前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
正文

为什么需要 window ?
对于流式处理,如果我们需要求取总和,平均值,或者最大值,最小值等,是做不到的,因为数据一直在源源不断的产生,即数据是没有边界的,所以没法求最大值,最小值,平均值等,所以为了一些数值统计的功能,我们必须指定时间段,对某一段时间的数据求取一些数据值是可以做到的。或者对某一些数据求取数据值也是可以做到的,所以,流上的聚合需要由 window 来划定范围,比如 “计算过去的5分钟” ,或者 “最后100个元素的和” 。
什么是 window ?
window是一种可以把无限数据切割为有限数据块的手段
窗口可以是 时间驱动的 【Time Window】(比如:每30秒)或者 数据驱动的【Count Window】 (比如:每100个元素)。

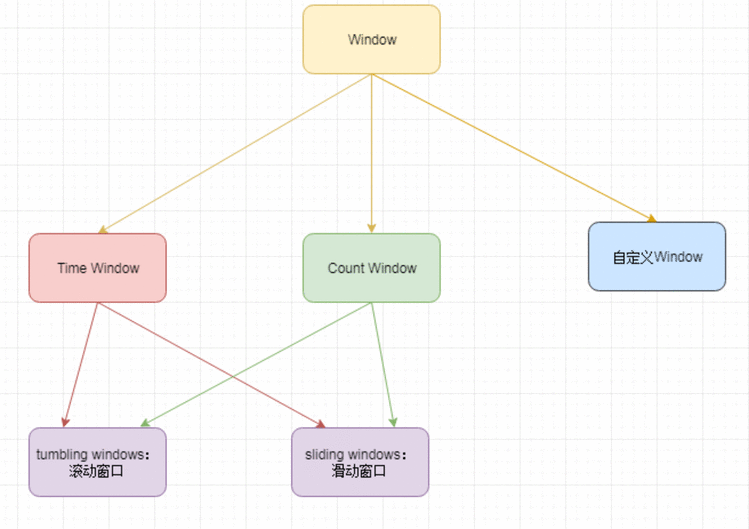
1、窗口的基本类型介绍
窗口通常被区分为不同的类型:
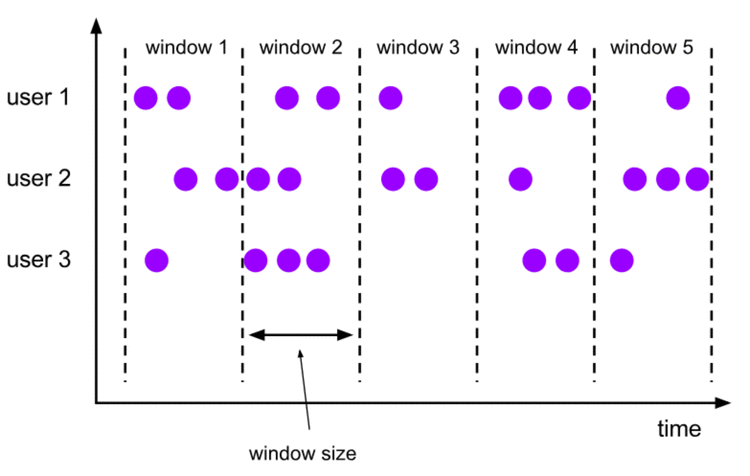
tumbling windows:滚动窗口 【没有重叠】
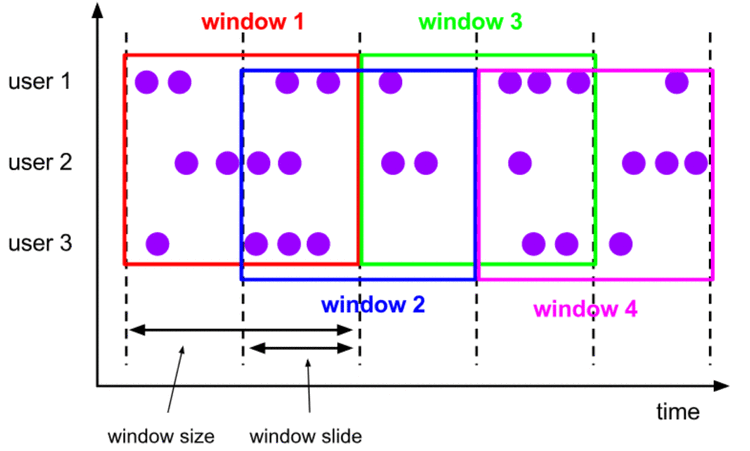
sliding windows:滑动窗口 【有重叠】
session windows:会话窗口 ,一般没人用
tumbling windows类型:没有重叠的窗口
sliding windows:滑动窗口 【有重叠】
2、Flink的窗口介绍
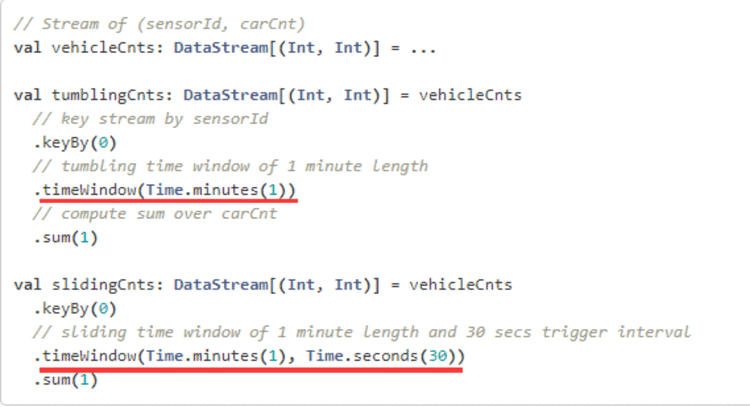
Time Window窗口的应用
time window又分为滚动窗口和滑动窗口,这两种窗口调用方法都是一样的,都是调用timeWindow这个方法,如果传入一个参数就是滚动窗口,如果传入两个参数就是滑动窗口
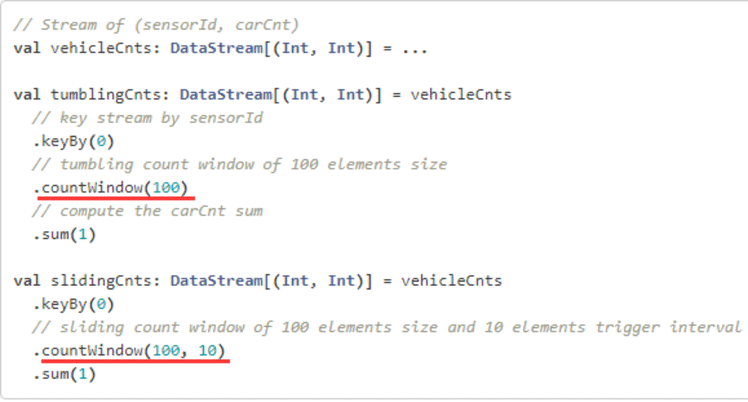
Count Windos窗口的应用
与timeWindow类型,CountWinodw也可以分为滚动窗口和滑动窗口,这两个窗口调用方法一样,都是调用countWindow,如果传入一个参数就是滚动窗口,如果传入两个参数就是滑动窗口
自定义window的应用
如果time window和 countWindow还不够用的话,我们还可以使用自定义window来实现数据的统计等功能。

3、window的数值聚合统计
对于某一个window内的数值统计,我们可以增量的聚合统计或者全量的聚合统计
实践
增量聚合统计:
窗口当中每加入一条数据,就进行一次统计
•reduce(reduceFunction)
•aggregate(aggregateFunction)
•sum(),min(),max()
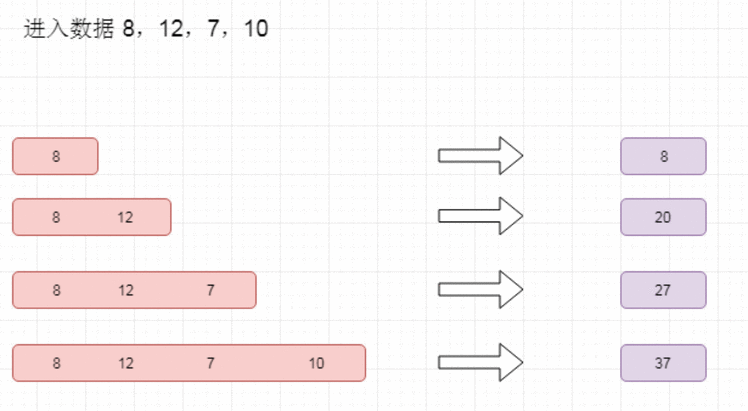
需求:通过接收socket当中输入的数据,统计每5秒钟数据的累计的值
代码实现:
package com.shockang.study.bigdata.flink.windowimport org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.datastream.DataStreamSink
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Timeobject FlinkTimeCount {def main(args: Array[String]): Unit = {val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.api.scala._val socketStream: DataStream[String] = environment.socketTextStream("node01", 9000)val print: DataStreamSink[(Int, Int)] = socketStream.map(x => (1, x.toInt)).keyBy(0).timeWindow(Time.seconds(5)).reduce(new ReduceFunction[(Int, Int)] {override def reduce(t: (Int, Int), t1: (Int, Int)): (Int, Int) = {(t._1, t._2 + t1._2)}}).print()environment.execute("startRunning")}
}
全量聚合统计:
等到窗口截止,或者窗口内的数据全部到齐,然后再进行统计,可以用于求窗口内的数据的最大值,或者最小值,平均值等
等属于窗口的数据到齐,才开始进行聚合计算【可以实现对窗口内的数据进行排序等需求】
apply(windowFunction)
process(processWindowFunction)
processWindowFunction比windowFunction提供了更多的上下文信息。
需求:通过全量聚合统计,求取每3条数据的平均值
package com.shockang.study.bigdata.flink.windowimport org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.datastream.DataStreamSink
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.util.Collectorobject FlinkCountWindowAvg {def main(args: Array[String]): Unit = {val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.api.scala._val socketStream: DataStream[String] = environment.socketTextStream("node01", 9000)val socketDatas: DataStreamSink[Double] = socketStream.map(x => (1, x.toInt)).keyBy(0).countWindow(3).process(new MyProcessWindowFunctionclass).print()environment.execute("count avg")}
}
class MyProcessWindowFunctionclass extends ProcessWindowFunction[(Int, Int), Double, Tuple, GlobalWindow] {override def process(key: Tuple, context: Context, elements: Iterable[(Int, Int)], out: Collector[Double]): Unit &#61; {var totalNum &#61; 0;var countNum &#61; 0;for (data <- elements) {totalNum &#43;&#61; 1countNum &#43;&#61; data._2}out.collect(countNum / totalNum)}
}








 京公网安备 11010802041100号
京公网安备 11010802041100号