
一、Lambda架构需求
Lambda架构背后的需求是由于MR架构的延迟问题。MR虽然实现了分布式、可扩展数据处理系统的目的,但是在处理数据时延迟比较严重。实际上如果内存和CPU足够强大,MR也可以实现近实时运算,但实际业务环境并非如此,因此我们需要权衡,选择实时处理和批处理所需要数据量和恰当的资源。2012年Storm的作者Nathan Marz提出的Lambda数据处理框架。Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
二、Lambda架构的关键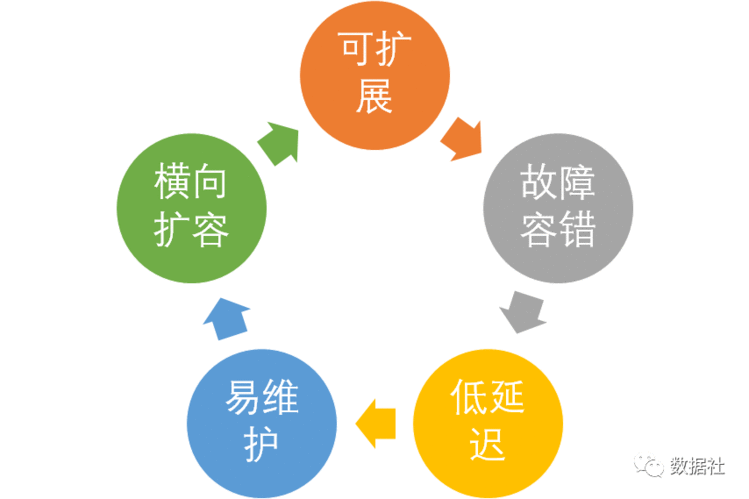
可扩展性意味着为满足日益增长的用户服务需求,同时不用对底层架构或者代码,可以通过现有机器添加内存或者磁盘资源来实现(垂直扩展),或者可以通过在集群中添加机器实现(水平扩展)。无论是实时或者批处理,都应该能够不停服务的情况下,可以实施水平扩展。
系统需要妥善处理故障,确保系统在某些组件发生故障的情况下,整个系统服务的可用性。可能部分组件故障会导致集群中部分节点宕机,影响了整理的SLA,但是系统还是可以相应的,系统不能有单点故障。
很多应用对于读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
系统需要足够灵活,能够实现新增和修改需求,又不需要重构整个系统。实时处理和批处理隔离开,能够灵活修改需求。
开发部署不能够太复杂。
三、Lambda架构的分层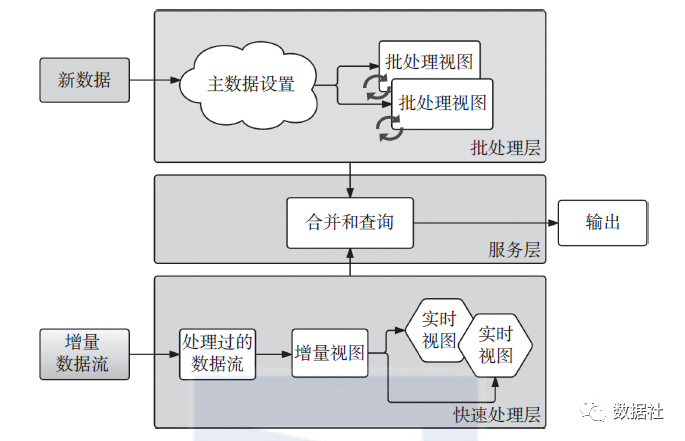
在Lambda架构中新数据到达时,会被同时分派到批处理层和快速处理层。一旦数据到达批处理层,按照常规批处理时间间隔,每次都从头开始重新计算并生成批处理视图。类似地,只要新数据到达快速处理层,快速处理层就会使用新数据生成快速视图。在查询到达服务层时,它会合并快速视图和批处理视图来生成适当的查询结果。生成批处理视图后,快速视图将被丢弃,除非有新数据抵达,否则只需要查询批处理视图,因为此时批处理层中拥有所有的数据。
Lambda架构定义主要层以及每个组件之间的集成。注意分为以下层:
数据源指外部的数据库、消息队列、文件等,可以开发数据消费层,隐藏来自不同访问数据的复杂性,定义好数据格式。
负责封装不能数据源获取数据的复杂性,将其转换可由批处理或者流处理进一步使用同一的格式进行消费。
这是Lambda架构核心层之一,批处理接受数据,持久化到用户定义好的数据结构中,维护着主数据。数据结构一般不做改变,只是追加数据。批处理还负责创建和维护批处理视图。比如我们常做的Hive ETL ,统计一些数据,最后将结果保存在hive表中,或者数据库中,就属于批处理层。
这是Lambda另一个核心层。批处理在很多场景下能够满足需求,但是随着业务需求“苛刻性”,他们希望能够及时看到数据,而不是等到第二天才看指标变化和分析结果。所以引入了实时处理。实时层解决了一个问题,即只存储可立即向用户提供的一组数据,这样就不需要对全量数据进行处理,大大提供处理效率。比如流处理仅仅存储最近5分钟的数据,处理计算并形成结果,这就是我们用spark streaming中要有的时间窗口。
这是Lambda架构的最后一层,服务层的职责是获取批处理和流处理的结果,向用户提供统一查询视图服务。
四、Lambda架构总结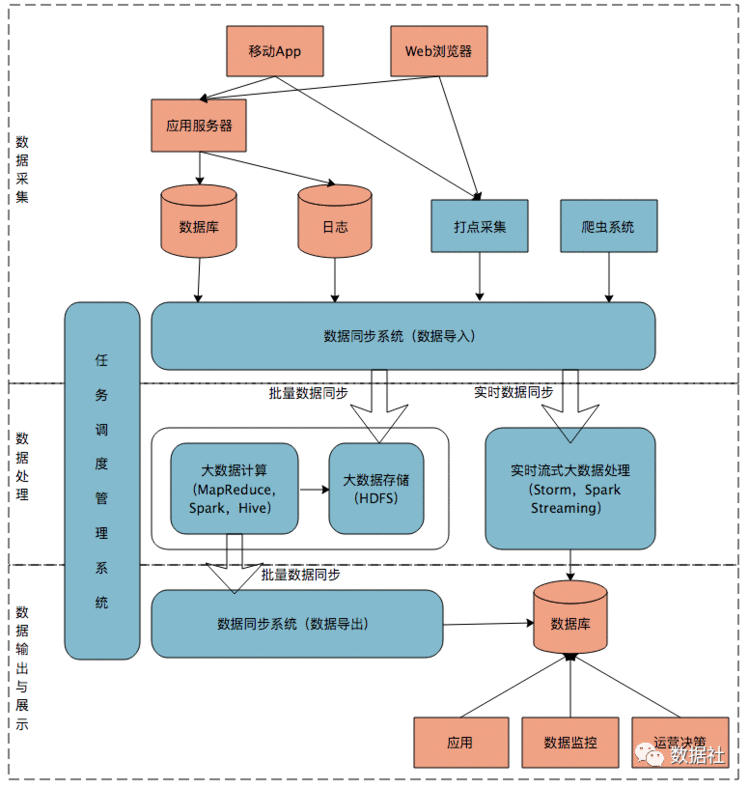
Lambda数据架构曾经成为每一个公司大数据平台必备的架构,它解决了一个公司大数据批量离线处理和实时数据处理的需求。
数据从底层的数据源开始,经过各种各样的格式进入大数据平台,在大数据平台中经过Kafka、Flume等数据组件进行收集,然后分成两条线进行计算。一条线是进入流式计算平台(例如 Storm、Flink或者Spark Streaming),去计算实时的一些指标;另一条线进入批量数据处理离线计算平台(例如Mapreduce、Hive,Spark SQL),去计算T+1的相关业务指标,这些指标需要隔日才能看见。
Lambda架构经历多年的发展,非常稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整体批量计算,这样把实时计算和离线计算高峰分开,这种架构支撑了数据行业的早期发展,但是它也有一些致命缺点:
因为批量和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
随着数据量级越来越大,经常发现夜间只有4、5个小时的时间窗口,已经无法完成白天20多个小时累计的数据,保证早上上班前准时出数据已成为每个大数据团队头疼的问题,同时做个任务并行执行对于大数据集群的稳定性也是巨大的考验,经常会有任务因为资源不足没有定时启动或者报错。
Lambda 架构中对同样的业务逻辑进行两次编程:一次为批量计算的ETL系统,一次为流式计算的Streaming系统。针对同一个业务问题产生了两个代码库,各有不同的漏洞。
数据仓库的设计不合理,会产生大量的中间结果表,造成数据急速膨胀,加大服务器存储压力。比如我们经常纠结于数据仓库到底怎么分层,是直接ODS层到应用呢?还是ODS层要景观DWS、DW等,最后才到应用呢?
Lambda架构虽然有缺点,但是在很多公司依然适用,有时候我们没有那么大的业务量,实时业务需求并没有那么明显,用着Lambda架构依然很爽。对于超大数据量的业务或者实时业务同样多的情况,可以探索改良Lambda,业内也提出了Kappa架构,感兴趣的小伙伴可以搜索学习下。
推荐阅读
如何从0到1搭建大数据平台
用 Django 开发一个 Python Web API
高性能 Pandas 方法:query 和 eval


社区会员
点赞鼓励一下













 京公网安备 11010802041100号
京公网安备 11010802041100号