点击左上方蓝字关注我们


Transformer架构早已在自然语言处理任务中得到广泛应用,如GPT, BERT等。同时,计算机视觉领域也开始涌现越来越多基于Transformer的预训练模型。下文将详细介绍Transformer中的Attention机制和Encoder-Decoder结构,以及Transformer在视觉领域的应用模型Vision Transformer,最后通过百度自研发的Paddle框架进行代码复现。
Attention Mechanism
(注意力机制)
注意力机制(Attention Mechanism)是机器学习中的一种数据处理方法,广泛应用在自然语言处理、图像识别及语音识别等各种不同类型的机器学习任务中。
Google 2017年论文中,Attention Is All You Need曾经为Attention做了一个抽象定义:
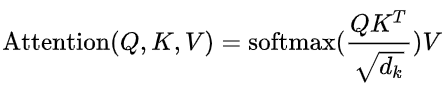
注意力是将一个查询(Query)和键值(Key,Value)对映射到输出的方法。公式中的Q、K、V均为矩阵向量,通过计算Q和K的相似性或者相关性,得到每个K对应V的权重系数,然后对V进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是V进行加权求和,而Q和K用来计算对应V的权重系数。
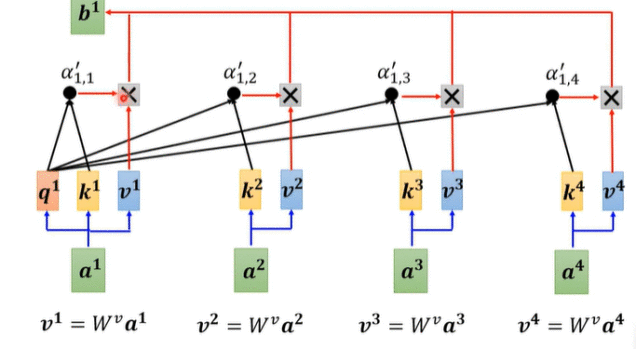
1.1 Self Attention(自注意力机制)
输入a1对应的输出b1是由序列a1至a4经线性变换(乘Wq、Wk、Wv矩阵)后的v1至v4加权得到,其权重则由a1经线性变换得到的query q1与a1至a4经线性变换得到的key k1至k4计算内积并进行softmax归一化得到。因此,a1与输入序列a1至a4的相关程度决定了b1的主要信息来源。
1.2 Multi-head Attention(多头注意力机制)
Multi-head Attention同Self Attention类似,做线性变换得到qi、ki、vi,在qi、ki、vi的基础再进行一次线性变换(乘Wq1、Wq2、Wk1、Wk2、Wv1、Wv2矩阵)得到qi.1、qi.2、qk.1、qk.2、qv.1、qv.2,如下图以2头注意力机制为例,计算方式与Self Attention相同。
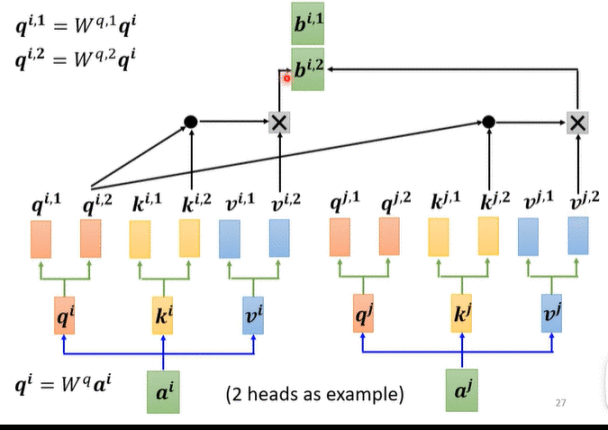
Multi-head Attention 是在Self Attention的基础上实现了类似feature map的功能,即对输入序列a1至a4经线性变换后的q1至q4, k1至k4, v1至v4在embedding维度上进行分组,每组各自进行self-attention, 最后把各组输出再组合还原为原来的embedding 维度。因此通常要求embedding的维度大小要能被head的数目进行整除以实现分组。
Encoder-Decoder
(编码器-解码器)
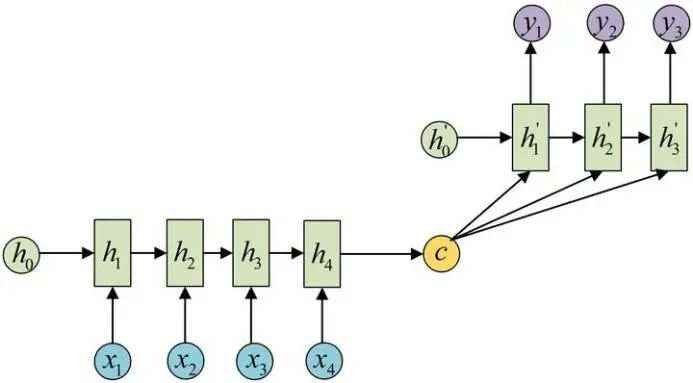
原始RNN只能处理(1)输入是序列,输出是单独值(N->1);(2)输入是N维序列,输出也是N维序列(N->N)。然而我们遇到的大部分问题序列都是不等长的:输入是N维序列,输出是M维序列(N->M)。如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
Encoder-Decoder结构先将输入数据编码成一个上下文向量c:得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。将c当做每一步的输入,结构如下图。由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛。
Transformer
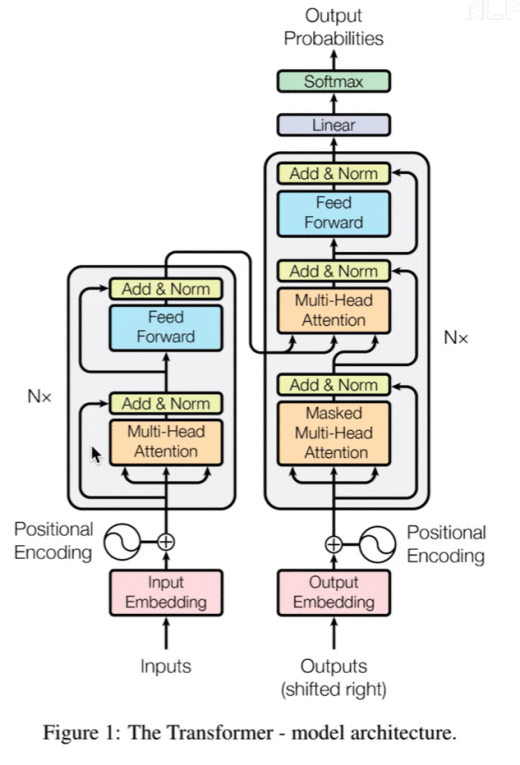
3.1 Encoder
分为3个部分:
输入部分:Embedding+位置嵌入
Attention Mechanism:上述已说明,此处应用的是Multi-head Attention(多头注意力机制)
FFN(Feed Forward Neural Network):上一步获得的Attention值会送到encoder的FFN模块。FFN是由两层Dense(全连接层)构成,采用ReLU作为激活函数。
3.2 Decoder
mask操作,是对当前单词和之后的单词做mask操作(NLP中的操作)因为是预测后面的词,所以不能让网络看见后面的词
进入Decoder的两条数据,是由Encoder产生的k、v,Decoder只提供q。
Vision Transformer
(ViT)
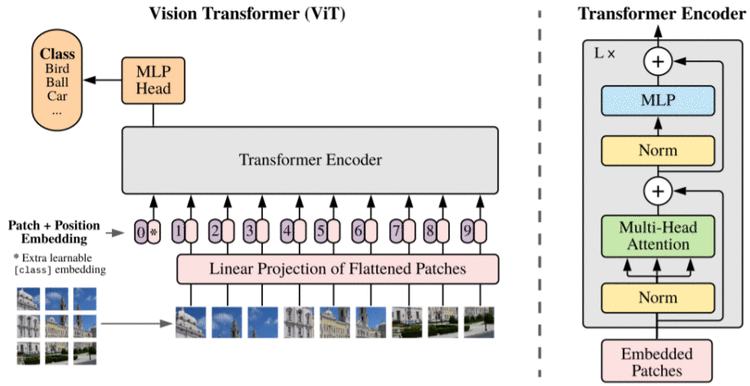
ViT是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。操作步骤如下:
图片分块,展开,做线性变换(形成与时间序列一致的输入)
在块序列首位置添加虚拟开始块,用作后续的图像分类特征
使用Transformer-Encoder进行块编码(ViT未使用Decoder结构)
虚拟块表示作为分类向量,通过MLP进行分类
项目开发框架-飞桨
(PaddlePaddle)
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。本项目在Paddle2.1框架基础上搭建模型Vision Transformer,实现车辆分类的功能。
图像特征处理
将图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。
# 获取图像特征def forward_features(self, x):B = x.shape[0] # Image Patch Embeddingx = self.patch_embed(x) # 分类 tokenscls_tokens = self.cls_token.expand((B, -1, -1)) # 拼接 Embedding 和 分类 tokensx = paddle.concat((cls_tokens, x), axis=1) # 加入位置嵌入 Position Embeddingx = x + self.pos_embed # Embedding Dropoutx = self.pos_drop(x)# Transformer Encoder# 由多个基础模块组成for blk in self.blocks:x = blk(x) # Normx = self.norm(x) # 提取分类 tokens 的输出return x[:, 0]def forward(self, x):x = paddle.reshape(x, shape=[-1, 3,120,120])# 获取图像特征x = self.forward_features(x) # 图像分类 x = self.head(x) return x
模型搭建
使用Paddle2.1框架API对模型进行组网操作,搭建模型Vision Transformer。(由于篇幅有限,只给出主干代码,详情请查看文章结尾给出的项目链接)
class VisionTransformer(nn.Layer):def __init__(self, img_size=120, patch_size=patch_size, in_chans=3, class_dim=train_parameters['class_dim'], embed_dim=dim, depth=num_layers,num_heads=heads, mlp_ratio=4, qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,drop_path_rate=0., norm_layer='nn.LayerNorm', epsilon=1e-5, **args):super().__init__()self.class_dim = class_dim # 分类数self.num_features = self.embed_dim = embed_dim # 线性变换后输出张量的尺寸# 调用之前定义PatchEmbed函数,此函数的操作:# 保证图像一定能够完整切块,获取图像切块的个数self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)num_patches = self.patch_embed.num_patchesself.pos_embed = self.create_parameter(shape=(1, num_patches + 1, embed_dim), default_initializer=zeros_) # 位置编码self.add_parameter("pos_embed", self.pos_embed)self.cls_token = self.create_parameter( # 分类令牌,可训练shape=(1, 1, embed_dim), default_initializer=zeros_)self.add_parameter("cls_token", self.cls_token)self.pos_drop = nn.Dropout(p=drop_rate) dpr = [x for x in paddle.linspace(0, drop_path_rate, depth)]# 调用Block函数,此函数为Block类实现Transformer encoder的一个层self.blocks = nn.LayerList([Block( dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, epsilon=epsilon)for i in range(depth)])self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon)# Classifier headself.head = nn.Linear(embed_dim, class_dim) if class_dim > 0 else Identity()trunc_normal_(self.pos_embed)trunc_normal_(self.cls_token)self.apply(self._init_weights)
训练效果
将模型在训练集上的效果进行可视化输出

小结
使用飞桨API快速搭建Vision Transformer深度学习模型,实现了车辆分类的功能,实现从理论到实践的跨越。同时飞桨还包含丰富的开发套件,比如PaddleClas用于图像分类、PaddleDetectiion用于目标检测、PaddleSeg用于图像分割、PaddleOCR用于文字提取等等,套件中开源了众多模型框架,为开发者开发提供了便利。最后,欢迎各位开发者一起构建飞桨开源社区,共同进步。
上述项目已开源在aistudio:
https://aistudio.baidu.com/aistudio/projectdetail/2025419
如有飞桨相关技术有问题,欢迎在飞桨论坛中提问交流:
http://discuss.paddlepaddle.org.cn/
欢迎加入官方QQ群获取最新活动资讯:793866180。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END






 京公网安备 11010802041100号
京公网安备 11010802041100号