不知大家是否已经留意到,在 TDengine 3.0 的官方文档(https://docs.taosdata.com/taos-sql/show/#)中,有了这样一个命令 :show transactions。顾名思义,这是“事务”。
在 Database 的语境中,满足 ACID 属性的数据库操作序列即可称为事务,它是数据库的一个不可拆分的工作单元,包含着一个数据库操作的序列,这些操作要么全部执行,要么全部不执行。换个角度也可以说,事务是为了实现 ACID 特性的一种工具。
不过在 TDengine 中,依托于“一个数据采集点一张表”的设计理念,针对表的操作都是以队列方式逐个进行的,所以在绝大多数情况下都不需要事务机制。那 TDengine 3.0 中的“事务”是用来解决什么问题的呢?答案就是:3.0 中的事务机制并没有应用在业务数据上,而是针对数据库的元数据的,它的目的是利用事务的 ACID 特性,来强化元数据的一致性,因此,普通用户对此是无感知的,但是对 TDengine 的运维人员而言,意义会更大一些。
大家都知道 TDengine 3.0 是一款高性能、云原生的分布式时序数据库(Time Series Database),甚至可以支持十亿级别的表数量,因此它的元数据量是十分庞大的。那么如果使用了事务,会不会影响 TDengine 的高性能呢?
这里就需要结合 TDengine 2.x 时代的元数据架构来说起了。
在 2.x 版本中,管理节点 mnode 中的 sdb 模块存储了大量元数据,如集群信息、用户信息、数据库信息、超级表信息以及普通表信息等。这些不同类型的信息,会在内存中分别以一个 hash 表的形式来维护。其中,一些元数据需要在管理节点(mnode)和数据节点(dnode/vnode)中分别存储,比如超级表、普通表。所以,当对数据库执行 DDL 操作时,需要在 mnode 上对这个 hash 表操作一次,还要再去 dnode 中的 vnode 也做一次。这里为了性能的优化,TDengine 选择以异步的方式来完成操作。以删表为例,当 mnode 内存中的 hash 表删掉了这个表后,会立即返回成功。后续由 dnode/vnode 一侧删除自己的元数据,达成最终一致。
因为该流程的非强一致性,可能会导致在某些极特殊情况下(比如网络不稳定),出现 mnode 与 vnode 元数据不同步的情况(有的用户遇到过这个错误信息:“Invalid table id”)。但是如果为了强一致性而在 2.x 中引入事务机制,那么对于存在超大规模 DDL 操作的场景来说(如删除一张拥有百万千万子表的超级表),这种分布式的事务对数据库的性能损耗又将非常之大。
那么应该如何解决这个问题呢?我们的思路是:利用“分布式事务”,解决 mnode 和 dnode 同步时的非原子性问题,但是又不能让其影响到数据库的性能。
以此为依据,TDengine 在 3.0 中选择把开销最大的普通表元数据从 mnode 中移除,完全只放在各个 vnode 中分布式存储,这样除了防止了上述 mnode 和 vnode 普通表元数据不一致的现象发生,更使得 TDengine 不再具有单点性能瓶颈,解决了业界的“高基数”难题,从而可以支持十亿级别的时间线。在其余的元数据模块中,我们则引入了事务机制,确保了这部分元数据的 ACID 特性。
下图是一个两阶段提交的流程,其中 Coordinator(协调者)就是 mnode,而 Participants(参与者) 就是 dnode/vnode。
创建事务后,协调者本地准备事务所需的必要数据,redo、undo 日志等。然后向参与者们发送事务执行请求,如果参与者们的事务执行结果皆为成功,那么则进入提交阶段,由协调者提交事务。
需要注意的是:如果作为协调者的 mnode 宕机,那么其他 mnode 在成为 leader 之后,会作为新的协调者继续驱动事务的执行。也就是说,Raft 协议保证了事务的一致性和持久性。
在现在的 3.0 架构中,为了避免不同的事务操作共享资源,管理节点针对不同类型的元数据把事务分成了几个级别,分别为无冲突级别、全局级别、数据库级别以及数据库内部级别。如果在内存中仍有未完成且具有相同冲突类型的事务,后执行的事务将会等待前者执行完毕再执行。
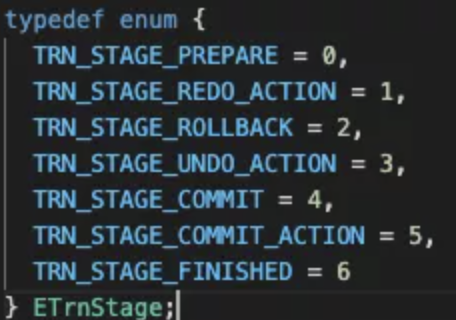
最终,一个事务的运行状态与行为是由该类元数据本身的冲突级别和失败策略等因素决定的,而这一切是对用户无感知的。用户只需知道事务在执行阶段具有 PREPARE,REDO_ACTION,COMMIT,COMMIT_ACTION,ROLLBACK,UNDO_ACTION,FINISHED 7 个阶段。
其中,比较关键的地方是:在 PREPARE 阶段,事务的基本信息在不同的 mnode 间达成一致;然后在 REDO_ACTION 阶段,执行 mnode 的本地操作、以及涉及的 vnode 的远端操作。当 REDO_ACTION 的所有操作都完成后,进入 COMMIT 阶段。注:REDO_ACTION 不止包含了第一次执行任务,还包括执行失败后的重做。COMMIT 阶段则负责把数据最终写入到 SDB 对应的表中,完成持久化。在最后的 FINISHED 阶段,清理 SDB 模块中事务表的相关内存,完成整个任务的执行或者回滚。
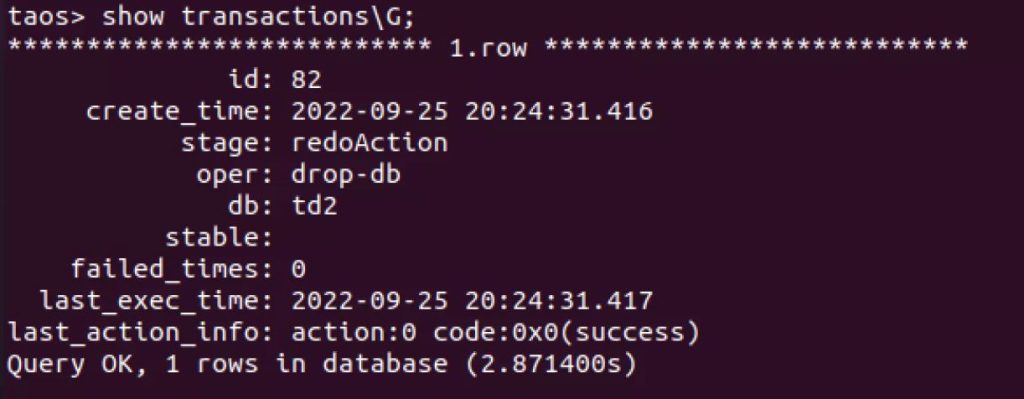
通过 show transactions,我们可以明确了解到当前事务运行的阶段。除了确保数据库的安全一致之外,也给了数据库运维人员更充足的信息去诊断数据库的当前状态。不过,在绝大多数时间,show transactions 的输出是没有结果的,因为元数据体量较小,所以执行速度都非常快。
总而言之,TDengine 3.0 的“事务”机制为集群信息、用户信息、数据库信息以及超级表信息等元数据带来了 ACID 的特性保障。
而在它背后的把普通表元数据完全迁移到 vnode 的架构变更,使得 TDengine 不再具有单点瓶颈,获得了超强的水平扩展能力,如果想获得更多的数据处理能力,只需要加入更多的数据节点即可。
在下一篇文章中,我会继续和大家分享该变更带来的诸多优势,一起感受 TDengine 这款开源、高性能、云原生的时序数据库的架构变化之路。
欢迎添加小T(VX:TDengine),加入物联网技术讨论群,第一时间了解TDengine 官方信息,与关注前沿技术的同学们共同探讨新技术、新玩法。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。













 京公网安备 11010802041100号
京公网安备 11010802041100号