. Collobert, and P. Dollar. Learning to segment object candidates. In NIPS, 2015. (paper)
[5] Dai, J., He, K., Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In CVPR., 2016. (paper)
[6] J. Dai, K. He, Y. Li, S. Ren, and J. Sun. Instance-sensitive fully convolutional networks. In ECCV, 2016. (paper)
[7] Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei. Fully convolutional instance-aware semantic segmentation. In CVPR, 2017. (paper)
[8] K He, G Gkioxari, P Dollár, R Girshick. Mask R-CNN. In ICCV, 2017. (paper)
编译参考 [1] jianyuchen23——U-Net论文详解
[2] DelphiFan’s Blog——语义分割论文-SegNet
[3] Elaine_Bao——物体检测与分割系列 DeepMask
[4] AHU-WangXiao——Instance-aware Semantic Segmentation via Multi-task Network Cascades
[5] Tina’s Blog——InstanceFCN:Instance-sensitive Fully Convolutional Networks
[6] 技术挖掘者——Mask R-CNN详解
编辑于 2018-10-31
人工智能
计算机视觉
深度学习(Deep Learning)
文章被以下专栏收录 论智
AI新技术【公众号:论智】
关注专栏 推荐阅读 图像语义分割综述深度学习第35讲:图像语义分割经典论文研读之 u-net图像太大,显存放不下?来看看跑FCN网络的高效方法Ross、何恺明等人提出PointRend:渲染思路做图像分割,显著提升Mask R-CNN性能切换为时间排序
 目标检测、语义分割和实例分割
目标检测、语义分割和实例分割 FCN架构
FCN架构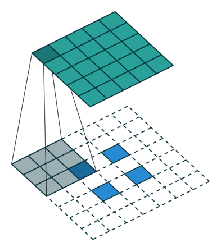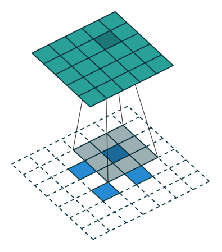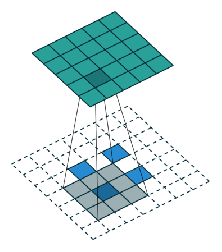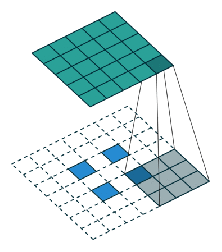

 FCN分割效果
FCN分割效果 U-NET架构
U-NET架构 SegNet架构
SegNet架构 SegNet上采样
SegNet上采样 用SegNet进行道路场景分割
用SegNet进行道路场景分割 DeepMask架构
DeepMask架构 DeepMask分割效果
DeepMask分割效果 MNC架构,右上为简化原理图
MNC架构,右上为简化原理图 MNC分割效果
MNC分割效果
 InstanceFCN架构
InstanceFCN架构 InstanceFCN分割效果
InstanceFCN分割效果 FCIS实例敏感分数图
FCIS实例敏感分数图 FCIS架构
FCIS架构 FCIS分割效果
FCIS分割效果 Mask R-CNN架构中用于预测掩膜的分支
Mask R-CNN架构中用于预测掩膜的分支 RoIAlign: 虚线网格表示feature map,实线表示RoI(有2×2个bin,每个bin中4个采样点)
RoIAlign: 虚线网格表示feature map,实线表示RoI(有2×2个bin,每个bin中4个采样点)










 京公网安备 11010802041100号
京公网安备 11010802041100号